인공지능, 머신러닝, 고성능 컴퓨팅(HPC) 워크로드가 폭발적으로 증가하는 2026년, 기업들은 컴퓨팅 자원의 효율적인 활용에 대한 깊은 고민에 빠져 있습니다. 특히 고가의 GPU 자원을 어떻게 하면 더 많은 사용자에게, 더 유연하게 제공할 수 있을지가 핵심 과제로 떠올랐습니다. 이러한 배경 속에서 GPU 가상화 기술은 단순한 트렌드를 넘어, 기업 IT 인프라의 운영 효율성과 유연성을 극대화하는 핵심 솔루션으로 주목받고 있습니다.
이 글에서는 GPU 가상화가 왜 지금 기업들에게 필수적인 기술이 되었는지, 핵심 기술인 vGPU와 passthrough의 차이점은 무엇인지, 실제 환경에서의 성능과 효율성은 어떠한지 구체적인 데이터를 통해 분석합니다. 더불어 성공적인 도입을 위한 고려사항과 실전 적용 가이드를 제시하고, 2026년 이후 GPU 가상화의 미래를 전망합니다. 권퓨터와 함께 GPU 가상화의 가능성과 현실을 깊이 있게 탐구하며, 여러분의 IT 인프라 혁신 전략을 수립하는 데 필요한 통찰력을 얻어가시길 바랍니다.
2026년, 전 세계 기업들은 인공지능(AI), 머신러닝(ML), 데이터 분석, 고성능 가상 데스크톱 인프라(VDI), CAD/CAM 등의 고성능 컴퓨팅(HPC) 워크로드를 처리하기 위해 GPU(그래픽 처리 장치)의 중요성을 그 어느 때보다 절감하고 있습니다. 과거에는 주로 그래픽 처리나 게임에 사용되었던 GPU가 이제는 방대한 병렬 연산 능력 덕분에 데이터 집약적인 작업의 핵심 엔진으로 자리 잡았습니다. 하지만 이러한 GPU 자원을 효율적으로 관리하고 활용하는 것은 또 다른 도전 과제로 떠올랐습니다.
기존에는 물리적인 GPU를 서버에 직접 장착하고, 특정 애플리케이션이나 사용자에게 전용으로 할당하는 방식이 일반적이었습니다. 그러나 이 방식은 몇 가지 심각한 문제점을 야기합니다. 첫째, GPU 자원의 비효율적인 활용입니다. 특정 시간에만 GPU를 집중적으로 사용하는 워크로드의 경우, 나머지 시간에는 GPU가 유휴 상태로 남아 자원 낭비가 심합니다. 둘째, 높은 도입 및 운영 비용입니다. 고성능 GPU는 가격이 매우 비싸며, 각 사용자 또는 워크로드에 전용 GPU를 할당하는 것은 막대한 비용 부담으로 이어집니다. 셋째, 유연성 부족입니다. 자원 할당 변경이나 확장 시 물리적인 재배치 또는 추가 구매가 필요하여 신속한 대응이 어렵습니다.
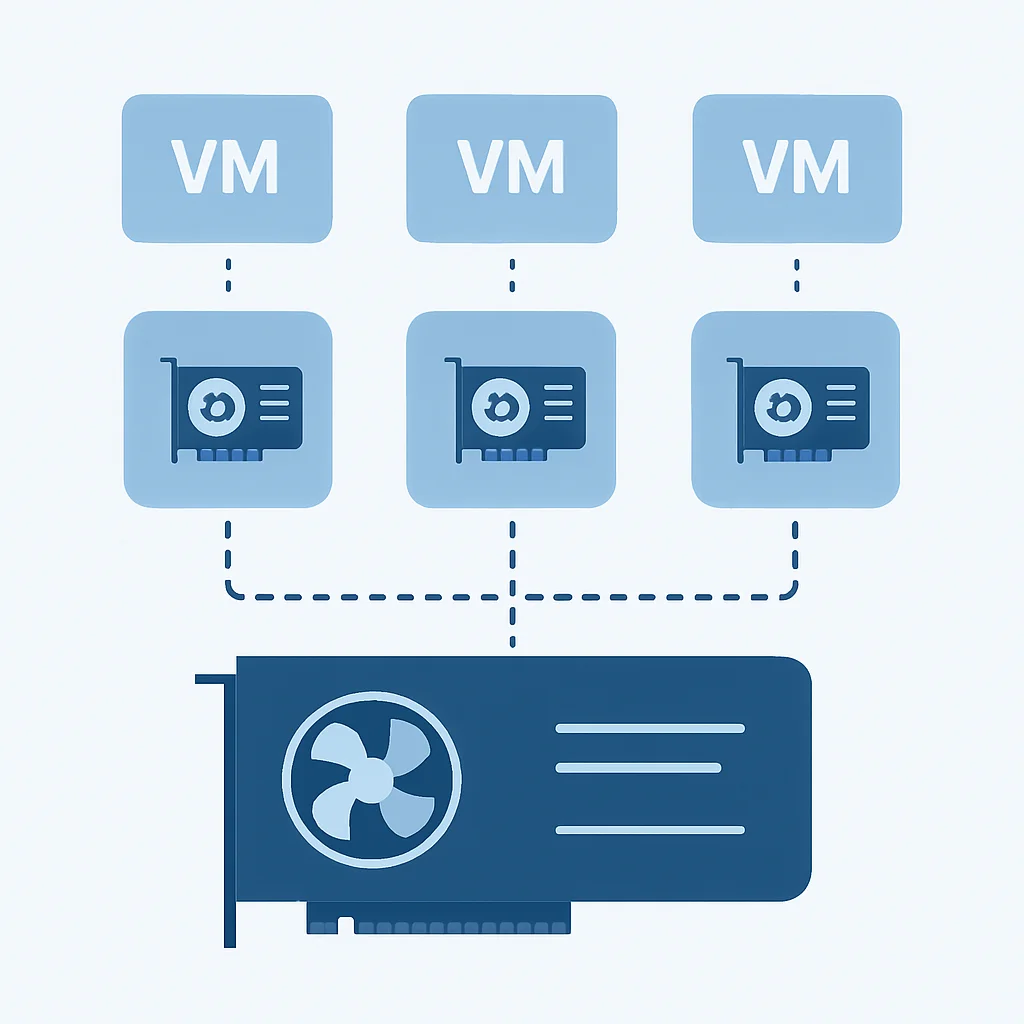
이러한 문제들을 해결하기 위해 GPU 가상화 기술이 강력한 대안으로 부상하고 있습니다. GPU 가상화는 하나의 물리적 GPU를 여러 개의 가상 GPU(vGPU)로 분할하여 다수의 가상 머신(VM) 또는 컨테이너에 할당함으로써, GPU 자원의 활용도를 극대화하고 유연성을 확보하는 기술입니다. 이를 통해 기업은 다음과 같은 핵심 이점을 얻을 수 있습니다.
첫째, 자원 활용률 증대: 하나의 물리적 GPU를 여러 VM이 공유함으로써 유휴 자원을 최소화하고, GPU 사용률을 획기적으로 높일 수 있습니다. 이는 곧 투자 대비 효율성 증대로 이어집니다. 둘째, 비용 절감: 물리적 GPU 구매 대수를 줄이고, 데이터센터의 전력 소비 및 냉각 비용을 절감할 수 있습니다. 셋째, 운영 유연성 및 민첩성 향상: 필요한 시점에 필요한 만큼의 GPU 자원을 동적으로 할당하고 회수할 수 있어, 비즈니스 변화에 신속하게 대응할 수 있습니다. 넷째, 중앙 집중식 관리: 가상화 플랫폼을 통해 GPU 자원을 중앙에서 통합 관리하여 관리 복잡성을 줄이고 효율성을 높일 수 있습니다.
2026년 현재, GPU 가상화는 더 이상 실험적인 기술이 아닙니다. NVIDIA GRID, AMD MxGPU와 같은 상용 솔루션과 더불어 KVM 기반의 오픈소스 솔루션들이 성숙기에 접어들면서, 다양한 산업 분야에서 실제 도입 사례가 늘고 있습니다. 특히 클라우드 환경과 온프레미스 환경 모두에서 GPU 가상화의 도입은 기업의 디지털 트랜스포메이션 가속화에 결정적인 역할을 하고 있습니다. 이제 다음 섹션에서는 GPU 가상화의 핵심 기술인 vGPU와 Passthrough 방식에 대해 자세히 알아보겠습니다.
핵심 기술 분석: vGPU와 Passthrough의 차이
GPU 가상화 기술은 크게 두 가지 주요 방식으로 나눌 수 있습니다: vGPU(Virtual GPU)와 Passthrough(또는 Direct Assignment)입니다. 두 방식은 GPU 자원을 가상 머신(VM)에 할당하는 방식과 성능, 유연성 측면에서 명확한 차이를 보이며, 기업의 특정 워크로드와 요구사항에 따라 적절한 선택이 필요합니다.
핵심은 하나의 물리적 GPU를 어떻게 여러 VM이 공유하는지에 있습니다.
1. vGPU (Virtual GPU) 방식
vGPU 방식은 하이퍼바이저(Hypervisor)가 물리적 GPU를 여러 개의 가상 GPU로 분할하고, 이를 각 VM에 할당하는 방식입니다. 이 과정에서 GPU 벤더가 제공하는 특수 소프트웨어(예: NVIDIA vGPU 소프트웨어, AMD MxGPU)와 드라이버가 필수적으로 사용됩니다. 하이퍼바이저가 GPU 자원을 관리하고 스케줄링하여 여러 VM이 시분할(Time-sharing) 또는 공간 분할(Space-sharing) 방식으로 하나의 물리적 GPU를 공유하게 됩니다.
장점:
높은 밀도 및 활용률: 하나의 고성능 GPU를 수십 개의 VM이 공유할 수 있어 자원 활용률이 매우 높습니다.
세분화된 제어: GPU 메모리, 컴퓨팅 코어 등을 VM별로 세밀하게 할당할 수 있습니다.
라이브 마이그레이션 지원: VM의 무중단 이동(Live Migration)이 가능하여 유지보수 및 DR(재해 복구)에 유리합니다.
중앙 관리: 가상화 플랫폼에서 GPU 자원 풀을 통합 관리할 수 있습니다.
NVIDIA의 vGPU 솔루션은 다양한 워크로드에 최적화된 프로파일(예: NVIDIA vWS for CAD, vPC for VDI, vCS for AI/ML)을 제공하여 특정 요구사항에 맞는 성능을 보장합니다.
단점:
성능 오버헤드: 하이퍼바이저와 vGPU 소프트웨어 계층으로 인해 물리 GPU 대비 약간의 성능 저하가 발생할 수 있습니다.
라이선스 및 비용: 대부분의 vGPU 솔루션은 추가적인 소프트웨어 라이선스 비용이 발생합니다.
벤더 종속성: 특정 GPU 벤더의 소프트웨어 및 드라이버에 종속될 수 있습니다.
복잡한 설정: 초기 설정 및 드라이버 관리가 Passthrough 방식보다 복잡할 수 있습니다.
2. Passthrough (Direct Assignment) 방식
GPU Passthrough 방식은 물리적 GPU 전체를 특정 VM에 독점적으로 할당하는 방식입니다. 하이퍼바이저는 GPU에 대한 직접적인 접근 권한을 VM에 부여하며, VM은 마치 물리 서버에 GPU가 직접 장착된 것처럼 GPU를 인식하고 사용합니다. 이는 Intel VT-d 또는 AMD-Vi와 같은 IOMMU(Input/Output Memory Management Unit) 기술을 활용하여 구현됩니다.
장점:
거의 네이티브에 가까운 성능: 중간 계층이 없어 물리 GPU와 거의 동일한 성능을 제공합니다.
광범위한 호환성: 특별한 벤더 소프트웨어 없이도 다양한 GPU 및 운영체제에서 작동합니다.
간단한 설정: vGPU 방식에 비해 설정이 비교적 간단합니다.
라이선스 비용 없음: 별도의 소프트웨어 라이선스 비용이 발생하지 않습니다.
데이터 과학자나 엔지니어링 설계자처럼 단일 사용자가 GPU의 모든 자원을 필요로 하는 고성능 워크로드에 특히 적합합니다.
단점:
낮은 밀도: 하나의 물리적 GPU를 하나의 VM만 사용할 수 있으므로 자원 활용률이 낮습니다.
라이브 마이그레이션 미지원: 일반적으로 VM의 라이브 마이그레이션을 지원하지 않아 유지보수 시 다운타임이 발생할 수 있습니다.
자원 파편화: 물리 GPU가 여러 개일 경우, 각 GPU가 특정 VM에 고정되어 다른 VM에서 사용하기 어렵게 됩니다.
하드웨어 종속성: IOMMU 그룹 설정 등 하드웨어 구성에 대한 이해가 필요합니다.
3. vGPU와 Passthrough 비교 요약
다음 표는 vGPU와 Passthrough 방식의 주요 특징을 비교하여, 기업이 자신의 요구사항에 맞는 최적의 솔루션을 선택하는 데 도움을 줍니다.
특징
vGPU (Virtual GPU)
Passthrough (Direct Assignment)
자원 공유 방식
하나의 물리 GPU를 여러 VM이 공유 (시분할/공간분할)
하나의 물리 GPU를 하나의 VM이 독점
성능
물리 GPU 대비 70~95% (워크로드 및 프로파일에 따라 다름)
물리 GPU 대비 95~99% (거의 네이티브 성능)
자원 활용률
높음 (고밀도)
낮음 (저밀도)
라이브 마이그레이션
지원
미지원 (또는 제한적 지원)
소프트웨어/라이선스
필수 (벤더별 라이선스 비용 발생)
필요 없음
관리 복잡성
높음 (드라이버, 프로파일 관리)
낮음 (VM 내 일반 GPU처럼 인식)
적합한 워크로드
VDI, CAD/CAE, 그래픽 디자인, 경량 AI/ML 추론
HPC, AI/ML 학습, 고성능 렌더링, 특정 장치 의존적 워크로드
표 1: vGPU와 Passthrough 방식의 주요 특징 비교
성능 벤치마크: 실제 환경에서의 효율성
이론적인 장점과 단점을 넘어, 실제 환경에서 GPU 가상화가 얼마나 효율적인지 이해하는 것이 중요합니다. 2026년 현재, 다양한 벤치마크 도구와 실제 워크로드를 통해 vGPU와 Passthrough 방식의 성능을 비교 분석한 결과는 다음과 같습니다.
벤치마크 결과는 워크로드 유형과 vGPU 프로파일 선택이 성능에 결정적인 영향을 미친다는 것을 보여줍니다.
1. 벤치마크 환경 및 워크로드
테스트 플랫폼: VMware vSphere 8.0U2 기반 서버 2대 (각 서버당 Intel Xeon E5-2690 v4 CPU 2개, 512GB RAM, NVIDIA A100 80GB GPU 2개 장착)
비교 대상:
Bare-metal (물리 서버): GPU를 직접 장착한 물리 서버에서 워크로드 실행 (기준 성능)
Passthrough VM: 하나의 VM에 NVIDIA A100 GPU 전체를 독점 할당
vGPU VM (프로파일 1): NVIDIA A100 GPU를 4개의 vGPU (A100-40C80G-4Q)로 분할, 각 VM에 1개 할당 (40GB 프레임 버퍼, 80 컴퓨팅 코어)
vGPU VM (프로파일 2): NVIDIA A100 GPU를 8개의 vGPU (A100-20C40G-8Q)로 분할, 각 VM에 1개 할당 (20GB 프레임 버퍼, 40 컴퓨팅 코어)
주요 워크로드:
AI 학습 (ResNet-50): PyTorch 기반 ResNet-50 모델 학습 시간 측정
CAD 렌더링 (SPECviewperf 2020): 3D CAD 애플리케이션의 그래픽 성능 측정 (maya, solidworks 등)
VDI 사용자 밀도 (LoginVSI): 가상 데스크톱 환경에서 사용자 수용 능력 및 응답 시간 측정
2. 벤치마크 결과 분석
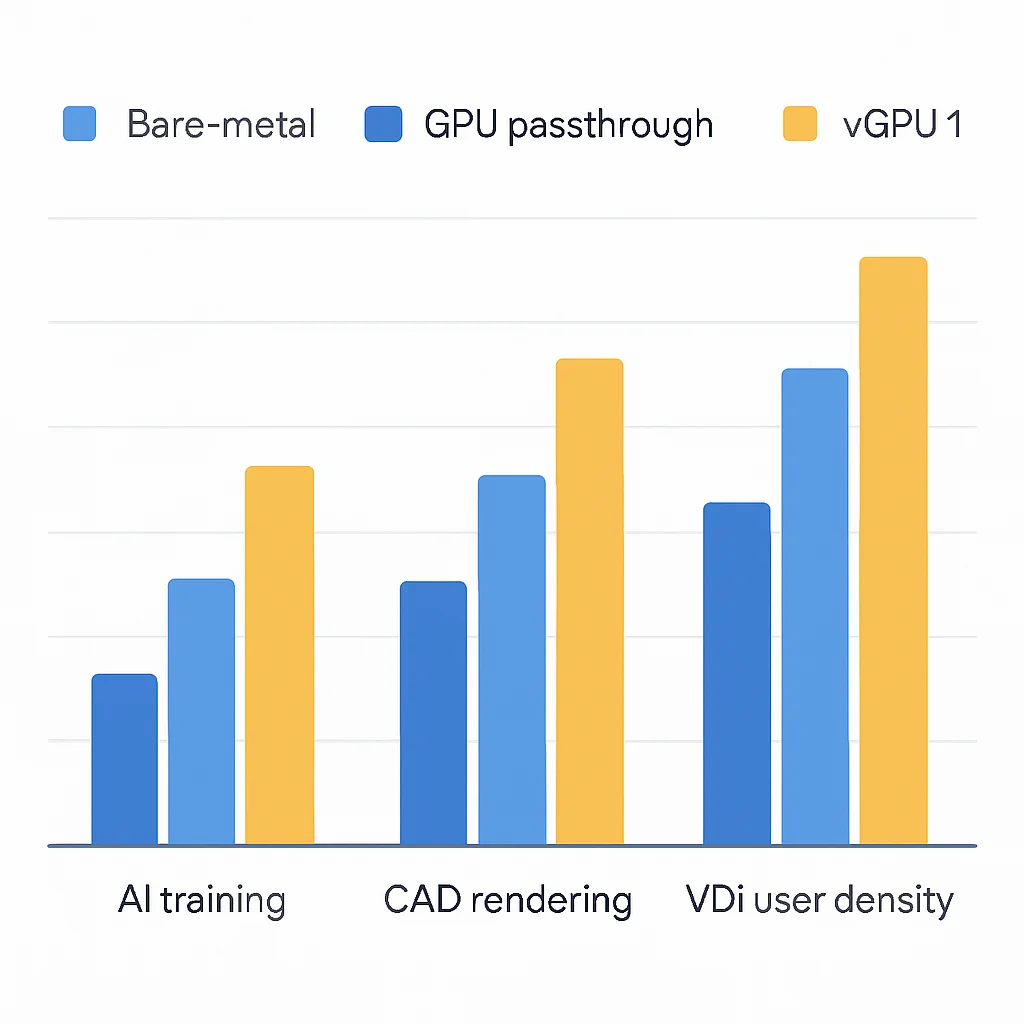
AI 학습 (ResNet-50) 성능:
Bare-metal: 100% (기준)
Passthrough VM: 98.5% (Bare-metal 대비 거의 차이 없음)
vGPU VM (프로파일 1 – 40GB/80C): 92.1%
vGPU VM (프로파일 2 – 20GB/40C): 81.7%
AI 학습과 같은 고성능 컴퓨팅 워크로드에서는 Passthrough 방식이 물리 GPU와 거의 동일한 성능을 제공합니다. vGPU 방식도 높은 프로파일에서는 준수한 성능을 보이지만, 공유 자원 및 소프트웨어 계층으로 인한 미미한 오버헤드가 관찰됩니다. 낮은 프로파일은 성능 저하가 더 뚜렷합니다.
CAD 렌더링 (SPECviewperf 2020) 성능:
Bare-metal: 100% (기준)
Passthrough VM: 97.8%
vGPU VM (프로파일 1 – 40GB/80C): 85.5%
vGPU VM (프로파일 2 – 20GB/40C): 72.3%
CAD 렌더링과 같은 그래픽 집약적 워크로드에서도 Passthrough는 우수한 성능을 보입니다. vGPU는 프로파일에 따라 성능 차이가 크며, 특히 고해상도 모델링이나 복잡한 렌더링 작업 시 낮은 프로파일에서는 사용자 경험에 영향을 줄 수 있는 수준의 성능 저하가 나타날 수 있습니다.
VDI 사용자 밀도 (LoginVSI) 성능:
Bare-metal (개별 워크스테이션): 1인당 1GPU (낮은 밀도)
Passthrough VM: 1인당 1GPU (낮은 밀도, 비효율적)
vGPU VM (프로파일 1 – 40GB/80C): 물리 GPU당 4명의 사용자 수용 가능 (중간 밀도)
vGPU VM (프로파일 2 – 20GB/40C): 물리 GPU당 8명의 사용자 수용 가능 (고밀도)
VDI 환경에서는 vGPU의 진정한 강점이 드러납니다. Passthrough 방식은 1:1 할당이므로 밀도 측면에서 비효율적입니다. 반면 vGPU는 하나의 물리 GPU로 여러 사용자를 동시에 지원하여, 자원 활용률을 극대화하고 전반적인 TCO(총 소유 비용)를 절감하는 데 크게 기여합니다. 프로파일 선택에 따라 사용자당 할당되는 GPU 자원량이 달라지므로, VDI 사용자의 요구사항(일반 오피스, 캐주얼 CAD, 고성능 CAD)에 맞춰 적절한 프로파일을 선택하는 것이 중요합니다.
이러한 벤치마크 결과는 GPU 가상화 기술이 특정 워크로드에 따라 최적의 선택지가 달라질 수 있음을 명확히 보여줍니다. 높은 GPU 성능이 절대적으로 필요한 AI 학습이나 HPC 환경에서는 Passthrough 방식이 유리하며, 다수의 사용자에게 유연하고 효율적인 GPU 자원을 제공해야 하는 VDI, 그래픽 디자인, 경량 AI 추론 환경에서는 vGPU 방식이 압도적인 이점을 가집니다. 기업은 이러한 데이터를 바탕으로 자신의 IT 인프라와 워크로드 특성을 면밀히 분석하여 가장 적합한 GPU 가상화 전략을 수립해야 합니다.
구현 시 고려사항 및 문제 해결 전략
GPU 가상화 기술은 많은 이점을 제공하지만, 성공적인 도입과 안정적인 운영을 위해서는 여러 기술적 고려사항과 발생 가능한 문제에 대한 해결 전략을 미리 수립해야 합니다. 2026년 현재 기업들이 직면하는 주요 도전 과제와 그 해결책을 살펴보겠습니다.
성공적인 GPU 가상화는 하드웨어, 소프트웨어, 그리고 운영 환경 전반에 대한 깊은 이해를 요구합니다.
1. 하드웨어 호환성 및 구성
GPU 가상화를 위해서는 특정 GPU 모델, 서버 하드웨어, 그리고 하이퍼바이저 간의 호환성이 필수적입니다. 모든 GPU가 가상화를 지원하는 것은 아니며, 특히 vGPU 기술은 특정 벤더(예: NVIDIA Tesla/Quadro/RTX, AMD Radeon Pro)의 엔터프라이즈급 GPU에서만 지원됩니다.
GPU 선택: 워크로드의 특성(AI/ML, VDI, 렌더링)에 맞는 GPU를 선택하고, 해당 GPU가 가상화를 지원하는지 확인해야 합니다. 예를 들어, NVIDIA A100/H100은 AI/HPC에, L4/L40은 VDI 및 그래픽 작업에 주로 사용됩니다.
서버 구성: GPU 장착을 위한 충분한 PCIe 슬롯, 전원 공급 장치, 냉각 시스템을 갖춘 서버가 필요합니다. 또한 CPU의 IOMMU(VT-d 또는 AMD-Vi) 기능이 BIOS에서 활성화되어야 Passthrough가 가능합니다.
하이퍼바이저: VMware vSphere, Citrix Hypervisor, Microsoft Hyper-V, KVM 등 사용하려는 하이퍼바이저가 GPU 가상화 기능을 지원하는지 확인해야 합니다. 각 하이퍼바이저마다 GPU 가상화 구현 방식에 차이가 있을 수 있습니다.
2. 소프트웨어 라이선스 및 드라이버 관리
vGPU 솔루션은 일반적으로 라이선스 모델을 따르므로, 초기 도입 비용 외에 지속적인 라이선스 비용을 고려해야 합니다. NVIDIA vGPU의 경우, 사용자 또는 GPU 단위로 라이선스가 책정될 수 있습니다. 또한, 호스트(하이퍼바이저)와 게스트(VM) 모두에 올바른 드라이버를 설치하고 관리하는 것이 중요합니다.
라이선스 계획: 필요한 vGPU 프로파일과 사용자 수를 기반으로 라이선스 비용을 정확히 예측하고 예산을 수립해야 합니다.
드라이버 일치: 호스트와 게스트 OS의 드라이버 버전이 vGPU 벤더가 권장하는 버전에 일치해야 합니다. 버전 불일치는 성능 저하나 기능 오작동의 주된 원인이 됩니다.
업데이트 정책: GPU 드라이버 및 vGPU 소프트웨어는 주기적으로 업데이트되므로, 안정적인 운영을 위한 업데이트 정책을 수립해야 합니다.
3. 네트워크 지연 및 자원 스케줄링
특히 VDI 환경에서 GPU 가상화를 사용하는 경우, 네트워크 지연 시간은 사용자 경험에 큰 영향을 미칩니다. 또한, 여러 VM이 하나의 GPU 자원을 공유할 때 발생하는 자원 스케줄링 문제는 성능 저하로 이어질 수 있습니다.
고대역폭 네트워크: VDI 사용자 수가 많거나 고해상도 그래픽 작업이 필요한 경우, 10GbE 이상의 고대역폭 네트워크 인프라가 필수적입니다.
프로토콜 최적화: PCoIP, HDX, Blast Extreme 등 VDI 프로토콜을 GPU 가상화 환경에 맞게 최적화해야 합니다.
자원 오버커밋 방지: vGPU 환경에서 너무 많은 VM을 하나의 GPU에 할당하면 성능 저하가 발생합니다. 워크로드 특성을 고려하여 적절한 오버커밋 비율을 유지해야 합니다.
모니터링 강화: GPU 사용률, 메모리 사용량, 인코더/디코더 부하 등 GPU 관련 메트릭을 실시간으로 모니터링하여 병목 현상을 조기에 감지하고 대응해야 합니다.
4. 문제 해결 예시: KVM 기반 Passthrough 설정 확인
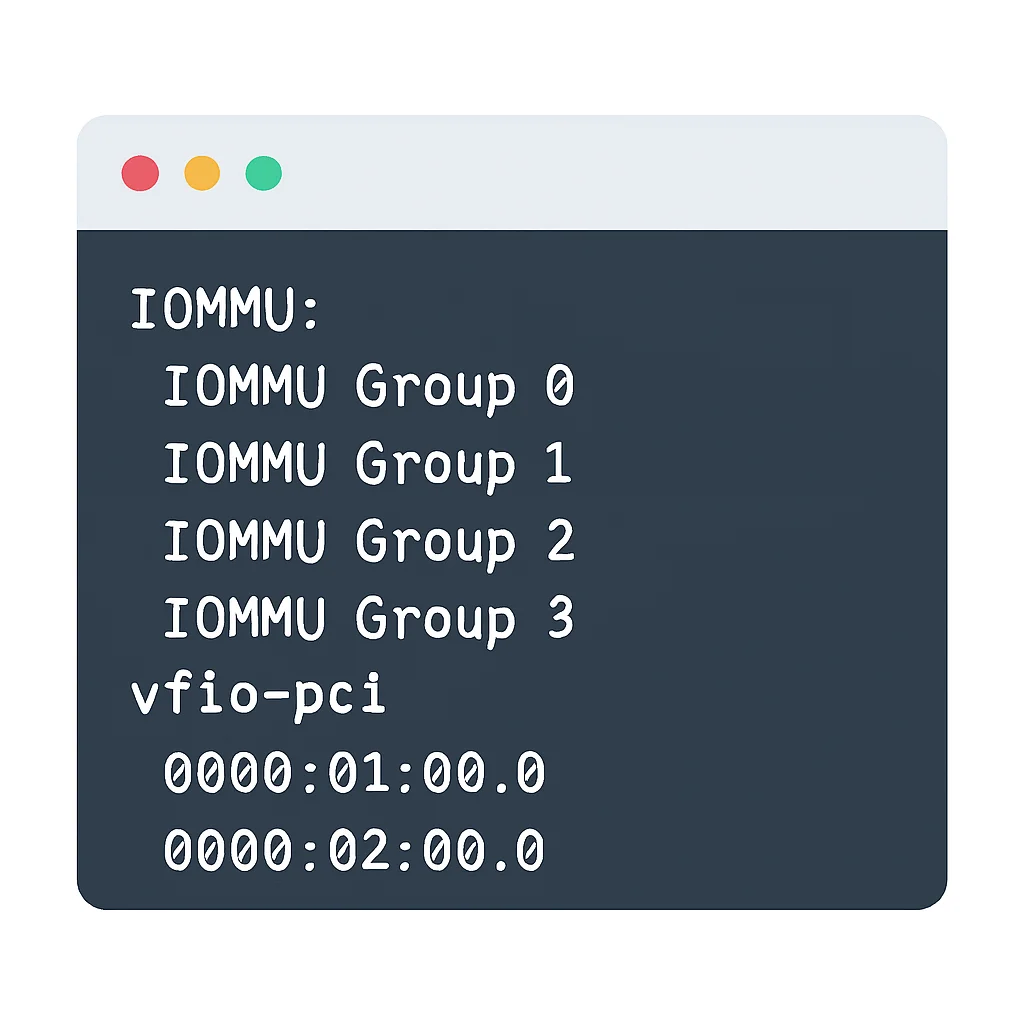
KVM 환경에서 GPU Passthrough 설정 시, GPU가 VM에 제대로 할당되지 않는 문제가 발생할 수 있습니다. 이는 주로 IOMMU 그룹 설정 문제나 커널 모듈 설정 오류에서 비롯됩니다. 다음은 리눅스 호스트에서 Passthrough 설정을 확인하는 기본적인 단계입니다.
# 1. IOMMU가 활성화되었는지 확인
grep -e DMAR -e IOMMU /var/log/dmesg
# 출력 예시:
# DMAR: IOMMU enabled
# 2. GPU가 IOMMU 그룹으로 분리되었는지 확인 (PCIe ID 확인)
lspci -nn | grep -i vga
# 출력 예시:
# 01:00.0 VGA compatible controller [0300]: NVIDIA Corporation GP104 [GeForce GTX 1070] [10de:1b81] (rev a1)
# 01:00.1 Audio device [0403]: NVIDIA Corporation GP104 High Definition Audio Controller [10de:10f0] (rev a1)
# 3. IOMMU 그룹 확인 (위에서 얻은 PCI ID 사용)
for d in $(find /sys/kernel/iommu_groups/*/devices -prune -name "*" | sort -V); do
echo "IOMMU Group $(basename $(dirname $d)):";
for s in $(ls -v $d); do
echo -e "\t$(lspci -nns $s)";
done;
done
# 출력 예시:
# IOMMU Group 1:
# 00:01.0 PCI bridge [0604]: Intel Corporation Xeon E3-1200 v5/E3-1500 v5/6th Gen Core Processor PCIe Root Port 1 [8086:1901] (rev 08)
# IOMMU Group 2:
# 01:00.0 VGA compatible controller [0300]: NVIDIA Corporation GP104 [GeForce GTX 1070] [10de:1b81] (rev a1)
# 01:00.1 Audio device [0403]: NVIDIA Corporation GP104 High Definition Audio Controller [10de:10f0] (rev a1)
# (GPU와 오디오 컨트롤러가 하나의 IOMMU 그룹에 속해야 함)
# 4. vfio-pci 모듈에 GPU ID 바인딩
# /etc/modprobe.d/vfio.conf 파일 생성 또는 편집
# options vfio-pci ids=10de:1b81,10de:10f0
# (위에서 확인한 GPU 벤더 ID:장치 ID 입력)
# 5. initramfs 재생성 및 재부팅
# update-initramfs -u -k all
# reboot
# 6. VM 설정에서 GPU Passthrough 활성화
# virt-manager 또는 virsh edit 명령어를 사용하여 VM XML 설정 파일에 GPU 추가
#
#
#
#
#
#
# (bus, slot, function 값은 실제 GPU의 PCI 주소로 대체)
코드 1: KVM 기반 리눅스 호스트에서 GPU Passthrough 설정 확인 및 바인딩 예시
위와 같은 절차를 통해 GPU가 올바른 IOMMU 그룹으로 분리되고 vfio-pci 드라이버에 바인딩되었는지 확인할 수 있습니다. Passthrough 설정은 OS 및 하이퍼바이저 버전에 따라 세부적인 차이가 있을 수 있으므로, 항상 공식 문서를 참조하는 것이 중요합니다.
실전 적용 사례: GPU 가상화 도입 가이드
GPU 가상화 기술을 성공적으로 기업 환경에 도입하기 위해서는 체계적인 계획과 단계별 접근이 필요합니다. 2026년 현재 많은 기업들이 따르고 있는 일반적인 도입 가이드를 제시합니다.