

2026년 머신러닝 데이터 전처리 완벽 가이드
머신러닝 모델의 성능은 데이터의 품질에 달려있습니다. 이 가이드에서는 2026년 기준 최신 데이터 전처리 기법들을 파이썬 예제와 함께 상세히 분석합니다.
핵심 키워드: 결측치 처리, 이상치 탐지, 피처 스케일링
이 글의 순서
1 머신러닝, 데이터 전처리가 왜 중요할까요?
2 핵심 데이터 전처리 기법 완전 정복
3 전처리 과정에서 만나는 문제와 해결책
4 실전 데이터 전처리 워크플로우
5 자주 묻는 질문 (FAQ)
도입
머신러닝, 데이터 전처리가 왜 중요할까요?
안녕하세요, 권퓨터입니다! 2026년, 인공지능과 머신러닝 기술은 우리 삶의 모든 영역에 깊숙이 파고들고 있습니다. 자율주행차부터 개인화 추천 시스템, 의료 진단에 이르기까지, 머신러닝 모델의 활약은 눈부시죠. 하지만 이러한 모델들이 최고의 성능을 발휘하기 위해서는 한 가지 필수적인 과정이 선행되어야 합니다. 바로 데이터 전처리(Data Preprocessing)입니다.
흔히들 머신러닝을 “쓰레기가 들어가면 쓰레기가 나온다(Garbage In, Garbage Out)”고 말합니다. 아무리 정교하고 복잡한 모델을 사용하더라도, 입력되는 데이터의 품질이 낮다면 기대하는 성능을 얻기 어렵다는 뜻이죠. 실제 프로젝트에서 모델링에 쏟는 시간보다 데이터 전처리에 더 많은 시간을 할애하는 경우가 많습니다. 데이터 과학자들의 연구에 따르면, 전체 프로젝트 시간 중 최대 80%가 데이터 수집과 전처리 과정에 소요된다고 합니다.
“데이터 전처리는 머신러닝 모델의 숨겨진 영웅입니다. 모델이 빛을 발할 수 있도록 데이터를 다듬고 정제하는 것은 선택이 아닌 필수입니다.”
— 권퓨터의 데이터 분석 인사이트
이 글에서는 머신러닝 모델의 성능을 획기적으로 향상시킬 수 있는 핵심 데이터 전처리 기법들을 2026년 최신 트렌드에 맞춰 상세히 다룰 예정입니다. 결측치 처리, 이상치 탐지, 피처 스케일링 등 기본적인 기법부터, 실전에서 마주할 수 있는 문제 해결 전략까지 파이썬 예제와 함께 자세히 알아보겠습니다. 데이터 전처리의 중요성을 이해하고, 실제 프로젝트에 적용할 수 있는 실질적인 지식을 얻어가시길 바랍니다!
핵심 분석
핵심 데이터 전처리 기법 완전 정복
이제 본격적으로 머신러닝 모델의 성능을 좌우하는 핵심 전처리 기법들을 하나씩 파헤쳐 볼 시간입니다. 각 기법의 개념과 필요성, 그리고 파이썬을 활용한 구체적인 구현 예시까지 함께 살펴보겠습니다.
1. 결측치 처리 (Missing Value Imputation)
데이터셋에 값이 누락된 경우를 결측치(Missing Value)라고 합니다. 이 결측치는 데이터 수집 과정의 오류, 측정 실패, 사용자 입력 누락 등 다양한 원인으로 발생할 수 있습니다. 대부분의 머신러닝 알고리즘은 결측치를 직접 처리할 수 없으므로, 모델 학습 전에 반드시 적절한 방법으로 처리해야 합니다.
결측치는 크게 세 가지 유형으로 분류할 수 있습니다:
- 완전 무작위 결측(MCAR, Missing Completely At Random): 결측값이 다른 어떤 변수와도 관련이 없습니다. 가장 이상적인 경우입니다.
- 무작위 결측(MAR, Missing At Random): 결측값이 다른 관측된 변수와 관련이 있지만, 결측값 자체와는 관련이 없습니다. 예를 들어, 남성이 여성보다 특정 질문에 응답하지 않을 확률이 높은 경우입니다.
- 비무작위 결측(MNAR, Missing Not At Random): 결측값이 결측값 자체와 관련이 있습니다. 예를 들어, 고소득층이 소득 정보를 공개하기 꺼려 결측이 발생하는 경우입니다.
결측치 처리 전략
결측치 처리 방법은 크게 두 가지로 나눌 수 있습니다: 삭제(Deletion)와 대체(Imputation).
- 삭제 (Deletion):
- 행/열 삭제 (Listwise/Casewise Deletion): 결측치가 있는 행 또는 열 전체를 삭제합니다. 데이터 손실이 크거나 편향이 발생할 수 있어 신중해야 합니다. 데이터의 5% 미만의 결측치에서 고려할 수 있습니다.
- 쌍별 삭제 (Pairwise Deletion): 특정 분석에 필요한 데이터만 사용하여 결측치를 무시합니다. 이는 편향을 유발할 수 있습니다.
- 대체 (Imputation):
- 평균/중앙값/최빈값 대체: 수치형 데이터는 평균이나 중앙값으로, 범주형 데이터는 최빈값으로 대체합니다. 구현이 간단하지만 데이터의 분산이 왜곡될 수 있습니다.
- 선형 보간 (Linear Interpolation): 시계열 데이터와 같이 순서가 있는 데이터에 효과적입니다. 앞뒤 데이터의 값을 이용해 선형적으로 보간합니다.
- 예측 모델 대체: 결측치가 없는 다른 변수들을 이용하여 결측치를 예측하는 모델을 만듭니다 (예: KNN Imputer, MICE). 가장 정교한 방법 중 하나이지만, 계산 비용이 높습니다.
다음은 파이썬 pandas를 이용한 결측치 처리 예시입니다.
import pandas as pd
import numpy as np
# 예시 데이터프레임 생성
data = {
'Feature1': [10, 20, np.nan, 40, 50],
'Feature2': [100, np.nan, 300, 400, 500],
'Feature3': [True, False, True, np.nan, False],
'Feature4': ['A', 'B', 'C', 'D', np.nan]
}
df = pd.DataFrame(data)
print("원본 데이터프레임:")
print(df)
print("\n결측치 확인:")
print(df.isnull().sum())
# 1. 평균(Mean)으로 결측치 대체 (수치형 데이터)
df_mean_filled = df.copy()
df_mean_filled['Feature1'] = df_mean_filled['Feature1'].fillna(df_mean_filled['Feature1'].mean())
df_mean_filled['Feature2'] = df_mean_filled['Feature2'].fillna(df_mean_filled['Feature2'].mean())
print("\n평균 대체 후 데이터프레임:")
print(df_mean_filled)
# 2. 중앙값(Median)으로 결측치 대체 (수치형 데이터)
df_median_filled = df.copy()
df_median_filled['Feature1'] = df_median_filled['Feature1'].fillna(df_median_filled['Feature1'].median())
df_median_filled['Feature2'] = df_median_filled['Feature2'].fillna(df_median_filled['Feature2'].median())
print("\n중앙값 대체 후 데이터프레임:")
print(df_median_filled)
# 3. 최빈값(Mode)으로 결측치 대체 (범주형 데이터)
df_mode_filled = df.copy()
for col in ['Feature3', 'Feature4']:
df_mode_filled[col] = df_mode_filled[col].fillna(df_mode_filled[col].mode()[0])
print("\n최빈값 대체 후 데이터프레임:")
print(df_mode_filled)
# 4. 결측치가 있는 행 삭제 (dropna)
df_dropped = df.dropna()
print("\n결측치 행 삭제 후 데이터프레임:")
print(df_dropped)
# 5. KNN Imputer 사용 예시 (scikit-learn)
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=2) # 가장 가까운 2개의 이웃을 사용하여 대체
df_knn_imputed = df.copy()
# KNNImputer는 수치형 데이터에만 적용 가능하므로, 수치형 컬럼만 선택
numeric_cols = df_knn_imputed.select_dtypes(include=np.number).columns
df_knn_imputed[numeric_cols] = imputer.fit_transform(df_knn_imputed[numeric_cols])
print("\nKNN Imputer로 수치형 결측치 대체 후 데이터프레임:")
print(df_knn_imputed)
핵심 포인트
결측치 처리 방법은 데이터의 특성, 결측치 유형, 그리고 분석 목표에 따라 신중하게 선택해야 합니다. 무작정 삭제하거나 단순 대체하는 것은 모델의 성능을 저하시킬 수 있습니다. 특히 MNAR 유형의 결측치는 모델에 편향을 줄 수 있으므로 탐색적 데이터 분석(EDA)을 통해 결측치의 패턴을 파악하는 것이 중요합니다.
2. 이상치 탐지 및 처리 (Outlier Detection & Handling)
이상치(Outlier)는 대부분의 데이터와는 현저히 다른 값을 가지는 데이터 포인트입니다. 이는 측정 오류, 데이터 입력 실수, 또는 실제 현상의 특이한 사례일 수 있습니다. 이상치는 회귀 모델의 계수, 분류 모델의 결정 경계 등 머신러닝 모델의 학습 결과에 큰 영향을 미칠 수 있으므로 정확한 탐지 및 처리가 중요합니다.
이상치는 크게 두 가지 유형으로 분류할 수 있습니다:
- 단변량 이상치 (Univariate Outliers): 단일 변수 내에서 비정상적으로 크거나 작은 값입니다. 박스 플롯(Box Plot) 등으로 쉽게 시각화하고 탐지할 수 있습니다.
- 다변량 이상치 (Multivariate Outliers): 여러 변수를 함께 고려했을 때 비정상적인 데이터 포인트입니다. 예를 들어, 나이와 소득 변수를 각각 보면 정상 범위이지만, 10대인데 소득이 1억인 경우는 다변량 이상치일 수 있습니다.
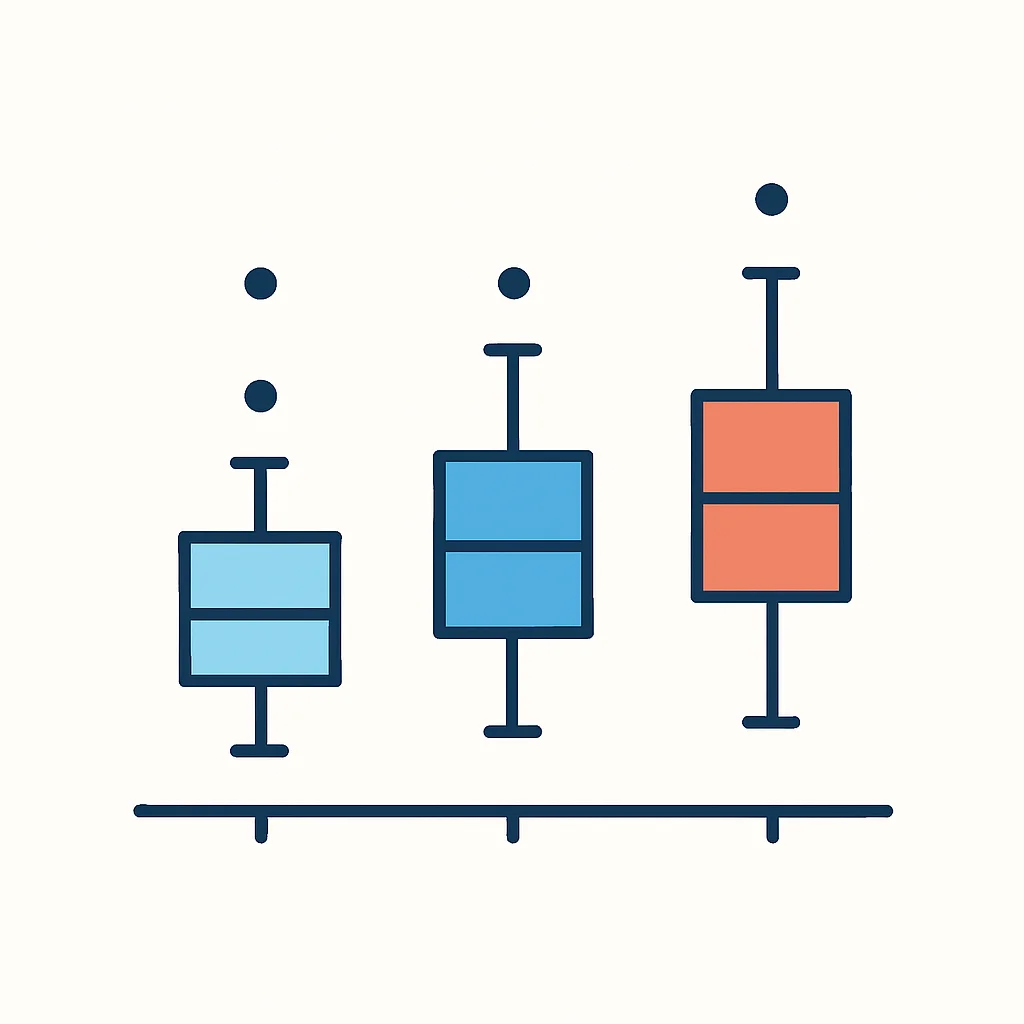
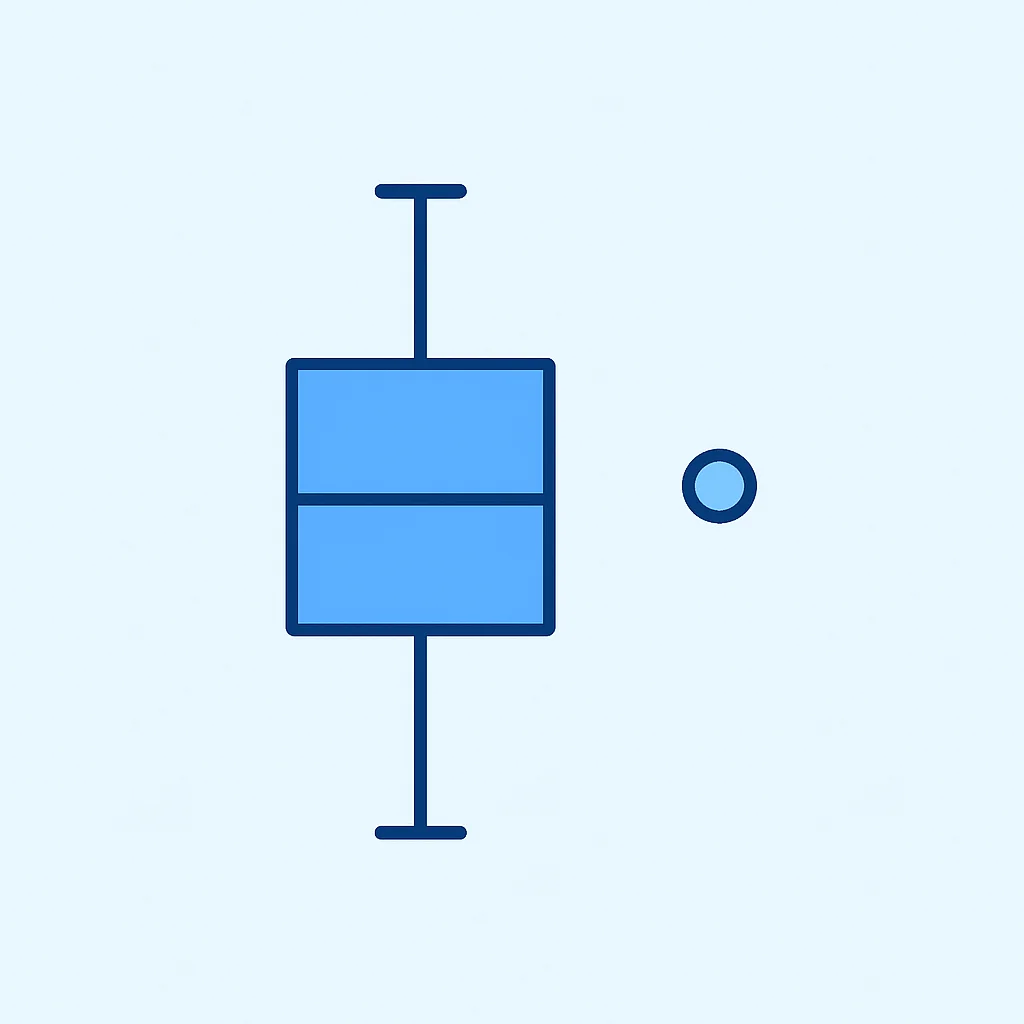
이상치 탐지 방법
- Z-score: 데이터가 정규 분포를 따른다고 가정하고, 평균에서 얼마나 떨어져 있는지를 표준편차 단위로 측정합니다. 일반적으로 Z-score가 2 또는 3 이상인 경우 이상치로 간주합니다.
- IQR (Interquartile Range): 데이터의 사분위수를 활용합니다. Q1(1사분위수)보다 Q1 – 1.5 IQR보다 작거나, Q3(3사분위수)보다 Q3 + 1.5 IQR보다 큰 경우 이상치로 간주합니다. 정규 분포를 가정하지 않아도 되므로 더 robust한 방법입니다.
- 시각화: 박스 플롯, 히스토그램, 산점도 등을 통해 시각적으로 이상치를 식별합니다. 다변량 이상치는 산점도 행렬(Scatter Plot Matrix)이나 3D 플롯을 활용할 수 있습니다.
- 모델 기반 방법: Isolation Forest, One-Class SVM, LOF(Local Outlier Factor)와 같은 비지도 학습 모델을 사용하여 이상치를 탐지합니다. 복잡한 데이터 패턴에서도 이상치를 잘 찾아냅니다.
이상치 처리 전략
- 삭제 (Deletion): 이상치 데이터 포인트를 제거합니다. 데이터의 양이 충분하고 이상치가 명확한 오류일 경우 효과적입니다.
- 변환 (Transformation): 로그 변환, 제곱근 변환 등을 통해 데이터의 분포를 정규화하여 이상치의 영향을 줄입니다. 특히 왜곡된 분포를 가진 데이터에 유용합니다.
- 대체 (Capping/Imputation): 이상치를 특정 상한/하한 값으로 대체합니다. 예를 들어, IQR 방법에서 이상치로 판단된 값을 Q1 – 1.5 IQR 또는 Q3 + 1.5 IQR 값으로 대체할 수 있습니다.
다음은 파이썬을 이용한 Z-score 및 IQR 기반 이상치 탐지 및 처리 예시입니다.
import pandas as pd
import numpy as np
from scipy import stats
# 예시 데이터 생성
np.random.seed(42)
data = np.random.normal(loc=50, scale=10, size=100) # 평균 50, 표준편차 10인 정규분포 데이터
data = np.append(data, [0, 100, 150]) # 이상치 추가
df = pd.DataFrame({'Value': data})
print("원본 데이터 통계량:")
print(df.describe())
# 1. Z-score 기반 이상치 탐지 및 처리
z_scores = np.abs(stats.zscore(df['Value']))
threshold_z = 3 # Z-score 3 이상을 이상치로 간주
outliers_z = df[z_scores > threshold_z]
print(f"\nZ-score > {threshold_z} 인 이상치:")
print(outliers_z)
# Z-score 기반 이상치 대체 (예: 평균으로 대체)
df_z_imputed = df.copy()
df_z_imputed.loc[z_scores > threshold_z, 'Value'] = df_z_imputed['Value'].mean()
print("\nZ-score 기반 이상치 대체 후 통계량:")
print(df_z_imputed.describe())
# 2. IQR 기반 이상치 탐지 및 처리
Q1 = df['Value'].quantile(0.25)
Q3 = df['Value'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR;
outliers_iqr = df[(df['Value'] < lower_bound) | (df['Value'] > upper_bound)]
print(f"\nIQR 기반 이상치 (하한: {lower_bound:.2f}, 상한: {upper_bound:.2f}):")
print(outliers_iqr)
# IQR 기반 이상치 대체 (Capping: 상한/하한 값으로 대체)
df_iqr_capped = df.copy()
df_iqr_capped.loc[df_iqr_capped['Value'] < lower_bound, 'Value'] = lower_bound
df_iqr_capped.loc[df_iqr_capped['Value'] > upper_bound, 'Value'] = upper_bound
print("\nIQR 기반 이상치 대체 후 통계량:")
print(df_iqr_capped.describe())
핵심 포인트
이상치는 단순한 데이터 오류가 아닐 수 있습니다. 때로는 비즈니스에 중요한 인사이트를 제공하는 ‘특이점’일 수도 있으니, 무작정 제거하기보다는 그 의미를 탐색하는 자세가 필요합니다.
3. 피처 스케일링 (Feature Scaling)
데이터셋의 각 피처(특성)는 측정 단위나 범위가 다를 수 있습니다. 예를 들어, ‘나이’는 0-100 범위인 반면, ‘수입’은 수천에서 수억까지 다양할 수 있습니다. 피처 스케일링(Feature Scaling)은 이러한 피처들의 스케일을 통일하여 모델이 특정 피처에 편향되지 않고 공정하게 학습할 수 있도록 돕는 과정입니다.
피처 스케일링이 필요한 주요 이유는 다음과 같습니다:
- 거리 기반 알고리즘: KNN, SVM, K-Means 등 거리 기반 알고리즘은 피처 간의 거리를 계산하여 유사도를 판단합니다. 스케일이 큰 피처가 거리에 더 큰 영향을 미치므로, 스케일링을 통해 모든 피처가 공정하게 기여하도록 합니다.
- 경사 하강법 기반 알고리즘: 선형 회귀, 로지스틱 회귀, 신경망 등 경사 하강법을 사용하는 모델은 스케일링이 되지 않은 데이터에서 최적점을 찾는 데 더 많은 시간과 노력이 필요할 수 있습니다. 스케일링은 수렴 속도를 높이고 안정적인 학습을 돕습니다.
- 정규화/표준화: 데이터의 분포를 특정 형태로 변환하여 모델이 더 효율적으로 학습할 수 있도록 합니다.
주요 피처 스케일링 방법
- Min-Max Scaling (정규화, Normalization): 데이터를 0과 1 사이의 값으로 변환합니다.
X_scaled = (X - X_min) / (X_max - X_min)이상치에 매우 민감하여 이상치가 있으면 값들이 한쪽으로 쏠릴 수 있습니다.
- Standard Scaling (표준화, Standardization): 데이터를 평균 0, 표준편차 1인 표준 정규 분포 형태로 변환합니다.
X_scaled = (X - X_mean) / X_std이상치에 덜 민감하며, 대부분의 머신러닝 모델에 좋은 성능을 보입니다.
- Robust Scaling: 중앙값(Median)과 IQR을 사용하여 스케일링합니다.
X_scaled = (X - X_median) / IQR이상치에 가장 강건(robust)합니다. 데이터에 이상치가 많을 때 유용합니다.
다음은 파이썬 scikit-learn을 이용한 피처 스케일링 예시입니다.
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler
# 예시 데이터 생성 (나이, 월수입)
data = {
'Age': [25, 30, 35, 40, 60, 22, 55, 28, 33, 48],
'Monthly_Income': [300, 400, 500, 600, 1500, 250, 1000, 350, 450, 800]
}
df = pd.DataFrame(data)
print("원본 데이터프레임:")
print(df)
print("\n원본 데이터 통계량:")
print(df.describe())
# 1. Min-Max Scaling
min_max_scaler = MinMaxScaler()
df_min_max_scaled = pd.DataFrame(min_max_scaler.fit_transform(df), columns=df.columns)
print("\nMin-Max Scaling 후 데이터프레임:")
print(df_min_max_scaled)
print("\nMin-Max Scaling 후 통계량:")
print(df_min_max_scaled.describe())
# 2. Standard Scaling
standard_scaler = StandardScaler()
df_standard_scaled = pd.DataFrame(standard_scaler.fit_transform(df), columns=df.columns)
print("\nStandard Scaling 후 데이터프레임:")
print(df_standard_scaled)
print("\nStandard Scaling 후 통계량:")
print(df_standard_scaled.describe())
# 3. Robust Scaling
robust_scaler = RobustScaler()
df_robust_scaled = pd.DataFrame(robust_scaler.fit_transform(df), columns=df.columns)
print("\nRobust Scaling 후 데이터프레임:")
print(df_robust_scaled)
print("\nRobust Scaling 후 통계량:")
print(df_robust_scaled.describe())
핵심 포인트
어떤 스케일링 방법을 선택할지는 모델과 데이터의 분포에 따라 달라집니다. 이상치에 민감한 Min-Max Scaling은 이상치가 없는 데이터에 적합하며, 이상치에 덜 민감한 Standard Scaling은 가장 보편적으로 사용됩니다. 이상치가 많은 경우에는 Robust Scaling이 더 좋은 선택이 될 수 있습니다.
4. 범주형 데이터 인코딩 (Categorical Data Encoding)
머신러닝 모델은 숫자 데이터를 기반으로 작동합니다. 따라서 ‘성별’, ‘도시’, ‘요일’과 같은 텍스트 형태의 범주형 데이터(Categorical Data)는 모델에 입력하기 전에 숫자 형태로 변환해야 합니다. 이 과정을 인코딩(Encoding)이라고 합니다.
주요 범주형 인코딩 방법
- Label Encoding: 각 범주에 고유한 정수 값을 할당합니다 (예: ‘서울’ -> 0, ‘부산’ -> 1, ‘대구’ -> 2). 범주 간에 순서(순서형 변수)가 있는 경우에 적합합니다. 순서가 없는 범주형 변수에 사용하면 모델이 잘못된 순서 관계를 학습할 수 있습니다.
- One-Hot Encoding: 각 범주를 새로운 이진(0 또는 1) 피처로 변환합니다. 예를 들어, ‘도시’ 피처에 ‘서울’, ‘부산’, ‘대구’가 있다면, ‘도시_서울’, ‘도시_부산’, ‘도시_대구’라는 세 개의 새로운 피처를 만들고 해당 도시에만 1을 부여합니다. 범주 간 순서 관계가 없을 때 가장 널리 사용됩니다.
- Target Encoding: 각 범주를 해당 범주의 타겟 변수 평균값으로 대체합니다. 예를 들어, ‘도시’별 구매율이 타겟 변수라면 ‘서울’을 서울의 평균 구매율로 대체합니다. 정보 손실이 적고 성능이 좋지만, 과적합(overfitting)의 위험이 있습니다.
다음은 파이썬 scikit-learn과 pandas를 이용한 범주형 데이터 인코딩 예시입니다.
import pandas as pd
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
# 예시 데이터프레임 생성
data = {
'City': ['Seoul', 'Busan', 'Seoul', 'Daegu', 'Busan'],
'Grade': ['A', 'B', 'A', 'C', 'B'] # 순서가 있는 범주형 (A > B > C)
}
df = pd.DataFrame(data)
print("원본 데이터프레임:")
print(df)
# 1. Label Encoding (순서형 변수에 적합)
label_encoder = LabelEncoder()
df_label_encoded = df.copy()
df_label_encoded['Grade_Encoded'] = label_encoder.fit_transform(df_label_encoded['Grade'])
print("\nLabel Encoding 후 (Grade):")
print(df_label_encoded[['Grade', 'Grade_Encoded']])
# 2. One-Hot Encoding (명목형 변수에 적합)
# pandas get_dummies 사용
df_one_hot_encoded_pd = pd.get_dummies(df, columns=['City'], prefix='City')
print("\nOne-Hot Encoding 후 (City - pandas get_dummies):")
print(df_one_hot_encoded_pd)
# scikit-learn OneHotEncoder 사용
one_hot_encoder = OneHotEncoder(sparse_output=False) # sparse_output=False로 dense array 반환
city_encoded = one_hot_encoder.fit_transform(df[['City']])
city_df = pd.DataFrame(city_encoded, columns=one_hot_encoder.get_feature_names_out(['City']))
df_one_hot_encoded_sk = pd.concat([df.drop('City', axis=1), city_df], axis=1)
print("\nOne-Hot Encoding 후 (City - scikit-learn OneHotEncoder):")
print(df_one_hot_encoded_sk)
활용 사례: 이커머스 고객 데이터
이커머스에서 고객의 ‘선호 브랜드’ (명목형)는 One-Hot Encoding으로, ‘회원 등급’ (순서형)은 Label Encoding으로 변환하여 구매 예측 모델에 활용할 수 있습니다. 각 인코딩 방식의 적절한 적용은 모델의 예측 정확도를 크게 향상시킬 수 있습니다.
문제 해결
전처리 과정에서 만나는 문제와 해결책
데이터 전처리는 단순히 기술적인 적용을 넘어, 여러 가지 복잡한 문제와 씨름해야 하는 과정입니다. 특히 데이터 누수(Data Leakage)는 모델 성능을 과대평가하게 만들어 실제 서비스 환경에서 실망스러운 결과를 초래할 수 있는 심각한 문제입니다.
데이터 누수는 모델이 훈련 데이터에 포함된 테스트 데이터의 정보를 “엿듣는” 현상입니다. 이는 모델의 성능 지표를 비현실적으로 높여 실제 배포 시 낮은 성능으로 이어집니다. 예를 들어, 전체 데이터셋에 대해 스케일링을 먼저 진행한 후 훈련/테스트 셋을 분리하면, 훈련 데이터가 테스트 데이터의 통계량(평균, 표준편차 등)을 알게 되어 누수가 발생합니다.
해결 — 훈련/테스트 데이터 분리 후 전처리 적용 & 파이프라인 활용
가장 중요한 원칙은 훈련 데이터만으로 전처리 통계량(평균, 표준편차, 최솟값, 최댓값 등)을 계산하고, 이 통계량을 테스트 데이터와 새로운 데이터에 동일하게 적용하는 것입니다. scikit-learn의 Pipeline을 사용하면 이 과정을 자동화하고 누수를 방지할 수 있습니다.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score
import pandas as pd
import numpy as np
# 예시 데이터 생성
np.random.seed(42)
X = np.random.rand(100, 5) * 100 # 5개 피처, 100개 샘플
y = np.random.randint(0, 2, 100) # 이진 분류 타겟
# 훈련 데이터와 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 파이프라인 구성: 스케일러 -> 모델
pipeline = Pipeline([
('scaler', StandardScaler()), # 훈련 데이터로 fit하고 transform
('classifier', LogisticRegression()) # 스케일링된 데이터로 학습
])
# 파이프라인 학습
pipeline.fit(X_train, y_train)
# 테스트 데이터 예측 (자동으로 스케일링 및 예측 수행)
y_pred = pipeline.predict(X_test)
print(f"모델 정확도: {accuracy_score(y_test, y_pred):.4f}")
# 잘못된 전처리 (데이터 누수 발생) 예시
# scaler = StandardScaler()
# X_scaled = scaler.fit_transform(X) # 전체 데이터에 스케일링 (누수 발생)
# X_train_leak, X_test_leak, y_train_leak, y_test_leak = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# model_leak = LogisticRegression()
# model_leak.fit(X_train_leak, y_train_leak)
# y_pred_leak = model_leak.predict(X_test_leak)
# print(f"누수 발생 모델 정확도: {accuracy_score(y_test_leak, y_pred_leak):.4f}") # 종종 더 높게 나옴
데이터 누수는 모델 개발 초기 단계에서 발견하기 어렵고, 실제 서비스에서 치명적인 결과를 초래할 수 있습니다. 항상 훈련 데이터를 기준으로 전처리 통계량을 계산하고, 파이프라인을 적극 활용하여 누수를 방지해야 합니다. 교차 검증(Cross-validation) 시에도 각 폴드(fold) 내에서 전처리가 이루어지도록 주의해야 합니다.
실전 적용
실전 데이터 전처리 워크플로우
지금까지 다양한 전처리 기법들을 살펴보았습니다. 실제 프로젝트에서는 이러한 기법들을 어떻게 체계적으로 적용해야 할까요? 일반적인 데이터 전처리 워크플로우를 단계별로 제안합니다.
1
탐색적 데이터 분석 (EDA)
데이터의 전반적인 특성(분포, 통계량, 변수 간 관계)을 시각화하고 이해하는 단계입니다. 결측치, 이상치, 범주형 변수의 종류 등을 파악하여 어떤 전처리 기법이 필요한지 전략을 세웁니다.
2
결측치 처리
EDA를 통해 파악한 결측치 유형과 양에 따라 적절한 대체 또는 삭제 방법을 선택합니다. 데이터 손실을 최소화하면서도 모델 성능에 부정적인 영향을 주지 않는 방법을 우선적으로 고려합니다.
3
이상치 탐지 및 처리
Z-score, IQR, 시각화 등 다양한 방법을 활용하여 이상치를 식별합니다. 이상치의 원인을 분석하고, 데이터의 특성에 따라 삭제, 변환, 또는 대체 방법을 적용합니다.
4
피처 스케일링 및 인코딩
수치형 피처는 Min-Max Scaling, Standard Scaling, Robust Scaling 중 적절한 방법을 선택하여 스케일을 맞춥니다. 범주형 피처는 Label Encoding 또는 One-Hot Encoding을 통해 숫자 형태로 변환합니다.
5
피처 엔지니어링 (Feature Engineering)
기존 피처를 조합하거나 변환하여 새로운 피처를 생성하는 과정입니다. 도메인 지식을 활용하여 모델의 예측력을 높일 수 있는 강력한 피처를 발굴하는 것이 중요합니다. (예: 날짜에서 요일, 월 추출; 두 변수의 비율 계산 등)

핵심 포인트
이 워크플로우는 반복적이고 유동적입니다. 한 단계를 거친 후에도 다시 EDA로 돌아가 데이터를 재확인하고, 모델 학습 후 성능이 만족스럽지 않다면 다시 전처리 단계로 돌아와 다른 기법을 시도하는 것이 일반적입니다. 끊임없는 실험과 개선이 필요합니다.
추가 고려사항
2026년 데이터 전처리 트렌드: 자동화와 고급 기법
2026년 현재, 데이터 전처리 분야에서도 새로운 트렌드가 등장하고 있습니다. 대규모 데이터와 복잡한 모델을 다루는 환경에서 전처리 과정을 효율화하고 최적화하기 위한 노력들이 이어지고 있습니다.
AutoML과 전처리 자동화
AutoML(Automated Machine Learning) 플랫폼은 데이터 전처리, 피처 엔지니어링, 모델 선택, 하이퍼파라미터 튜닝 등 머신러닝 워크플로우의 여러 단계를 자동화하는 기술입니다. Google Cloud AutoML, H2O.ai, DataRobot 등 상용 솔루션들이 활발히 사용되고 있으며, 데이터 과학자의 생산성을 크게 높여주고 있습니다. 이들은 데이터 유형에 따라 최적의 전처리 기법을 자동으로 탐색하고 적용하는 기능을 제공하기도 합니다.
물론 AutoML이 모든 것을 해결해 주지는 않습니다. 여전히 도메인 지식과 전문가의 판단이 필요한 부분이 많지만, 반복적이고 시간이 많이 소요되는 전처리 작업의 부담을 줄여주는 강력한 도구로 자리매김하고 있습니다.
데이터 불균형 처리 (Imbalanced Data Handling)
이상 거래 탐지, 질병 진단 등 실제 문제에서는 특정 클래스의 데이터가 다른 클래스에 비해 현저히 적은 데이터 불균형(Imbalanced Data) 문제가 흔히 발생합니다. 이러한 경우 모델이 다수 클래스에 편향되어 소수 클래스를 제대로 예측하지 못하는 문제가 생깁니다.
주요 해결책은 다음과 같습니다:
- 오버샘플링 (Oversampling): 소수 클래스의 데이터를 복제하거나, 새로운 데이터를 생성하여 다수 클래스와 균형을 맞춥니다. 가장 대표적인 기법은 SMOTE(Synthetic Minority Over-sampling Technique)로, 소수 클래스 주변에 새로운 합성 데이터를 생성합니다.
- 언더샘플링 (Undersampling): 다수 클래스의 데이터를 줄여 소수 클래스와 균형을 맞춥니다. 데이터 손실이 발생할 수 있어 신중해야 합니다.
- 앙상블 기법: 불균형 데이터에 특화된 앙상블 모델(예: EasyEnsemble, BalanceCascade)을 사용합니다.
이러한 고급 전처리 기법들은 특히 복잡하고 현실적인 문제 해결에 필수적인 요소로 자리 잡고 있습니다.
FAQ
자주 묻는 질문 (FAQ)
Q. 데이터 전처리를 건너뛰면 안 되나요?
A. 절대 안 됩니다. 데이터 전처리는 머신러닝 모델이 데이터를 올바르게 이해하고 학습할 수 있도록 하는 필수 과정입니다. 전처리를 건너뛰면 모델의 성능이 저하되거나, 아예 학습 자체가 불가능할 수 있습니다. “Garbage In, Garbage Out” 원칙을 기억하세요.
Q. 어떤 전처리 기법이 가장 좋나요?
A. ‘가장 좋은’ 단일 전처리 기법은 없습니다. 데이터의 특성, 결측치/이상치의 유형, 모델의 종류, 그리고 문제 해결 목표에 따라 최적의 기법은 달라집니다. 탐색적 데이터 분석(EDA)을 통해 데이터를 깊이 이해하고, 여러 기법을 실험하여 가장 좋은 조합을 찾는 것이 중요합니다.
Q. 데이터 누수(Data Leakage)를 어떻게 확실히 방지할 수 있나요?
A. 데이터 누수를 방지하는 가장 확실한 방법은 훈련 데이터와 테스트 데이터를 분리한 후, 훈련 데이터만을 사용하여 전처리 통계량을 학습하고 이를 테스트 데이터에 적용하는 것입니다. scikit-learn의 Pipeline을 사용하면 이 과정을 자동화하고 체계적으로 관리할 수 있습니다.
Q. 피처 엔지니어링도 전처리에 포함되나요?
A. 네, 피처 엔지니어링은 넓은 의미의 데이터 전처리 과정에 포함됩니다. 기존 데이터를 가공하여 모델 성능을 향상시키는 새로운 피처를 생성하는 과정으로, 도메인 지식과 창의성이 매우 중요하게 작용합니다. 이는 모델의 예측력을 높이는 핵심적인 단계입니다.
긴 글을 읽어주셔서 감사합니다!
2026년 머신러닝 시대에서 데이터 전처리는 단순한 준비 작업을 넘어, 모델의 성패를 가르는 핵심 역량으로 자리 잡았습니다. 이 가이드가 여러분의 머신러닝 프로젝트에 작은 불씨가 되기를 바랍니다.
데이터는 보석과 같습니다. 잘 다듬고 연마할수록 더욱 빛나는 가치를 발휘하죠. 권퓨터는 앞으로도 유익한 IT 정보들을 쉽고 재미있게 전달해 드릴게요. 궁금한 점이 있으면 언제든지 댓글로 남겨주세요!