

요약
2026년 강화학습(Reinforcement Learning) 시작 가이드
파이썬과 OpenAI Gym을 활용하여 AI 에이전트를 직접 만들고, 강화학습의 핵심 원리를 쉽고 재미있게 배우는 여정입니다.
핵심 키워드: 강화학습, AI 에이전트, 파이썬
목차
1. 왜 지금 강화학습에 주목해야 할까요?
2. 강화학습의 핵심 개념 파헤치기
3. 파이썬과 OpenAI Gym으로 강화학습 시작하기
4. 강화학습 에이전트 개발 시 마주하는 문제와 해결 전략
5. 실전 예제: CartPole 게임 마스터하기 (Q-Learning 구현)
6. 강화학습, 어디까지 발전할까요? (미래 전망)
7. 자주 묻는 질문 (FAQ)
1. 왜 지금 강화학습에 주목해야 할까요?
안녕하세요, 권퓨터입니다! 2026년, 인공지능(AI) 기술은 우리 삶의 거의 모든 영역에 깊숙이 스며들고 있습니다. 그중에서도 특히 주목받는 분야가 바로 강화학습(Reinforcement Learning)인데요. 강화학습은 AI 에이전트가 시행착오를 통해 스스로 최적의 행동 전략을 학습하는 머신러닝의 한 종류입니다. 마치 어린아이가 세상을 탐험하며 배우듯이, AI가 특정 환경에서 보상을 최대화하는 방향으로 학습해 나가는 것이죠. 복잡한 문제를 해결하고, 예측 불가능한 상황에 유연하게 대처할 수 있는 능력을 갖춘 AI를 만들 수 있기에, 자율주행, 로봇 제어, 게임, 금융 트레이딩 등 다양한 분야에서 혁신적인 성과를 만들어내고 있습니다.
이번 포스팅에서는 강화학습의 기본 개념부터, 파이썬(Python)과 OpenAI Gym 라이브러리를 활용하여 나만의 AI 에이전트를 직접 만드는 실전 가이드까지 자세히 살펴보겠습니다. 이론적인 내용뿐만 아니라, 실제 코드를 통해 강화학습이 어떻게 동작하는지 직관적으로 이해할 수 있도록 구성했습니다. AI 시대를 이끌어갈 핵심 기술인 강화학습의 세계로 함께 떠나볼 준비가 되셨나요?
핵심 포인트
강화학습은 AI 에이전트가 환경과의 상호작용을 통해 스스로 최적의 전략을 학습하는 방법론으로, 2026년 현재 다양한 산업 분야에서 혁신을 주도하고 있습니다.
2. 강화학습의 핵심 개념 파헤치기
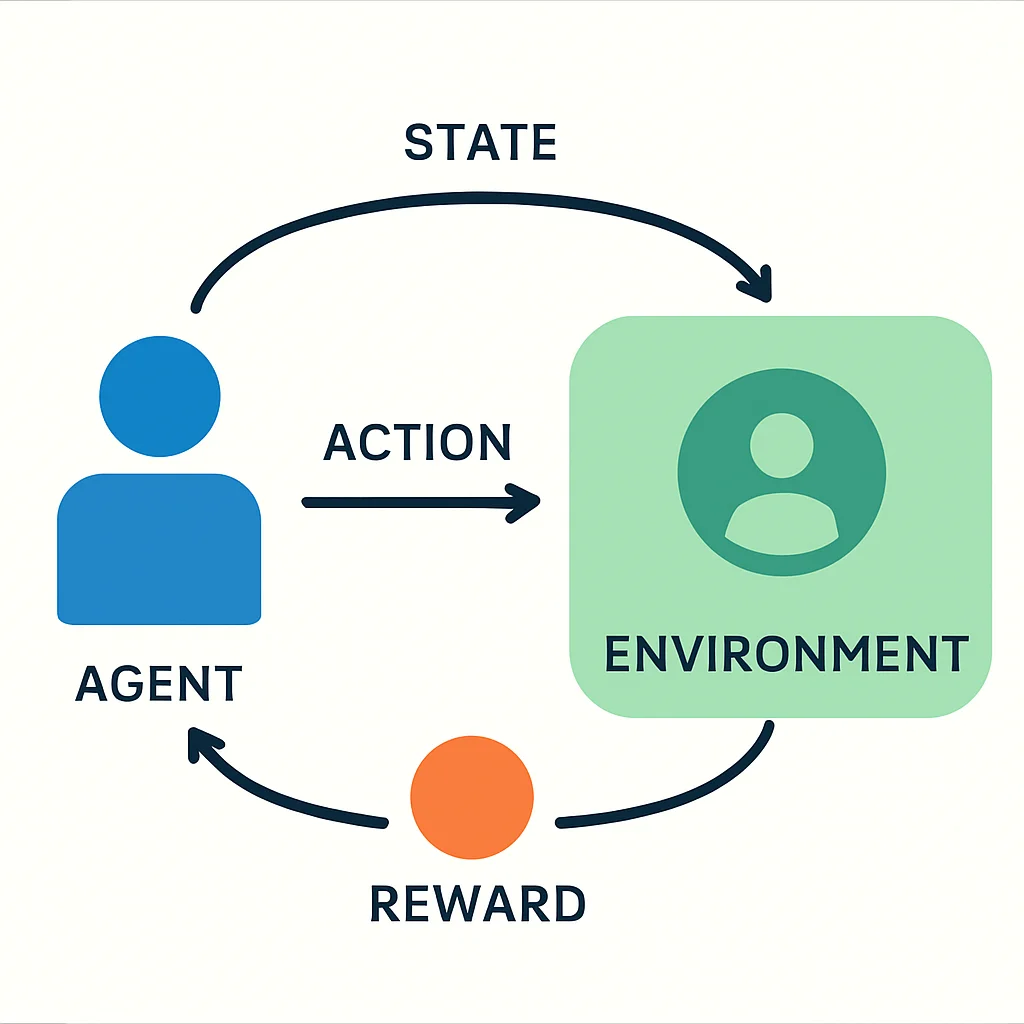
본격적으로 강화학습을 시작하기 전에 몇 가지 중요한 용어와 개념을 이해해야 합니다. 강화학습은 크게 에이전트(Agent)와 환경(Environment)이라는 두 주체의 상호작용으로 이루어집니다. 에이전트가 환경에서 어떤 행동을 취하고, 그 결과로 환경이 어떻게 변하며, 에이전트에게 어떤 보상이 주어지는지를 반복하며 학습이 진행됩니다.
2.1. 에이전트, 환경, 상태, 행동, 보상
강화학습 시스템을 구성하는 주요 요소들을 하나씩 살펴보겠습니다.
강화학습 핵심 구성 요소
에이전트 (Agent) — 학습하고 행동하는 주체입니다. 목표는 누적 보상을 최대화하는 것입니다.
환경 (Environment) — 에이전트가 상호작용하는 세상입니다. 에이전트의 행동에 반응하여 새로운 상태와 보상을 제공합니다.
상태 (State, S) — 특정 시점에서 환경의 현재 상황을 나타내는 정보입니다. 에이전트는 이 상태를 기반으로 행동을 결정합니다.
행동 (Action, A) — 에이전트가 특정 상태에서 취할 수 있는 선택입니다. 환경은 이 행동에 따라 변화합니다.
보상 (Reward, R) — 에이전트가 행동을 취한 후 환경으로부터 받는 피드백입니다. 긍정적 보상은 좋은 행동, 부정적 보상은 나쁜 행동을 의미합니다.
이러한 요소들은 마치 사람이 어떤 목표를 가지고 행동하고, 그 결과에 따라 만족감이나 후회를 느끼며 다음 행동을 결정하는 것과 유사합니다. 예를 들어, 로봇이 미로를 탈출하는 게임에서 에이전트는 로봇, 환경은 미로, 상태는 로봇의 현재 위치, 행동은 ‘앞으로 이동’, ‘좌회전’, ‘우회전’ 등이 될 수 있으며, 미로를 탈출하면 큰 보상을, 벽에 부딪히면 작은 음의 보상을 받을 수 있습니다.
2.2. 가치 함수와 정책 함수
강화학습에서 에이전트가 최적의 행동을 학습하는 데에는 두 가지 핵심 함수가 사용됩니다.
강화학습 핵심 함수
가치 함수 (Value Function, V 또는 Q) — 특정 상태 또는 특정 상태에서 특정 행동을 했을 때, 미래에 얻을 수 있는 총 보상의 기댓값을 나타냅니다. 에이전트가 “얼마나 좋은 상황인가?”를 판단하는 기준이 됩니다.
정책 함수 (Policy Function, π) — 특정 상태에서 어떤 행동을 할지 결정하는 에이전트의 전략입니다. 즉, “어떻게 행동해야 하는가?”를 정의합니다. 정책은 확률 분포 형태로 나타나거나, 특정 상태에 대한 최적 행동을 직접적으로 알려줄 수 있습니다.
이 두 함수는 서로 밀접하게 연결되어 있습니다. 좋은 정책은 높은 가치를 가지는 상태로 에이전트를 이끌고, 높은 가치를 가지는 상태는 좋은 정책을 통해 도달할 수 있습니다. 강화학습의 목표는 결국 이 가치 함수나 정책 함수를 최적화하여 에이전트가 가장 많은 보상을 얻도록 하는 것입니다.
2.3. 탐험과 활용 (Exploration & Exploitation)
강화학습 에이전트가 효과적으로 학습하려면 ‘탐험(Exploration)’과 ‘활용(Exploitation)’ 사이의 균형을 잘 맞춰야 합니다. 이 개념은 강화학습의 가장 근본적인 딜레마 중 하나입니다.
탐험 (Exploration)
✔ 아직 시도해보지 않은 새로운 행동을 탐색하여 더 좋은 보상을 찾으려는 시도입니다.
✔ 장기적인 최적화를 위해 초기에 다양한 경험을 쌓는 데 중요합니다.
활용 (Exploitation)
✖ 현재까지 학습한 정보(가치 함수)를 바탕으로 가장 높은 보상을 줄 것으로 예상되는 행동을 선택하는 것입니다.
✖ 단기적인 보상을 최대화하는 데 효과적입니다.
너무 탐험만 하면 불필요한 시행착오를 많이 겪어 학습이 느려질 수 있고, 너무 활용만 하면 지역 최적해(Local Optimum)에 갇혀 더 좋은 전략을 찾지 못할 수 있습니다. 이 균형을 맞추기 위해 엡실론-그리디(epsilon-greedy)와 같은 전략이 널리 사용됩니다. 엡실론(epsilon) 확률로 무작위 행동(탐험)을 하고, 1-엡실론 확률로 현재까지 가장 좋다고 판단된 행동(활용)을 선택하는 방식입니다.
핵심 포인트
강화학습은 에이전트와 환경의 상호작용, 가치/정책 함수의 최적화, 그리고 탐험과 활용의 균형을 통해 진행됩니다. 이 개념들을 명확히 이해하는 것이 강화학습의 성공적인 구현에 필수적입니다.
3. 파이썬과 OpenAI Gym으로 강화학습 시작하기
이론적인 배경을 살펴보았으니, 이제 실제로 코드를 작성하며 강화학습의 세계에 발을 들여놓을 시간입니다. 우리는 파이썬(Python) 프로그래밍 언어와 OpenAI Gym 라이브러리를 활용할 것입니다. OpenAI Gym은 강화학습 알고리즘을 개발하고 비교할 수 있는 다양한 환경(Environment)을 제공하는 툴킷으로, 초보자도 쉽게 강화학습을 시작할 수 있도록 돕습니다.
3.1. OpenAI Gym 소개 및 설치
OpenAI Gym은 다양한 강화학습 환경을 표준화된 인터페이스로 제공합니다. 이를 통해 개발자는 환경 구현에 대한 복잡한 고민 없이 알고리즘 개발에 집중할 수 있습니다. 설치는 매우 간단합니다. 파이썬 환경이 준비되어 있다면, 다음 명령어를 통해 설치할 수 있습니다.
코드 설명
파이썬 패키지 관리 도구인 pip를 사용하여 OpenAI Gym 라이브러리를 설치하는 명령어입니다. 최신 버전의 Gym은 gymnasium으로 이름이 변경되었으나, 본 포스팅에서는 일반적으로 더 알려진 gym을 기준으로 설명하며, 호환성을 위해 pip install gym[classic_control]을 사용합니다.
pip install gym[classic_control] numpy여기서 [classic_control]은 CartPole과 같은 기본적인 제어 환경들을 포함하는 옵션입니다. numpy는 수치 계산에 필요한 라이브러리입니다.
3.2. 환경 선택 및 초기화
설치가 완료되면, 이제 Gym 환경을 생성하고 초기화할 수 있습니다. 우리는 가장 대표적인 환경 중 하나인 CartPole-v1을 사용해볼 것입니다. CartPole은 카트에 매달린 막대가 넘어지지 않도록 카트를 좌우로 움직이는 간단한 게임입니다.
코드 설명
OpenAI Gym 라이브러리를 임포트하고, make() 함수를 사용하여 ‘CartPole-v1’ 환경을 생성하는 코드입니다. 환경 생성 후 reset() 메서드를 호출하여 환경을 초기 상태로 되돌리고, render()를 통해 환경의 시각적 표현을 확인합니다.
import gym
import time
# CartPole-v1 환경 생성
env = gym.make('CartPole-v1', render_mode='human') # render_mode='human'으로 시각화 활성화
# 환경 초기화 (초기 상태, 추가 정보 반환)
observation, info = env.reset()
print(f"초기 상태: {observation}")
print(f"상태 공간: {env.observation_space}")
print(f"행동 공간: {env.action_space}")
# 임의의 행동을 10번 수행하며 환경 변화 확인
for _ in range(10):
action = env.action_space.sample() # 무작위 행동 선택
observation, reward, terminated, truncated, info = env.step(action)
print(f"행동: {action}, 다음 상태: {observation}, 보상: {reward}, 종료 여부: {terminated}, 중단 여부: {truncated}")
env.render() # 환경 시각화
time.sleep(0.1) # 짧은 지연
if terminated or truncated:
print("에피소드 종료!")
break
# 환경 닫기
env.close()
위 코드를 실행하면 CartPole 게임 창이 뜨면서 카트가 무작위로 움직이는 것을 볼 수 있습니다. observation_space는 에이전트가 관찰할 수 있는 상태의 범위를, action_space는 에이전트가 취할 수 있는 행동의 범위를 알려줍니다. CartPole-v1의 상태는 4차원 연속 값(카트 위치, 카트 속도, 막대 각도, 막대 각속도)이고, 행동은 2가지 이산 값(0: 왼쪽으로 밀기, 1: 오른쪽으로 밀기)입니다.
3.3. Q-Learning 알고리즘 구현
이제 강화학습의 가장 기본적인 알고리즘 중 하나인 Q-Learning을 살펴보겠습니다. Q-Learning은 가치 함수 기반의 알고리즘으로, 특정 상태에서 특정 행동을 했을 때 얻을 수 있는 최대 미래 보상(Q값)을 학습합니다. Q값은 Q-테이블이라는 형태로 저장되며, 에이전트는 이 Q-테이블을 참조하여 최적의 행동을 선택합니다.
Q-Learning의 핵심은 벨만 방정식(Bellman Equation)을 사용하여 Q값을 업데이트하는 것입니다. 업데이트 규칙은 다음과 같습니다.
Q(s, a) ← Q(s, a) + α [r + γ max_a' Q(s', a') - Q(s, a)]
여기서 각 기호는 다음과 같은 의미를 가집니다:
Q(s, a): 현재 상태(s)에서 행동(a)을 했을 때의 Q값.
α (알파): 학습률(Learning Rate). 새로 얻은 정보가 기존 Q값에 얼마나 반영될지 조절합니다 (0과 1 사이 값).
r: 현재 행동으로 얻은 즉각적인 보상.
γ (감마): 할인율(Discount Factor). 미래 보상을 얼마나 중요하게 여길지 조절합니다 (0과 1 사이 값).
max_a’ Q(s’, a’): 다음 상태(s’)에서 취할 수 있는 모든 행동(a’) 중 가장 높은 Q값.
Q-Learning은 이산적인 상태와 행동 공간을 가진 문제에 매우 효과적입니다. CartPole의 상태 공간은 연속적이지만, 우리는 이를 이산화(discretization)하여 Q-테이블을 만들 수 있습니다. 이는 연속적인 상태 값을 특정 구간으로 나누어 이산적인 상태로 취급하는 방법입니다.
핵심 포인트
OpenAI Gym은 강화학습 환경을 표준화하여 제공하며, Q-Learning은 벨만 방정식을 기반으로 Q-테이블을 업데이트하며 최적의 행동 전략을 학습하는 강력한 알고리즘입니다.
4. 강화학습 에이전트 개발 시 마주하는 문제와 해결 전략
강화학습은 매력적인 분야이지만, 실제 에이전트를 개발하는 과정에서는 여러 가지 기술적 도전과제를 마주하게 됩니다. 이러한 문제들을 이해하고 적절한 해결 전략을 적용하는 것이 성공적인 강화학습 모델 구축에 중요합니다.
4.1. 수렴 속도 개선
강화학습 에이전트가 최적의 정책을 학습하는 데에는 많은 시간이 소요될 수 있습니다. 특히 복잡한 환경이나 희소한 보상(Sparse Reward)을 가진 환경에서는 학습 속도가 매우 느려지곤 합니다.
문제 01
느린 학습 수렴 속도
에이전트가 최적의 행동을 찾기까지 너무 많은 에피소드를 필요로 하거나, 아예 수렴하지 못하는 경우가 발생합니다. 특히 보상이 드물게 주어지는 환경에서 심화됩니다.
해결
보상 형성 (Reward Shaping): 학습 초기에 에이전트가 목표에 근접할 때마다 작은 보상을 주어 학습을 유도합니다.
경험 리플레이 (Experience Replay): 에이전트의 과거 경험들을 저장하고 무작위로 샘플링하여 학습에 재사용함으로써 데이터의 효율성을 높이고 학습 안정성을 개선합니다.
병렬 학습 (Parallel Learning): 여러 에이전트가 동시에 학습하거나, 하나의 에이전트가 여러 환경에서 동시에 학습하여 데이터 수집 속도를 가속화합니다.
4.2. 탐험 전략의 중요성
앞서 언급했듯이 탐험과 활용의 균형은 강화학습의 성패를 좌우하는 중요한 요소입니다. 너무 적은 탐험은 지역 최적해에 갇히게 하고, 너무 많은 탐험은 학습 효율을 떨어뜨립니다.
문제 02
비효율적인 탐험
에이전트가 새로운 환경을 충분히 탐색하지 못하거나, 이미 잘 알려진 경로만 반복하여 최적의 경로를 놓치는 경우가 발생합니다.
해결
엡실론-그리디 (Epsilon-Greedy): 가장 기본적인 전략으로, 작은 확률 ε로 무작위 행동을, 1-ε 확률로 최적 행동을 선택합니다. 학습이 진행됨에 따라 ε 값을 점차 줄여나갑니다.
UCB (Upper Confidence Bound): 불확실성이 높은 행동에 더 많은 탐험 가중치를 부여합니다. 즉, 아직 많이 시도해보지 않았지만 잠재적으로 높은 보상을 줄 수 있는 행동을 우선적으로 탐험합니다.
엔트로피 보너스 (Entropy Bonus): 정책의 무작위성(엔트로피)에 비례하는 보너스를 주어 에이전트가 더 다양한 행동을 시도하도록 장려합니다. 이는 특히 정책 기반 알고리즘에서 효과적입니다.
핵심 포인트
강화학습의 학습 속도와 효율적인 탐험은 주요 도전 과제입니다. 보상 형성, 경험 리플레이, 다양한 탐험 전략을 통해 이러한 문제를 효과적으로 해결할 수 있습니다.
5. 실전 예제: CartPole 게임 마스터하기 (Q-Learning 구현)
이제 앞서 배운 Q-Learning 알고리즘을 사용하여 CartPole 게임을 마스터하는 AI 에이전트를 직접 만들어 보겠습니다. CartPole 환경은 상태 공간이 연속적이기 때문에, Q-Learning을 적용하기 위해 상태 공간을 이산화하는 과정이 필요합니다.
5.1. CartPole 환경 이해 및 상태 이산화
CartPole의 상태는 4개의 연속적인 값으로 구성됩니다: 카트 위치(-2.4 ~ 2.4), 카트 속도(-inf ~ inf), 막대 각도(-0.2095 ~ 0.2095 라디안), 막대 각속도(-inf ~ inf). 이 값들을 그대로 Q-테이블의 인덱스로 사용할 수 없으므로, 각 차원을 여러 개의 ‘구간’으로 나누어 이산화합니다.
예를 들어, 카트 위치를 10개의 구간으로 나누고, 막대 각도를 10개의 구간으로 나누는 식입니다. 이렇게 하면 4차원 연속 상태가 4차원 이산 상태로 변환되며, 이를 Q-테이블의 인덱스로 사용할 수 있습니다. 각 차원의 구간 개수는 하이퍼파라미터로, 에이전트의 성능에 영향을 미칩니다.

5.2. Q-Table 기반 학습 구현
이제 Q-Learning 알고리즘을 파이썬으로 구현해봅시다. 주요 단계는 다음과 같습니다.
Step 1
환경 및 하이퍼파라미터 설정
OpenAI Gym 환경을 생성하고, 학습률(α), 할인율(γ), 엡실론(ε) 등의 하이퍼파라미터를 정의합니다.
Step 2
Q-Table 초기화 및 상태 이산화 함수 구현
Q-Table은 모든 상태-행동 쌍에 대한 Q값을 저장하는 N차원 배열입니다. 이를 0으로 초기화하고, 연속적인 관측값을 이산적인 상태 인덱스로 변환하는 함수를 만듭니다.
Step 3
학습 루프 실행
정해진 에피소드 수만큼 환경과 상호작용하며 Q-Table을 업데이트합니다. 각 스텝에서 행동 선택 (엡실론-그리디), 환경 상호작용, Q값 업데이트 과정을 반복합니다.
Step 4
결과 평가 및 시각화
학습된 Q-Table을 사용하여 에이전트의 성능을 평가하고, 학습 과정을 시각화하여 성능 개선 추이를 확인합니다.
코드 설명
아래 코드는 CartPole 환경에서 Q-Learning 에이전트를 학습시키는 전체 과정을 담고 있습니다. 상태 이산화, Q-Table 초기화, 엡실론-그리디 행동 선택, Q값 업데이트 로직이 포함되어 있습니다. 학습이 완료되면 에이전트가 CartPole을 쓰러뜨리지 않고 얼마나 오래 유지하는지 평가합니다.
import gym
import numpy as np
import random
import matplotlib.pyplot as plt
# 1. 환경 및 하이퍼파라미터 설정
env = gym.make('CartPole-v1')
# 하이퍼파라미터
LEARNING_RATE = 0.1 # 학습률 (α)
DISCOUNT_FACTOR = 0.99 # 할인율 (γ)
EPSILON = 1.0 # 탐험 비율 (ε)
EPSILON_DECAY_RATE = 0.001 # 엡실론 감소율
MIN_EPSILON = 0.01 # 최소 엡실론
N_EPISODES = 2000 # 에피소드 수
# 상태 공간 이산화를 위한 구간 설정
# CartPole 상태: [카트 위치, 카트 속도, 막대 각도, 막대 각속도]
# 각 차원의 min/max 값과 구간 개수 정의
pos_space = np.linspace(-2.4, 2.4, 10) # 10개 구간
vel_space = np.linspace(-4, 4, 10) # 10개 구간 (대략적인 추정치)
ang_space = np.linspace(-0.2095, 0.2095, 10) # 10개 구간
ang_vel_space = np.linspace(-4, 4, 10) # 10개 구간 (대략적인 추정치)
# 2. Q-Table 초기화 및 상태 이산화 함수 구현
# Q-Table 크기: (pos_bins, vel_bins, ang_bins, ang_vel_bins, action_space_size)
q_table = np.zeros((len(pos_space)+1, len(vel_space)+1, len(ang_space)+1, len(ang_vel_space)+1, env.action_space.n))
def get_state(observation):
# 각 연속적인 observation 값을 이산적인 인덱스로 변환
pos_idx = np.digitize(observation[0], pos_space)
vel_idx = np.digitize(observation[1], vel_space)
ang_idx = np.digitize(observation[2], ang_space)
ang_vel_idx = np.digitize(observation[3], ang_vel_space)
return (pos_idx, vel_idx, ang_idx, ang_vel_idx)
# 학습 과정에서 에피소드별 보상 기록
rewards_per_episode = []
# 3. 학습 루프 실행
for episode in range(N_EPISODES):
state = get_state(env.reset()[0]) # 초기 상태 얻기
terminated = False
truncated = False
episode_reward = 0
while not terminated and not truncated:
# 엡실론-그리디 전략으로 행동 선택
if random.uniform(0, 1) < EPSILON:
action = env.action_space.sample() # 탐험: 무작위 행동
else:
action = np.argmax(q_table[state]) # 활용: 현재 Q-Table에서 최적 행동
# 선택한 행동 수행 및 다음 상태, 보상 얻기
next_observation, reward, terminated, truncated, info = env.step(action)
next_state = get_state(next_observation)
# Q-Table 업데이트 (벨만 방정식)
current_q = q_table[state + (action,)]
max_future_q = np.max(q_table[next_state])
new_q = current_q + LEARNING_RATE * (reward + DISCOUNT_FACTOR * max_future_q - current_q)
q_table[state + (action,)] = new_q
state = next_state
episode_reward += reward
# 엡실론 감소 (탐험 비율 점차 줄이기)
EPSILON = max(MIN_EPSILON, EPSILON - EPSILON_DECAY_RATE)
rewards_per_episode.append(episode_reward)
if (episode + 1) % 100 == 0:
print(f"에피소드 {episode + 1}/{N_EPISODES} - 평균 보상: {np.mean(rewards_per_episode[-100:]):.2f}, 엡실론: {EPSILON:.2f}")
env.close()
# 4. 결과 평가 및 시각화
print("학습 완료! 에이전트 성능 평가 중...")
test_env = gym.make('CartPole-v1', render_mode='human')
total_test_rewards = []
for _ in range(5): # 5번의 테스트 에피소드
state = get_state(test_env.reset()[0])
terminated = False
truncated = False
test_reward = 0
while not terminated and not truncated:
action = np.argmax(q_table[state]) # 학습된 Q-Table로 최적 행동 선택 (탐험 없이)
next_observation, reward, terminated, truncated, info = test_env.step(action)
state = get_state(next_observation)
test_reward += reward
test_env.render()
time.sleep(0.02) # 시각화를 위한 짧은 지연
total_test_rewards.append(test_reward)
print(f"테스트 에피소드 보상: {test_reward}")
test_env.close()
print(f"평균 테스트 보상: {np.mean(total_test_rewards):.2f}")
# 학습 곡선 시각화
plt.figure(figsize=(12, 6))
plt.plot(rewards_per_episode)
plt.title('Q-Learning 학습 보상 변화')
plt.xlabel('에피소드')
plt.ylabel('총 보상')
plt.grid(True)
plt.show()
# 이동 평균 보상 시각화 (더 부드러운 추세)
plt.figure(figsize=(12, 6))
N = 100 # 100 에피소드 이동 평균
moving_avg = np.convolve(rewards_per_episode, np.ones(N)/N, mode='valid')
plt.plot(moving_avg)
plt.title(f'Q-Learning 학습 보상 변화 (최근 {N} 에피소드 이동 평균)')
plt.xlabel('에피소드')
plt.ylabel('이동 평균 보상')
plt.grid(True)
plt.show()
5.3. 결과 분석 및 시각화
위 코드를 실행하면, 수많은 에피소드를 거치면서 Q-Table이 점진적으로 업데이트되고, 에이전트가 CartPole을 쓰러뜨리지 않고 더 오래 유지하는 방법을 학습하는 것을 확인할 수 있습니다. 보상 그래프를 통해 학습 초기에는 보상이 낮다가 점차 높아지는 추세를 볼 수 있습니다. CartPole-v1 환경의 목표는 500 스텝 동안 막대를 유지하는 것이며, 평균 보상이 475 이상이 되면 ‘해결(Solved)’되었다고 간주합니다.
만약 학습이 잘 되지 않는다면, LEARNING_RATE, DISCOUNT_FACTOR, EPSILON_DECAY_RATE와 같은 하이퍼파라미터를 조정하거나, 상태 공간 이산화의 구간 개수를 늘려 더 세밀하게 상태를 구분해보는 시도를 할 수 있습니다.
핵심 포인트
CartPole 환경에서 Q-Learning을 적용하기 위해 연속적인 상태 공간을 이산화하는 과정이 필수적입니다. 학습률, 할인율, 엡실론 등의 하이퍼파라미터 튜닝이 에이전트 성능에 큰 영향을 미칩니다.
6. 강화학습, 어디까지 발전할까요? (미래 전망)
지금까지 강화학습의 기본 개념부터 파이썬과 OpenAI Gym을 활용한 실전 예제까지 살펴보았습니다. Q-Learning은 비교적 간단한 환경에서 효과적이지만, 현대 강화학습은 훨씬 더 복잡하고 강력한 방향으로 발전하고 있습니다. 2026년 현재, 강화학습은 다음과 같은 방향으로 진화하고 있으며, 앞으로도 무궁무진한 잠재력을 가지고 있습니다.
6.1. 딥 강화학습 (Deep Reinforcement Learning, DRL)
Q-Learning과 같은 전통적인 강화학습은 상태 공간이 커지면 Q-Table을 관리하기 어렵다는 한계가 있습니다. 이러한 문제를 해결하기 위해 딥러닝(Deep Learning) 기술이 강화학습과 결합된 것이 바로 딥 강화학습입니다. 딥러닝 모델(신경망)이 Q-함수나 정책 함수를 근사하여, 방대한 상태 공간을 효과적으로 처리할 수 있게 됩니다. 대표적인 예로는 구글 딥마인드의 알파고(AlphaGo)가 있으며, 이는 딥러닝과 강화학습의 시너지를 보여준 상징적인 사례입니다.
DQN(Deep Q-Network), A2C(Advantage Actor-Critic), PPO(Proximal Policy Optimization) 등 다양한 DRL 알고리즘들이 개발되어 로봇 제어, 자율주행, 복잡한 게임(스타크래프트, 도타 2 등)에서 인간을 뛰어넘는 성능을 보여주고 있습니다.
6.2. 멀티 에이전트 강화학습 (Multi-Agent Reinforcement Learning, MARL)
현실 세계의 많은 문제들은 단일 에이전트가 아닌, 여러 에이전트가 서로 상호작용하며 목표를 달성해야 하는 복잡한 시나리오를 가집니다. 예를 들어, 교통 흐름 제어, 로봇 축구, 여러 대의 드론 협업 등이 이에 해당합니다. 멀티 에이전트 강화학습은 이러한 다중 에이전트 시스템에서 각 에이전트가 협력하거나 경쟁하며 최적의 전략을 학습하는 방법을 연구합니다.
MARL은 각 에이전트의 관점, 정보 공유 방식, 보상 분배 등 고려해야 할 요소가 많아 단일 에이전트 강화학습보다 훨씬 어렵지만, 현실 세계 문제 해결에 필수적인 기술로 인식되고 있습니다.
6.3. 설명 가능한 강화학습 (Explainable Reinforcement Learning, XRL)
AI 기술의 발전과 함께 ‘블랙박스’ 문제에 대한 우려도 커지고 있습니다. 강화학습 에이전트가 왜 특정 행동을 선택했는지, 어떤 기준으로 판단했는지 알기 어렵다는 것이죠. 설명 가능한 강화학습(XRL)은 에이전트의 의사결정 과정을 인간이 이해할 수 있는 형태로 설명하려는 시도입니다.
이는 자율주행차와 같이 안전이 중요한 분야에서 에이전트의 신뢰성을 확보하고, 개발자가 에이전트의 오류를 진단하고 개선하는 데 큰 도움을 줄 것입니다. XRL은 2026년 이후 AI 윤리 및 책임 문제와 함께 더욱 중요해질 것으로 예상됩니다.
핵심 포인트
강화학습은 딥러닝과 결합된 딥 강화학습, 다중 에이전트 환경을 다루는 멀티 에이전트 강화학습, 그리고 에이전트의 의사결정을 설명하는 설명 가능한 강화학습 등의 방향으로 진화하며 그 적용 범위를 넓혀가고 있습니다.
7. 자주 묻는 질문 (FAQ)
Q. 강화학습을 시작하려면 어떤 배경지식이 필요한가요?
A. 파이썬 프로그래밍 기본, 선형대수학 및 미적분학의 기초, 그리고 확률 및 통계에 대한 이해가 있다면 강화학습 개념을 더 쉽게 이해할 수 있습니다. 하지만 본 포스팅처럼 실전 예제부터 시작하며 부족한 부분을 채워나가는 것도 좋은 방법입니다.
Q. OpenAI Gym 외에 다른 강화학습 환경 라이브러리도 있나요?
A. 네, 물론입니다. DeepMind의 PySC2 (스타크래프트 II 환경), Unity Technologies의 ML-Agents (Unity 게임 엔진 연동), Google Research의 Dopamine (다양한 Atari 게임 환경) 등 여러 훌륭한 라이브러리들이 있습니다.
Q. Q-Learning은 모든 강화학습 문제에 적용할 수 있나요?
A. Q-Learning은 이산적인 상태 및 행동 공간을 가진 문제에 매우 효과적입니다. 하지만 상태 공간이 매우 크거나 연속적인 경우에는 Q-Table을 만들 수 없어 적용하기 어렵습니다. 이럴 때는 딥러닝과 결합된 딥 강화학습(DRL) 알고리즘을 고려해야 합니다.
Q. 강화학습 하이퍼파라미터 튜닝은 어떻게 해야 하나요?
A. 학습률(α), 할인율(γ), 엡실론(ε) 등의 하이퍼파라미터는 에이전트 성능에 큰 영향을 미칩니다. 일반적으로 그리드 서치(Grid Search)나 랜덤 서치(Random Search)와 같은 방법을 통해 여러 조합을 시도해보고, 가장 좋은 성능을 보이는 값을 찾는 과정이 필요합니다. Bayesian Optimization과 같은 고급 튜닝 방법도 있습니다.
읽어주셔서 감사합니다
2026년 강화학습의 핵심 개념부터 파이썬을 활용한 실전 구현까지, AI 에이전트 개발의 첫걸음을 성공적으로 내디디셨기를 바랍니다. 강화학습은 미래 AI 기술의 핵심 동력이며, 꾸준한 학습과 실험을 통해 무궁무진한 가능성을 탐험할 수 있습니다.
궁금한 점이 있으면 언제든지 댓글로 남겨주세요. 권퓨터가 성심성의껏 답변해 드리겠습니다!