

요약
[AI · 머신러닝] Stable Diffusion 시작 가이드 2026
2026년, 텍스트만으로 나만의 멋진 AI 그림을 뚝딱 만들 수 있는 Stable Diffusion의 모든 것을 알아봅니다.
핵심 키워드: Stable Diffusion, AI 그림 생성, 프롬프트 엔지니어링
이 글의 순서
1. Stable Diffusion, 왜 지금 주목해야 할까요?
2. Stable Diffusion의 작동 원리 이해하기
3. 나만의 작업 환경 구축: Automatic1111 WebUI 설치 가이드
4. AI 그림 마스터하기: 프롬프트 작성의 기술
5. Stable Diffusion의 고급 기능과 활용법
6. 자주 묻는 질문 (FAQ)
7. 마무리: AI 그림, 당신의 창작 도구가 되다
배경 / 도입
Stable Diffusion, 왜 지금 주목해야 할까요?
2026년 현재, 인공지능은 우리의 일상과 창작 활동에 깊숙이 스며들고 있습니다. 그중에서도 텍스트를 이미지로 변환하는 ‘텍스트-투-이미지(Text-to-Image)’ 기술은 예술, 디자인, 미디어 산업 전반에 혁신적인 변화를 가져왔습니다. 불과 몇 년 전만 해도 상상 속에나 존재하던 “생각만으로 그림을 그리는” 시대가 활짝 열린 것이죠.
이러한 변화의 중심에는 바로 Stable Diffusion이 있습니다. 2022년 출시 이후, Stable Diffusion은 오픈소스라는 강점을 바탕으로 전 세계 개발자와 아티스트들의 폭발적인 관심을 받으며 빠르게 발전했습니다. 끊임없이 새로운 모델과 기능이 추가되고, 사용자 커뮤니티는 방대한 지식과 노하우를 공유하며 생태계를 확장하고 있습니다.
그렇다면 2026년의 Stable Diffusion은 어떤 모습일까요? 단순히 그림을 생성하는 것을 넘어, 이제는 특정 스타일을 학습하고, 인물의 자세를 제어하며, 심지어 3D 모델링이나 애니메이션 제작까지 넘보는 수준에 이르렀습니다. 더 이상 전문가만의 전유물이 아닌, 누구나 쉽게 접근하여 창작의 즐거움을 누릴 수 있는 강력한 도구가 된 것입니다.
이 가이드에서는 Stable Diffusion을 처음 접하는 분들도 쉽게 따라 할 수 있도록, 설치부터 프롬프트 작성 꿀팁, 그리고 다양한 고급 기능까지 상세하게 다룰 예정입니다. 권퓨터와 함께 나만의 AI 그림을 뚝딱 만들어보는 여정을 시작해볼까요?
핵심 포인트
2026년 Stable Diffusion은 오픈소스 기반의 강력한 AI 이미지 생성 도구로, 텍스트-투-이미지 기술을 통해 예술, 디자인 분야에 혁신을 가져왔습니다. 누구나 쉽게 접근하여 창의적인 결과물을 만들 수 있는 잠재력을 가지고 있습니다.
핵심 내용
Stable Diffusion의 작동 원리 이해하기
Stable Diffusion을 효과적으로 사용하려면 그 작동 원리를 이해하는 것이 중요합니다. 너무 깊이 들어갈 필요는 없지만, 주요 구성 요소들이 어떤 역할을 하는지 알면 프롬프트 작성이나 설정 조절에 큰 도움이 됩니다. Stable Diffusion은 기본적으로 ‘잠재 확산 모델(Latent Diffusion Model, LDM)’이라는 기술을 기반으로 합니다.
Diffusion 모델의 기본 개념
Diffusion 모델은 마치 노이즈가 가득한 이미지에서 점차적으로 노이즈를 제거하여 깨끗한 이미지를 만들어내는 과정과 유사합니다. 크게 두 단계로 나눌 수 있습니다.
1. 확산 과정 (Forward Diffusion): 깨끗한 원본 이미지에 점진적으로 노이즈를 추가하여 완전히 무작위적인 노이즈 이미지로 만듭니다. 이 과정은 학습 데이터에 있는 모든 이미지를 노이즈로 만드는 방법을 배우는 것입니다.
2. 역확산 과정 (Reverse Diffusion): 노이즈가 가득한 이미지에서 시작하여, 학습된 모델을 이용해 점차적으로 노이즈를 제거해나가면서 깨끗하고 의미 있는 이미지를 복원합니다. 우리가 Stable Diffusion으로 그림을 생성하는 과정이 바로 이 역확산 과정입니다.
Stable Diffusion은 이 과정을 ‘잠재 공간(Latent Space)’이라는 저차원 공간에서 수행하여 계산 효율성을 크게 높였습니다. 고해상도 이미지를 직접 처리하는 대신, 이미지의 핵심 정보만 담고 있는 압축된 형태로 처리하기 때문에 더 빠르고 적은 자원으로도 고품질 이미지를 생성할 수 있습니다.
Stable Diffusion의 주요 구성 요소
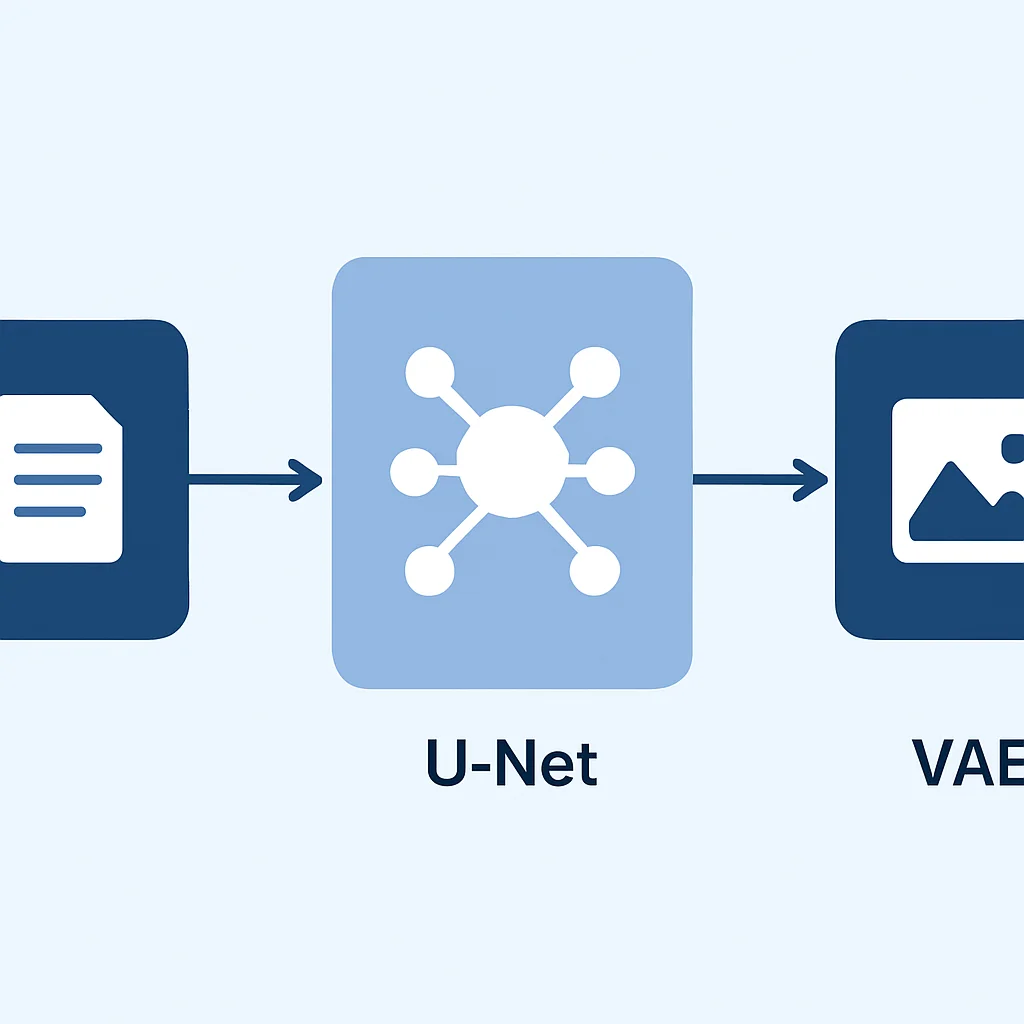
Stable Diffusion 모델은 크게 세 가지 핵심 구성 요소로 이루어져 있습니다.
1. Text Encoder (텍스트 인코더)
역할 — 사용자가 입력한 프롬프트(텍스트)를 AI가 이해할 수 있는 ‘의미론적 표현(Numerical Representation)’으로 변환합니다. 주로 CLIP(Contrastive Language–Image Pre-training) 모델을 사용하며, 텍스트와 이미지 간의 관계를 학습하여 프롬프트의 의도를 정확하게 파악하는 데 기여합니다.
핵심 — 이 인코더가 프롬프트를 얼마나 잘 해석하느냐에 따라 생성되는 이미지의 품질과 방향이 결정됩니다.
2. U-Net (유넷)
역할 — 실제 이미지 생성의 핵심적인 역할을 수행합니다. 잠재 공간에서 노이즈가 섞인 이미지 표현으로부터 노이즈를 예측하고 제거하는 작업을 반복합니다. 텍스트 인코더에서 넘어온 프롬프트 정보(조건)를 바탕으로 이미지를 생성하기 때문에, 프롬프트에 맞는 이미지를 만들어낼 수 있습니다.
핵심 — 노이즈 제거를 반복하며 점진적으로 이미지를 형성하는 ‘역확산’ 과정을 담당합니다. 우리가 흔히 사용하는 Stable Diffusion 모델 파일(.ckpt, .safetensors)은 주로 이 U-Net과 Text Encoder의 가중치를 포함하고 있습니다.
3. VAE (Variational AutoEncoder, 변분 오토인코더)
역할 — 이미지와 잠재 공간 사이의 변환을 담당합니다. 인코더 부분은 실제 이미지를 잠재 공간의 압축된 표현으로 변환하고, 디코더 부분은 잠재 공간의 표현을 다시 실제 이미지로 변환합니다. 즉, U-Net이 잠재 공간에서 이미지를 ‘그린’ 후, VAE의 디코더가 그 그림을 우리가 볼 수 있는 최종 이미지로 ‘복원’하는 역할을 합니다.
핵심 — 최종 이미지의 디테일과 색감에 큰 영향을 미칩니다. VAE는 이미지의 시각적 품질, 특히 얼굴이나 미세한 질감 표현에 중요한 역할을 하므로, 어떤 VAE를 사용하느냐에 따라 결과물의 분위기가 달라질 수 있습니다.
핵심 포인트
Stable Diffusion은 텍스트 인코더, U-Net, VAE 세 가지 핵심 구성 요소가 유기적으로 작동하여 텍스트 프롬프트를 기반으로 노이즈에서 이미지를 생성합니다. 특히 잠재 공간에서의 처리를 통해 효율성과 품질을 동시에 잡았습니다.
Stable Diffusion 버전별 특징 (2026년 기준)
Stable Diffusion은 지속적으로 발전하며 다양한 버전과 파생 모델이 출시되었습니다. 2026년 현재 주로 사용되는 모델들은 다음과 같습니다.
Stable Diffusion 1.5
특징 — 가장 널리 사용되고 많은 파생 모델(Checkpoint, LoRA)의 기반이 되는 모델입니다. 비교적 가벼워 낮은 사양의 GPU에서도 구동이 가능하며, 방대한 커뮤니티 자료와 튜토리얼이 존재합니다. 인물 표현에 강점을 보입니다.
장점 — 풍부한 커뮤니티 자원, 다양한 확장성, 낮은 GPU 요구 사항.
Stable Diffusion XL (SDXL)
특징 — 2023년 출시된 이후 2026년 현재 가장 보편적으로 사용되는 고품질 모델입니다. 1.5 버전에 비해 훨씬 뛰어난 이미지 품질, 더 나은 해상도(기본 1024×1024), 그리고 복잡한 프롬프트 이해 능력을 자랑합니다. 특히 인물 손가락이나 복잡한 배경 묘사가 크게 개선되었습니다.
장점 — 압도적인 이미지 품질, 높은 프롬프트 이해도, 사실적인 표현력.
Stable Cascade (SC)
특징 — 2024년에 등장한 새로운 아키텍처의 모델로, 이미지 생성 과정을 3단계(Stage A, B, C)로 나누어 더욱 효율적이고 고품질의 이미지를 생성합니다. 특히 VRAM 사용량이 SDXL보다 적으면서도 비슷한 수준의 품질을 제공하는 것이 특징입니다.
장점 — 효율적인 VRAM 사용, 빠른 생성 속도, 높은 품질.
설치 가이드
나만의 작업 환경 구축: Automatic1111 WebUI 설치 가이드
Stable Diffusion을 가장 쉽고 편리하게 사용할 수 있는 방법 중 하나는 Automatic1111 WebUI를 설치하는 것입니다. 이 웹 사용자 인터페이스는 다양한 기능과 확장성을 제공하여 초보자부터 전문가까지 모두 만족시킬 수 있습니다. Windows 환경을 기준으로 설치 방법을 상세히 안내해 드리겠습니다.
필요 사양 확인
Stable Diffusion은 GPU(그래픽 카드) 자원을 많이 사용합니다. 원활한 사용을 위해 다음 사양을 권장합니다.
✓ NVIDIA GPU (RTX 20, 30, 40 시리즈 권장): AMD GPU도 지원되지만, NVIDIA GPU가 더 안정적이고 성능이 좋습니다.
✓ VRAM (비디오 램): 최소 8GB 이상 권장 (SDXL 모델 사용 시 12GB 이상 권장). VRAM이 부족하면 이미지 생성 속도가 느려지거나 오류가 발생할 수 있습니다.
✓ 운영체제: Windows 10/11 (64비트)
✓ 저장 공간: 최소 50GB 이상 (모델 파일들이 크기 때문에 여유 있게 확보하는 것이 좋습니다)
핵심 포인트
Stable Diffusion 사용을 위한 최적의 환경은 NVIDIA GPU와 충분한 VRAM(최소 8GB, SDXL은 12GB 이상)입니다. 설치 전 시스템 사양을 반드시 확인하세요.
단계별 설치 가이드 (Windows 기준)
1
필수 프로그램 설치: Git 및 Python
Git 설치: Stable Diffusion WebUI 소스 코드를 다운로드하기 위해 Git이 필요합니다. Git 공식 웹사이트에서 Windows 버전을 다운로드하여 설치합니다. 설치 시 대부분 기본 옵션으로 진행해도 무방합니다.
Python 설치: Python 3.10.6 버전을 권장합니다 (다른 버전에서 호환성 문제가 발생할 수 있습니다). Python 3.10.6 공식 다운로드 페이지에서 ‘Windows installer (64-bit)’를 다운로드하여 설치합니다. 설치 시 반드시 ‘Add Python 3.10 to PATH’ 옵션을 체크해야 합니다.
2
Automatic1111 WebUI 다운로드
Stable Diffusion을 설치할 적당한 위치에 새 폴더를 만듭니다 (예: D:\StableDiffusion). 해당 폴더 안에서 마우스 오른쪽 버튼을 클릭하고 ‘Git Bash Here’ (Git 설치 시 생성됨) 또는 ‘터미널에서 열기’를 선택하여 명령 프롬프트/터미널을 엽니다. 다음 명령어를 입력하여 WebUI 소스 코드를 다운로드합니다.
코드 설명
이 명령어는 GitHub에서 Automatic1111 Stable Diffusion WebUI의 최신 버전을 현재 디렉터리로 복제(clone)합니다. stable-diffusion-webui라는 새 폴더가 생성되고 그 안에 모든 파일이 다운로드됩니다.
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git3
기본 모델(Checkpoint) 다운로드
WebUI를 실행하기 전에 기본 Stable Diffusion 모델 파일(Checkpoint)이 필요합니다. Civitai나 Hugging Face 같은 사이트에서 원하는 Stable Diffusion 모델을 다운로드합니다 (예: SDXL Base 모델). 다운로드한 .ckpt 또는 .safetensors 파일을 stable-diffusion-webui\models\Stable-diffusion 폴더 안에 넣어줍니다.
참고: SDXL 모델은 base와 refiner 두 가지가 필요할 수 있습니다. base 모델만으로도 이미지를 생성할 수 있지만, refiner를 사용하면 더 높은 품질의 디테일을 얻을 수 있습니다.
4
WebUI 실행 및 초기 설정
다운로드한 stable-diffusion-webui 폴더로 이동하여 webui-user.bat 파일을 더블클릭하여 실행합니다. 첫 실행 시 필요한 파이썬 라이브러리와 모델 파일들을 자동으로 다운로드하므로 시간이 다소 소요될 수 있습니다. 모든 준비가 완료되면 명령 프롬프트 창에 로컬 URL (예: http://127.0.0.1:7860)이 표시됩니다. 이 URL을 웹 브라우저에 입력하면 Stable Diffusion WebUI 화면을 만날 수 있습니다.
팁: webui-user.bat 파일을 편집하여 COMMANDLINE_ARGS 변수에 --xformers --autolaunch 등의 옵션을 추가하면 성능 향상 및 자동 실행을 설정할 수 있습니다. --xformers는 VRAM 사용량을 줄여주는 효과가 있습니다.
핵심 내용
AI 그림 마스터하기: 프롬프트 작성의 기술
Stable Diffusion으로 원하는 그림을 얻는 데 있어 가장 중요한 요소는 바로 ‘프롬프트(Prompt)’입니다. 프롬프트는 AI에게 어떤 그림을 그려달라고 지시하는 텍스트 명령문입니다. 단순히 단어를 나열하는 것을 넘어, 효과적인 프롬프트 작성 기술을 익히면 상상 이상의 결과물을 얻을 수 있습니다.
프롬프트의 기본 구조: 긍정 vs 부정
Stable Diffusion WebUI에는 크게 두 가지 프롬프트 입력란이 있습니다.
1. 긍정 프롬프트 (Positive Prompt): AI가 그림에 포함해야 할 요소를 지시합니다. “어떤 것을 그리고 싶은지”를 구체적으로 설명합니다. (예: a beautiful girl, long hair, blue eyes, wearing a white dress, standing in a flower field, sunny day)
2. 부정 프롬프트 (Negative Prompt): AI가 그림에 포함하지 말아야 할 요소를 지시합니다. “어떤 것을 피하고 싶은지”를 설명하여 그림의 품질을 높이는 데 매우 중요합니다. (예: low quality, bad anatomy, deformed, ugly, blurry, text, watermark)
효과적인 프롬프트 작성 꿀팁
프롬프트는 단순히 단어를 나열하는 것이 아니라, AI가 그림을 그리는 과정을 안내하는 일종의 ‘레시피’와 같습니다. 다음 팁들을 활용하여 더 나은 결과물을 만들어보세요.
1. 구체적이고 상세하게 묘사하기
“여자” 대신 “아름다운 금발의 젊은 여자, 푸른 눈, 활짝 웃는 표정”처럼 상세하게 묘사하면 AI가 더 정확한 이미지를 생성합니다.
“집” 대신 “숲속의 고풍스러운 오두막집, 지붕에는 이끼가 끼어 있고 굴뚝에서는 연기가 피어오르는” 식으로 디테일을 추가합니다.
2. 키워드 분류 및 조합
주제: girl, cat, house, spaceship
스타일: anime, oil painting, photorealistic, cyberpunk, watercolor
품질: masterpiece, best quality, 8k, ultra detailed, intricate details
시점/구도: full body, close-up, wide shot, from above, dynamic angle
조명/분위기: cinematic lighting, dramatic lighting, volumetric lighting, golden hour, gloomy atmosphere
3. 가중치 조절
특정 키워드에 더 큰 영향을 주고 싶다면 괄호와 숫자를 사용합니다. (keyword:1.2)는 keyword의 중요도를 20% 높입니다. (keyword:0.8)는 20% 낮춥니다. (기본값은 1.0)
예시: a beautiful (red rose:1.3) in a garden (붉은 장미를 더 강조)
4. Negative Prompt의 중요성
긍정 프롬프트만큼 중요한 것이 부정 프롬프트입니다. AI가 실수로 생성할 수 있는 품질 저하 요소를 미리 차단하여 이미지의 완성도를 높입니다. 일반적으로 많이 사용되는 부정 프롬프트는 다음과 같습니다.
(low quality, worst quality:1.4), (bad anatomy, deformed, disfigured:1.2), blurry, jpeg artifacts, ugly, extra limbs, missing limbs, text, watermark, signature, too dark, too bright, oversaturated, grayscale
코드 설명
아래는 고품질의 애니메이션 스타일 여성 캐릭터를 생성하기 위한 긍정/부정 프롬프트 예시입니다. 다양한 키워드를 조합하여 원하는 이미지를 얻는 방법을 보여줍니다.
[긍정 프롬프트]
masterpiece, best quality, 8k, ultra detailed, intricate details,
(anime style:1.2), a beautiful young girl, long flowing silver hair,
(glowing blue eyes:1.1), shy smile, wearing a white gothic lolita dress,
holding a magical staff, standing in a enchanted forest,
volumetric lighting, cinematic lighting, soft focus, depth of field
[부정 프롬프트]
(low quality, worst quality:1.4), (bad anatomy, deformed, disfigured:1.2),
blurry, jpeg artifacts, ugly, extra limbs, missing limbs, extra fingers,
poorly drawn hands, poorly drawn face, text, watermark, signature,
out of frame, tiling, poorly drawn eyes, cross-eyed, monochrome,
easynegative, bad-artist, bad-hands-5
핵심 포인트
프롬프트는 AI 그림 생성의 핵심입니다. 구체적인 묘사, 키워드 분류, 가중치 조절, 그리고 강력한 부정 프롬프트 사용을 통해 원하는 고품질 이미지를 얻을 수 있습니다. 다양한 시도를 통해 자신만의 노하우를 쌓는 것이 중요합니다.
주요 기능
Stable Diffusion의 고급 기능과 활용법
Stable Diffusion WebUI는 단순한 텍스트-투-이미지 기능을 넘어, 다양한 고급 설정을 통해 훨씬 더 세밀하고 정교한 결과물을 만들 수 있도록 돕습니다. 이제 몇 가지 핵심적인 고급 기능들을 살펴보겠습니다.
Checkpoint, LoRA, Embeddings: 모델의 확장
Stable Diffusion의 가장 큰 강점 중 하나는 방대한 커뮤니티가 생성한 다양한 모델들을 활용할 수 있다는 점입니다. 이들은 크게 세 가지 형태로 나뉩니다.
1. Checkpoint (.ckpt, .safetensors)
설명 — Stable Diffusion의 전체 모델 가중치를 포함하는 파일입니다. 특정 스타일(예: 실사, 애니메이션, 유화 등)이나 특정 주제(예: 판타지 캐릭터, 풍경)에 특화되어 학습된 모델들입니다. 가장 큰 영향을 미치며, 이미지 생성의 기본 뼈대가 됩니다.
활용 — WebUI 좌측 상단의 드롭다운 메뉴에서 원하는 체크포인트 모델을 선택하여 사용합니다. Civitai 등에서 다양한 모델을 다운로드하여 stable-diffusion-webui\models\Stable-diffusion 폴더에 넣습니다.
2. LoRA (Low-Rank Adaptation)
설명 — 기본 체크포인트 모델에 특정 스타일, 캐릭터, 의상 등을 미세하게 조정하여 추가하는 경량 모델입니다. 파일 크기가 작고 여러 LoRA를 동시에 적용할 수 있어 매우 유용합니다. Checkpoint 위에 덧입히는 개념으로 이해할 수 있습니다.
활용 — stable-diffusion-webui\models\lora 폴더에 넣고, 프롬프트 입력창 아래 ‘Show/hide extra networks’ 버튼을 클릭하여 선택하거나 <lora:lora_name:weight> 형식으로 프롬프트에 추가합니다.
3. Embeddings (Textual Inversion)
설명 — 특정 개념(사물, 스타일, 인물 등)을 몇 개의 가상 단어로 학습시켜 프롬프트에 쉽게 사용할 수 있도록 하는 기술입니다. LoRA보다 더 작은 파일 크기를 가지며, 주로 특정 부정 프롬프트 세트를 간소화하거나 특정 그림체 특징을 표현하는 데 사용됩니다.
활용 — stable-diffusion-webui\embeddings 폴더에 넣고, LoRA와 마찬가지로 ‘Show/hide extra networks’에서 선택하거나 프롬프트에 직접 이름을 입력하여 사용합니다. (예: easynegative)
핵심 포인트
Checkpoint는 그림의 전체적인 스타일을 결정하는 기본 모델이며, LoRA는 특정 디테일이나 스타일을 추가하는 경량 모델, Embeddings는 특정 개념을 간결하게 프롬프트에 적용하는 데 유용합니다. 이들을 조합하여 무궁무진한 결과물을 만들 수 있습니다.
주요 설정값 이해하기
WebUI에는 다양한 설정값이 있으며, 이들을 조절하여 이미지 생성 과정을 세밀하게 제어할 수 있습니다.
Sampling Method (샘플링 방식)
설명 — 노이즈 제거 과정을 어떤 방식으로 수행할지 결정하는 알고리즘입니다. 각 샘플링 방식마다 이미지의 디테일, 색감, 생성 속도에 차이가 있습니다. Euler a, DPM++ 2M Karras, DPM++ SDE Karras 등이 많이 사용됩니다.
추천 — DPM++ 2M Karras는 빠른 속도와 좋은 품질로 범용적으로 사용되며, DPM++ SDE Karras는 더 높은 품질을 제공하지만 생성 시간이 길 수 있습니다.
Sampling Steps (샘플링 스텝)
설명 — 노이즈 제거 단계를 몇 번 반복할 것인지 설정합니다. 스텝 수가 많을수록 이미지가 더 선명하고 디테일해지지만, 생성 시간도 길어집니다. 보통 20~30 스텝이 적당하며, 50 이상은 큰 차이가 없을 수 있습니다.
추천 — 20~30 사이에서 시작하여 원하는 품질에 따라 조절합니다.
CFG Scale (Classifier Free Guidance Scale)
설명 — 프롬프트의 지시를 얼마나 강하게 따를 것인지 결정하는 값입니다. 값이 높을수록 프롬프트에 충실한 이미지를 생성하지만, 너무 높으면 이미지 왜곡이 발생할 수 있습니다. 반대로 낮으면 AI의 창의성이 발휘되어 예상치 못한 결과가 나올 수 있습니다.
추천 — 7~12 사이가 일반적입니다. 실사 이미지에는 5~7, 애니메이션에는 7~10이 적합한 경우가 많습니다.
Seed (시드)
설명 — 이미지 생성 시 초기 노이즈 패턴을 결정하는 고유한 숫자입니다. 동일한 시드값, 프롬프트, 설정을 사용하면 항상 동일한 이미지가 생성됩니다. 마음에 드는 이미지를 얻었을 때 시드값을 기록해두면 나중에 비슷한 이미지를 재생성하거나 변형하는 데 유용합니다.
활용 — 새로운 이미지를 생성할 때는 -1 (랜덤 시드)을 사용하고, 특정 이미지를 재현하거나 미세 조정할 때는 해당 이미지의 시드값을 입력합니다.
핵심 포인트
샘플링 방식, 샘플링 스텝, CFG 스케일, 시드값은 이미지 생성에 큰 영향을 미치는 주요 설정값입니다. 이 값들을 이해하고 조절함으로써 원하는 이미지에 더욱 가깝게 다가갈 수 있습니다. 다양한 조합을 시도해보는 것이 중요합니다.
Img2Img, Inpainting, Outpainting: 이미지 변형의 마법
Stable Diffusion은 텍스트-투-이미지뿐만 아니라, 기존 이미지를 활용하여 새로운 이미지를 만들거나 수정하는 강력한 기능들도 제공합니다.
Img2Img (이미지-투-이미지)
설명 — 기존 이미지를 입력으로 받아 프롬프트에 따라 새로운 이미지를 생성합니다. 원본 이미지의 구성이나 색감을 유지하면서 스타일을 변경하거나 새로운 요소를 추가할 수 있습니다. ‘Denoising Strength’ 값을 통해 원본 이미지의 유지 정도를 조절합니다.
활용 — 스케치를 그림으로 바꾸거나, 사진을 애니메이션 스타일로 변환하거나, 특정 분위기의 이미지를 다양한 스타일로 변주할 때 사용합니다.
Inpainting (인페인팅)
설명 — 이미지의 특정 영역을 마스크(Mask)로 지정하고, 해당 영역만 프롬프트에 따라 수정하는 기능입니다. 이미지 내의 불필요한 객체를 제거하거나, 새로운 객체를 추가하거나, 인물의 의상이나 표정을 변경하는 데 유용합니다.
활용 — 사진 보정, AI 캐릭터의 손가락 오류 수정, 배경 변경 등 세밀한 이미지 수정 작업에 필수적입니다.
Outpainting (아웃페인팅)
설명 — 이미지의 바깥 영역을 확장하여 새로운 내용을 생성하는 기능입니다. 원본 이미지의 스타일과 내용에 맞춰 자연스럽게 배경을 확장하거나, 그림의 구도를 변경할 때 사용합니다.
활용 — 그림의 배경을 넓히거나, 잘려나간 부분을 복원하거나, 파노라마 이미지를 생성하는 데 활용됩니다.
ControlNet: 자세와 구도 제어의 혁명
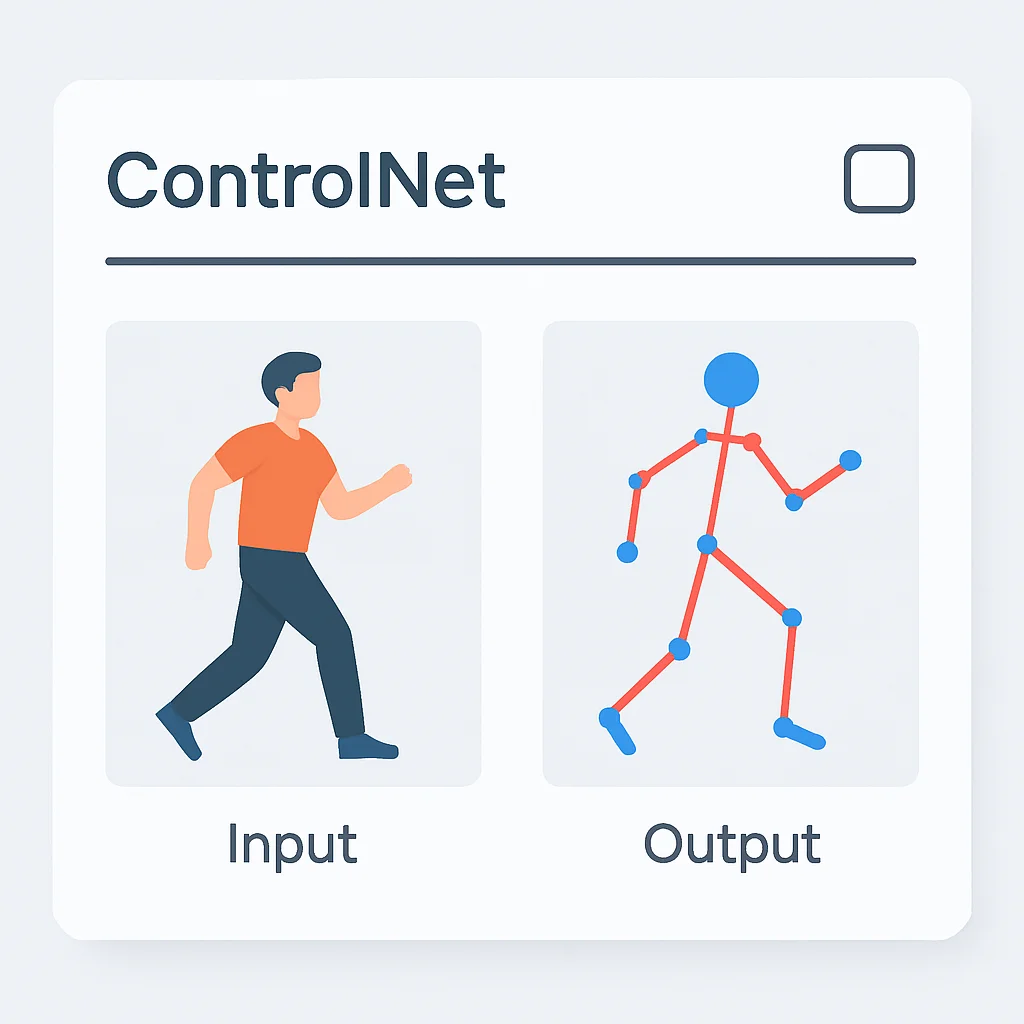
ControlNet은 2023년 등장하여 Stable Diffusion 활용의 판도를 바꾼 혁신적인 기능입니다. 기존에는 프롬프트만으로는 인물의 정확한 자세나 복잡한 구도를 제어하기 어려웠지만, ControlNet은 입력 이미지(스케치, 포즈, 깊이 맵 등)를 기반으로 이미지 생성 과정을 정밀하게 제어할 수 있게 해줍니다.
ControlNet의 작동 원리
ControlNet은 Stable Diffusion의 U-Net에 추가적인 조건을 부여하는 방식으로 작동합니다. 사용자가 입력한 이미지(예: 스틱맨 포즈, 깊이 정보, 가장자리 윤곽선)를 분석하여 이를 AI가 이해할 수 있는 ‘제어 신호’로 변환하고, 이 신호를 이미지 생성 과정에 반영하여 결과물의 형태를 제어합니다.
주요 모델: OpenPose (인물 자세), Canny (윤곽선), Depth (깊이 정보), Normal Map (표면 법선), Lineart (선화), Scribble (낙서) 등 다양한 모델이 존재합니다.
핵심 포인트
ControlNet은 Stable Diffusion의 창의성에 정밀한 제어력을 더해주는 필수적인 확장 기능입니다. 인물의 자세, 배경의 구성, 이미지의 전체적인 형태를 사용자가 원하는 대로 조작할 수 있게 하여, AI 그림의 활용 범위를 무한히 확장시킵니다.
문제 해결