
요약
2026년 YOLOv8 시작 가이드: 나만의 객체 탐지 모델 뚝딱 만들기!
2026년 현재, 가장 빠르고 정확한 실시간 객체 탐지 모델 중 하나인 YOLOv8을 활용하여 나만의 AI 모델을 구축하는 실전 가이드입니다. 데이터 준비부터 모델 학습, 성능 평가, 그리고 실제 환경에서의 추론 및 배포 전략까지, 컴퓨터 비전 초보자도 쉽게 따라 할 수 있도록 자세히 분석합니다.
핵심 키워드: YOLOv8, 객체 탐지, AI 모델 구축
이 글의 순서
1 YOLOv8, 왜 지금 시작해야 할까요?
2 YOLOv8의 핵심 기술 분석 및 성능 비교
3 학습 시 마주할 수 있는 문제와 해결책
4 나만의 YOLOv8 모델 만들기 실전 가이드
5 자주 묻는 질문 (FAQ)
6 2026년, YOLOv8과 함께하는 AI의 미래
도입
YOLOv8, 왜 지금 시작해야 할까요?
2026년 현재, 인공지능 기술은 우리 삶의 거의 모든 영역에 스며들고 있습니다. 그중에서도 컴퓨터 비전(Computer Vision) 분야는 자율주행, 스마트 팩토리, 보안 감시, 의료 진단 등 실생활에 직접적인 영향을 미치며 눈부신 발전을 거듭하고 있습니다. 컴퓨터 비전의 핵심 기술 중 하나인 객체 탐지(Object Detection)는 이미지나 영상 속에서 특정 객체의 위치를 파악하고 어떤 객체인지 분류하는 역할을 합니다. 마치 인간의 눈처럼 사물을 인지하는 기술이라고 할 수 있습니다.
이러한 객체 탐지 기술의 최전선에는 YOLO(You Only Look Once) 시리즈가 있습니다. YOLO는 단 한 번의 네트워크 연산으로 객체 탐지를 수행하여 매우 빠른 속도를 자랑하며, 실시간 애플리케이션에 필수적인 요소로 자리 잡았습니다. 2016년 YOLOv1이 등장한 이래로, YOLO는 꾸준히 버전업을 거치며 성능과 편의성 모두를 혁신해왔습니다. 그리고 2023년에 등장한 YOLOv8은 이러한 YOLO 시리즈의 정점으로 평가받으며, 2026년인 지금도 많은 개발자와 연구자들에게 사랑받고 있습니다.
“YOLOv8은 속도와 정확성이라는 두 마리 토끼를 모두 잡으며, 실시간 객체 탐지의 새로운 표준을 제시하고 있습니다.”
— 권퓨터의 객체 탐지 모델 분석
그렇다면 왜 지금, 2026년에 YOLOv8을 주목해야 할까요? AI 모델의 발전 속도는 매우 빠르지만, YOLOv8은 그중에서도 뛰어난 범용성, 압도적인 성능, 그리고 개발자 친화적인 사용성을 바탕으로 여전히 강력한 입지를 다지고 있습니다. 특히 Ultralytics에서 제공하는 공식 라이브러리는 pip install ultralytics 한 줄로 설치하여 학습부터 추론, 배포까지 모든 과정을 손쉽게 처리할 수 있게 해줍니다. 이는 복잡한 딥러닝 프레임워크에 대한 깊은 이해 없이도 나만의 객체 탐지 모델을 만들 수 있는 기회를 제공합니다.
이 글에서는 YOLOv8의 기술적 특징을 심층 분석하고, 이전 버전들과의 비교를 통해 그 진가를 파악할 것입니다. 또한, 여러분이 직접 나만의 객체 탐지 모델을 만들 수 있도록 데이터 준비, 학습, 추론, 그리고 배포에 이르는 모든 과정을 단계별로 안내할 예정입니다. 지금부터 권퓨터와 함께 YOLOv8의 세계로 뛰어들어볼까요?
분석
YOLOv8의 핵심 기술 분석 및 성능 비교
YOLOv8은 이전 YOLO 시리즈의 성공적인 아키텍처를 계승하면서도, 여러 면에서 혁신적인 개선을 이루어냈습니다. 특히, Anchor-Free 방식의 도입과 새로운 백본 및 Neck 구조는 YOLOv8의 성능 향상에 크게 기여했습니다. 이 섹션에서는 YOLOv8의 주요 기술적 특징을 살펴보고, 이전 버전인 YOLOv5, YOLOv7과 비교하여 그 우수성을 분석합니다.
1. YOLOv8 아키텍처의 주요 개선점
YOLOv8은 다음과 같은 주요 아키텍처 개선을 통해 더 높은 정확도와 효율성을 달성했습니다.
YOLOv8 아키텍처 핵심
새로운 백본 네트워크 — Darknet-53 기반의 CSP(Cross Stage Partial) 구조를 더욱 효율적으로 개선하여, 특징 추출 능력을 극대화했습니다.
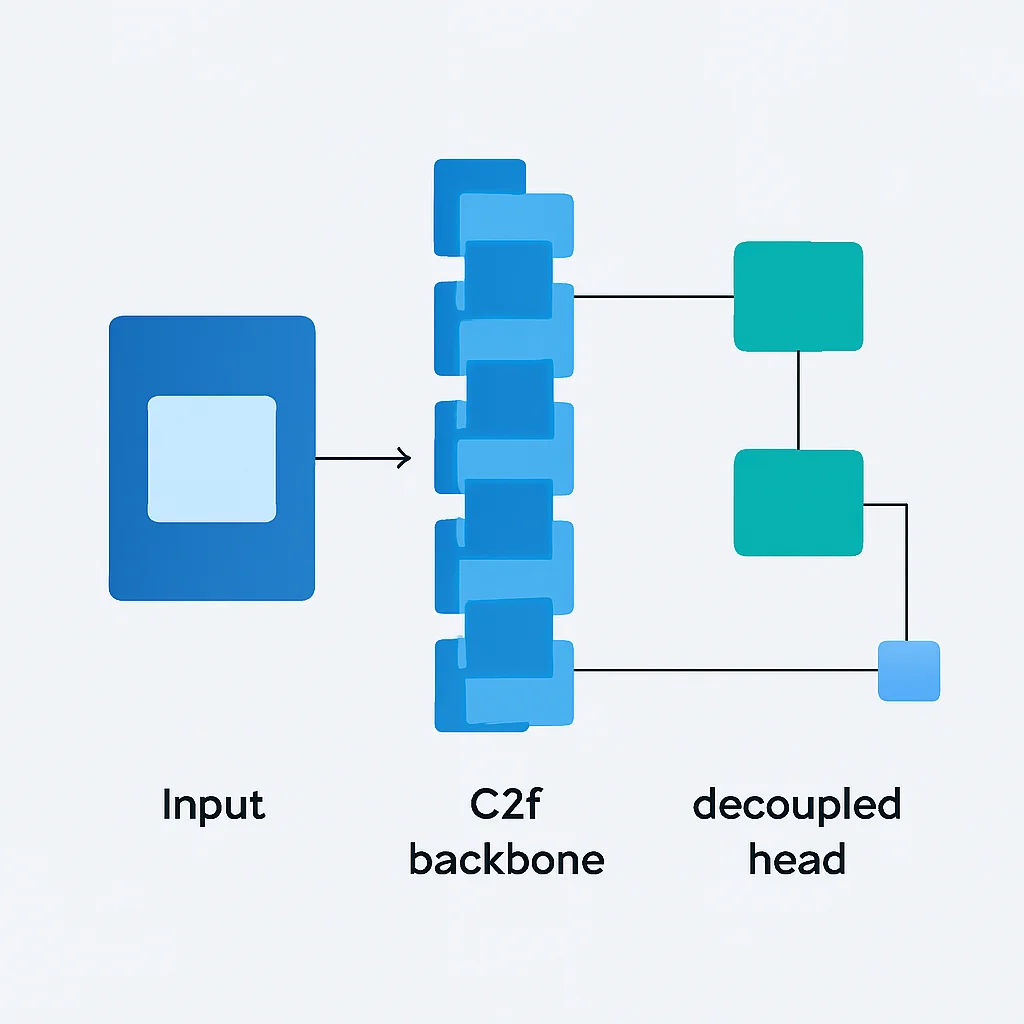
C2f 모듈 도입 — YOLOv7에서 사용된 ELAN 구조를 C2f(C3 with two bottlenecks) 모듈로 대체하여, 더 많은 그라디언트 정보를 유지하면서 경량화 및 고성능을 동시에 확보했습니다.
Anchor-Free Detection Head — 기존 YOLO 시리즈의 Anchor-Based 방식에서 벗어나, Anchor-Free 방식으로 변경되어 사전에 앵커 박스 크기를 정의할 필요 없이 직접 객체의 중심점과 너비/높이를 예측합니다. 이는 모델의 복잡성을 줄이고 일반화 성능을 향상시킵니다.
Decoupled Head — 분류(Classification)와 회귀(Regression) 태스크를 분리된 헤드에서 처리하여, 각 태스크의 최적화에 집중할 수 있도록 하여 성능을 더욱 끌어올렸습니다.
이러한 아키텍처 개선은 YOLOv8이 더 넓은 범위의 객체 크기를 효율적으로 탐지하고, 복잡한 배경 속에서도 정확도를 유지할 수 있도록 돕습니다. 특히 Anchor-Free 방식은 학습 과정에서 앵커 박스 최적화에 드는 시간을 절약하고, 다양한 데이터셋에 더 유연하게 적용될 수 있게 합니다.
2. YOLOv5, YOLOv7과의 성능 비교 (COCO 데이터셋 기준)
YOLOv8의 진가는 이전 버전들과의 비교를 통해 더욱 명확해집니다. 아래 표는 COCO(Common Objects in Context) 벤치마크 데이터셋에서 YOLOv5, YOLOv7, 그리고 YOLOv8의 주요 성능 지표를 비교한 것입니다. COCO 데이터셋은 80개의 객체 클래스를 포함하며, 객체 탐지 모델의 성능을 측정하는 데 널리 사용됩니다.
YOLO 시리즈 성능 비교 (COCO val2017)
| 모델 | mAP@50-95 (%) | mAP@50 (%) | FPS (V100) | 파라미터 수 (M) | 모델 크기 (MB) |
|---|---|---|---|---|---|
| YOLOv5l | 50.7 | 69.4 | 117 | 46.5 | 92.0 |
| YOLOv7 | 51.4 | 69.7 | 161 | 36.9 | 73.8 |
| YOLOv8l | 52.9 | 70.6 | 137 | 43.7 | 86.7 |
*mAP@50-95: IoU 임계값 0.5부터 0.95까지 0.05 간격으로 평균 낸 Mean Average Precision
*FPS: Frames Per Second, 초당 처리 가능한 프레임 수
위 표에서 확인할 수 있듯이, YOLOv8은 mAP(Mean Average Precision)에서 가장 높은 수치를 기록하며 정확도 면에서 우위를 점하고 있습니다. 특히, 실시간 처리 성능을 나타내는 FPS 또한 YOLOv7에 비해 약간 낮지만, 여전히 매우 뛰어난 수준을 유지하고 있어 대부분의 실시간 애플리케이션에 충분히 적용 가능합니다. 모델 크기 또한 합리적인 수준으로 유지되어 배포 용이성도 높습니다.
핵심 포인트
YOLOv8은 이전 세대 모델 대비 더 높은 정확도(mAP)를 달성하면서도, 실시간 처리 속도를 유지하고 모델 크기를 효율적으로 관리하여 전반적인 성능과 활용성에서 뛰어난 균형점을 제공합니다.
3. YOLOv8 모델 종류 (N, S, M, L, X) 및 선택 가이드
YOLOv8은 다양한 사용 환경과 요구사항에 맞춰 여러 크기의 모델을 제공합니다. 이는 nano(n), small(s), medium(m), large(l), extra large(x) 다섯 가지 버전으로 나뉩니다. 각 모델은 파라미터 수와 연산량이 다르며, 이에 따라 성능과 속도 간의 트레이드오프가 존재합니다.
YOLOv8 모델 종류별 특징
YOLOv8n (Nano) — 가장 작고 빠르지만 정확도는 상대적으로 낮습니다. 모바일 기기, 임베디드 시스템 등 리소스가 제한된 환경에 적합합니다. (예: 엣지 디바이스)
YOLOv8s (Small) — Nano보다 약간 크고 느리지만, 정확도가 향상됩니다. 대부분의 경량 애플리케이션에 좋은 균형점을 제공합니다.
YOLOv8m (Medium) — Small과 Large의 중간 단계로, 성능과 속도 모두 준수합니다. 일반적인 서버 환경에서 많이 사용됩니다.
YOLOv8l (Large) — 정확도가 매우 높지만, 연산량이 많아 속도가 느립니다. 고성능 GPU 환경에서 최고의 정확도를 요구할 때 적합합니다.
YOLOv8x (Extra Large) — 가장 크고 가장 정확하지만, 가장 느립니다. 최고 수준의 정확도가 필수적인 연구 및 분석 환경에 주로 사용됩니다.
모델 선택 시에는 여러분의 프로젝트 요구사항(정확도, 속도, 배포 환경의 리소스)을 고려해야 합니다. 예를 들어, 스마트폰 앱에 객체 탐지 기능을 넣고 싶다면 YOLOv8n 또는 YOLOv8s가 적합할 수 있고, CCTV 영상 분석처럼 높은 정확도가 필요하다면 YOLOv8l 또는 YOLOv8x를 고려할 수 있습니다.
문제 해결
학습 시 마주할 수 있는 문제와 해결책
아무리 강력한 YOLOv8 모델이라도, 학습 과정에서 다양한 문제에 직면할 수 있습니다. 특히 딥러닝 모델 학습은 데이터셋의 품질, 하이퍼파라미터 설정, 그리고 컴퓨팅 리소스에 크게 좌우됩니다. 여기서는 YOLOv8 모델 학습 시 흔히 발생하는 문제점들과 그에 대한 실질적인 해결책을 제시합니다.
문제 01
오버피팅 (Overfitting): 학습 데이터에만 과도하게 최적화
모델이 학습 데이터에는 높은 정확도를 보이지만, 실제 새로운 데이터(검증/테스트 데이터)에서는 성능이 급격히 떨어지는 현상입니다. 이는 모델이 학습 데이터의 노이즈까지 학습하여 일반화 능력을 잃었을 때 발생합니다.
해결 — 데이터 증강, 드롭아웃, Early Stopping
1. 데이터 증강 (Data Augmentation): 원본 이미지를 회전, 확대, 반전, 색상 조절하는 등 다양한 변형을 가하여 학습 데이터의 양을 인위적으로 늘립니다. YOLOv8은 기본적으로 다양한 데이터 증강 기법(Mosaic, MixUp 등)을 지원합니다. train() 함수에 augment=True 옵션을 사용하거나, YAML 설정 파일에서 직접 조절할 수 있습니다.
2. 드롭아웃 (Dropout) 및 정규화 (Regularization): 모델 학습 시 일부 뉴런을 무작위로 비활성화하여 모델이 특정 특징에 과도하게 의존하는 것을 방지합니다. 또한 L1/L2 정규화를 통해 가중치 값을 제한하여 모델의 복잡도를 줄일 수 있습니다. YOLOv8의 모델 설정에서 드롭아웃 비율을 조정할 수 있습니다.
3. Early Stopping: 검증 데이터셋에서의 성능(예: mAP)이 일정 에포크 동안 개선되지 않으면 학습을 조기에 중단합니다. 이는 불필요한 학습 시간 낭비를 막고 오버피팅을 방지하는 효과적인 방법입니다. YOLOv8은 patience 파라미터를 통해 Early Stopping을 설정할 수 있습니다.
문제 02
언더피팅 (Underfitting): 모델이 충분히 학습되지 못함
모델이 학습 데이터와 검증 데이터 모두에서 낮은 성능을 보이는 현상입니다. 이는 모델의 복잡도가 너무 낮거나, 학습 시간이 충분하지 않았을 때 발생합니다.
해결 — 모델 복잡도 증가, 학습 시간 연장
1. 모델 복잡도 증가: YOLOv8n(Nano)과 같은 작은 모델은 복잡한 데이터셋을 학습하기에 충분한 표현력을 갖추지 못할 수 있습니다. 이 경우 YOLOv8s, YOLOv8m, 또는 YOLOv8l과 같이 더 큰 모델을 사용해 보세요. 모델의 파라미터 수가 늘어나면서 데이터의 복잡한 패턴을 학습할 수 있는 능력이 향상됩니다.
2. 학습 시간 연장: 에포크(epoch) 수를 늘려 모델이 데이터를 더 많이 반복하여 학습하도록 합니다. 충분한 학습을 통해 모델이 데이터의 특징을 제대로 파악할 시간을 주어야 합니다. 단, 너무 많은 에포크는 오버피팅을 초래할 수 있으므로, 검증 성능을 모니터링하며 적절한 지점에서 학습을 중단하는 것이 중요합니다.
3. 학습률(Learning Rate) 조정: 너무 낮은 학습률은 학습 속도를 느리게 하여 언더피팅을 유발할 수 있습니다. 적절한 학습률을 사용하여 모델이 빠르게 최적의 가중치를 찾도록 도와야 합니다. 일반적으로 1e-3 ~ 1e-2 범위에서 시작하여 실험해 보는 것이 좋습니다.
문제 03
데이터 불균형 (Data Imbalance): 특정 클래스 데이터가 부족
학습 데이터셋 내에서 특정 객체 클래스의 이미지가 다른 클래스에 비해 현저히 적은 경우 발생합니다. 모델이 소수 클래스를 제대로 학습하지 못해 탐지 성능이 저하될 수 있습니다.
해결 — 데이터 수집, 클래스 가중치, 오버샘플링/언더샘플링
1. 추가 데이터 수집: 가장 근본적인 해결책은 부족한 클래스의 데이터를 더 많이 수집하는 것입니다. 직접 촬영하거나 공개된 데이터셋에서 유사한 이미지를 찾아 추가할 수 있습니다.
2. 클래스 가중치 (Class Weight): 학습 시 소수 클래스에 더 높은 가중치를 부여하여 모델이 해당 클래스를 더 중요하게 학습하도록 합니다. YOLOv8의 학습 설정 YAML 파일에서 class_weights 파라미터를 통해 조정할 수 있습니다.
3. 오버샘플링(Oversampling) 및 언더샘플링(Undersampling): 소수 클래스 데이터를 복제하거나(오버샘플링), 다수 클래스 데이터를 줄여서(언더샘플링) 데이터셋의 균형을 맞춥니다. 이는 데이터 전처리 단계에서 수행해야 하며, 데이터 증강 기법과 함께 사용하면 효과적입니다.
핵심 포인트
YOLOv8 학습의 성공은 데이터셋의 품질과 균형, 그리고 적절한 하이퍼파라미터 튜닝에 달려있습니다. 오버피팅, 언더피팅, 데이터 불균형은 흔한 문제이며, 위에서 제시된 해결책들을 조합하여 적용하는 것이 중요합니다.
실전 가이드
나만의 YOLOv8 모델 만들기 실전 가이드
이제 이론적인 내용을 바탕으로, 직접 나만의 YOLOv8 객체 탐지 모델을 만들어보는 실전 단계에 돌입할 시간입니다. 이 가이드에서는 데이터 준비부터 모델 학습, 추론, 그리고 간단한 배포까지의 과정을 상세히 안내합니다.
1. 개발 환경 설정
가장 먼저 필요한 개발 환경을 설정해야 합니다. Python 3.8 이상과 PyTorch가 설치되어 있어야 하며, GPU를 사용하려면 CUDA Toolkit이 필요합니다. Ultralytics YOLOv8 라이브러리는 pip를 통해 쉽게 설치할 수 있습니다.
코드 설명
Ultralytics 라이브러리를 설치하는 명령어입니다. -U 옵션은 최신 버전으로 업데이트한다는 의미이며, ultralytics[gpu]는 GPU 지원을 위한 추가 패키지를 함께 설치합니다 (GPU 환경이 아니라면 ultralytics만 설치해도 됩니다).
pip install -U ultralytics[gpu]2. 커스텀 데이터셋 준비 및 어노테이션
나만의 모델을 만들려면, 탐지하고자 하는 객체가 포함된 이미지와 그 객체의 위치를 표시한 어노테이션(Annotation) 파일이 필요합니다. YOLOv8은 YOLO 포맷의 어노테이션 파일을 사용합니다.
1
이미지 수집
탐지하고자 하는 객체가 다양한 환경, 각도, 조명 조건에서 촬영된 이미지를 충분히 수집합니다. 일반적으로 한 클래스당 최소 수십 장에서 수백 장 이상의 이미지가 권장됩니다.
2
어노테이션 도구 선택
LabelImg, Roboflow, CVAT 등 다양한 어노테이션 도구 중 하나를 선택하여 사용합니다. LabelImg는 로컬에서 사용하기 쉽고, Roboflow는 클라우드 기반으로 데이터셋 관리 및 증강 기능까지 제공합니다.
3
YOLO 포맷으로 어노테이션
각 이미지에 대해 객체의 바운딩 박스를 그리고 해당 클래스를 지정합니다. YOLO 포맷은 각 이미지(.jpg)마다 동일한 이름의 텍스트 파일(.txt)을 생성합니다. 이 텍스트 파일에는 [class_id] [center_x] [center_y] [width] [height] 형식의 정규화된 값이 한 줄에 하나씩 기록됩니다.


3. 데이터셋 분할 및 YAML 파일 설정
수집된 데이터셋은 학습(train), 검증(val), 테스트(test) 세트로 분할해야 합니다. 일반적으로 8:1:1 또는 7:2:1 비율로 분할하며, YOLOv8은 데이터셋 경로와 클래스 정보를 담은 YAML 설정 파일을 필요로 합니다.
코드 설명
데이터셋의 구조와 클래스 정보를 정의하는 YAML 파일 예시입니다. path는 데이터셋의 루트 경로, train, val, test는 각 데이터셋 이미지 경로를 지정합니다. nc는 클래스 수, names는 클래스 이름을 정의합니다. 이 파일을 my_dataset.yaml과 같은 이름으로 저장합니다.
# my_dataset.yaml
path: /path/to/your/dataset # 데이터셋 루트 경로
train: images/train # 학습 이미지 경로 (path 아래)
val: images/val # 검증 이미지 경로 (path 아래)
test: images/test # 테스트 이미지 경로 (path 아래, 선택 사항)
# 클래스 정보
nc: 2 # 클래스 수
names: ['apple', 'banana'] # 클래스 이름 목록 (순서 중요)4. YOLOv8 모델 학습
이제 준비된 데이터셋과 YAML 파일을 사용하여 YOLOv8 모델을 학습시킬 차례입니다. Ultralytics 라이브러리는 파이썬 스크립트 또는 CLI(Command Line Interface)를 통해 학습을 시작할 수 있습니다.
코드 설명
YOLOv8s 모델을 my_dataset.yaml 파일로 100 에포크 동안 학습시키는 파이썬 코드입니다. imgsz=640은 입력 이미지 크기를 640×640으로 설정하고, batch=16은 한 번에 16개의 이미지를 처리한다는 의미입니다. device=0은 첫 번째 GPU를 사용하도록 지정합니다 (CPU만 사용 시 device='cpu').
from ultralytics import YOLO
# YOLOv8s 모델 로드 (사전 학습된 가중치 사용)
model = YOLO('yolov8s.pt')
# 모델 학습
results = model.train(data='my_dataset.yaml', epochs=100, imgsz=640, batch=16, device=0) # GPU 사용 예시
5. 학습된 모델로 추론
학습이 완료되면, 모델은 runs/detect/train/weights/best.pt 경로에 저장됩니다. 이 가중치 파일을 사용하여 새로운 이미지나 비디오에서 객체를 탐지할 수 있습니다.
코드 설명
학습된 best.pt 파일을 로드하고, predict() 메서드를 사용하여 test_image.jpg 파일에서 객체를 탐지합니다. 탐지 결과는 바운딩 박스와 클래스 라벨이 그려진 이미지로 저장됩니다.
from ultralytics import YOLO
# 학습된 모델 로드
model = YOLO('runs/detect/train/weights/best.pt')
# 이미지에서 객체 탐지
results = model.predict('path/to/your/test_image.jpg', conf=0.25, iou=0.7, device=0) # conf는 신뢰도 임계값, iou는 IoU 임계값
# 결과 시각화 및 저장 (기본적으로 results/predict 폴더에 저장됨)
for r in results:
im_array = r.plot() # plot BGR numpy array of predictions
# cv2.imshow('Prediction', im_array)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# r.save('output_image.jpg') # 결과 이미지 저장6. 모델 배포 (ONNX, OpenVINO 변환)
학습된 YOLOv8 모델은 다양한 환경에 배포될 수 있도록 여러 포맷으로 변환할 수 있습니다. 특히 ONNX(Open Neural Network Exchange)와 OpenVINO는 효율적인 추론을 위해 널리 사용되는 포맷입니다.
코드 설명
학습된 YOLOv8 모델을 ONNX 포맷으로 변환하는 코드입니다. format='onnx' 옵션으로 변환할 포맷을 지정합니다. 이렇게 변환된 모델은 ONNX 런타임이 지원되는 모든 환경에서 사용할 수 있습니다.
from ultralytics import YOLO
# 학습된 모델 로드
model = YOLO('runs/detect/train/weights/best.pt')
# ONNX 포맷으로 변환
model.export(format='onnx')
# OpenVINO 포맷으로 변환 (Intel CPU/GPU 환경에 최적화)
# model.export(format='openvino')핵심 포인트
Ultralytics YOLOv8 라이브러리는 데이터 준비부터 학습, 추론, 그리고 다양한 포맷으로의 배포까지 모든 과정을 단순화된 API로 제공하여, 개발자들이 객체 탐지 모델을 쉽게 구축하고 활용할 수 있도록 돕습니다.
FAQ
자주 묻는 질문 (FAQ)
Q. YOLOv8은 어떤 환경에서 주로 사용되나요?
YOLOv8은 뛰어난 속도와 정확도를 바탕으로 자율주행, 보안 감시 시스템, 스마트 팩토리의 품질 검사, 의료 영상 분석, 드론을 이용한 농업 모니터링 등 실시간 객체 탐지가 필요한 다양한 산업 및 연구 분야에서 활용됩니다.
Q. YOLOv8 학습 시 GPU가 꼭 필요한가요?
네, 효율적인 YOLOv8 모델 학습을 위해서는 GPU(그래픽 처리 장치) 사용이 거의 필수적입니다. CPU로도 학습은 가능하지만, 처리 속도가 매우 느려 실용적이지 않습니다. NVIDIA GPU와 CUDA Toolkit 환경이 권장됩니다.
Q. 커스텀 데이터셋 구축 시 최소 몇 장의 이미지가 필요한가요?
일반적으로 클래스당 최소 100~1000장 이상의 이미지가 권장됩니다. 이미지 수가 많을수록 모델의 일반화 성능이 향상되지만, 데이터 증강 기법을 활용하면 적은 이미지로도 효과적인 학습이 가능합니다.
Q. YOLOv8 모델을 모바일 앱에 배포할 수 있나요?
네, 가능합니다. YOLOv8 모델은 ONNX, OpenVINO, TFLite 등 다양한 경량화된 포맷으로 변환할 수 있으며, 이를 통해 안드로이드나 iOS 모바일 앱에 통합하여 엣지 디바이스에서 실시간 추론을 수행할 수 있습니다.
Q. YOLOv8과 다른 객체 탐지 모델의 주요 차이점은 무엇인가요?
YOLOv8은 Anchor-Free 방식, C2f 모듈, Decoupled Head 등 최신 기술을 적용하여 이전 YOLO 시리즈 대비 정확도가 향상되었으며, Ultralytics의 통합 라이브러리로 사용 편의성이 매우 높습니다. Faster R-CNN과 같은 2단계 탐지기보다 빠르면서도 경쟁력 있는 정확도를 제공합니다.
마무리
2026년, YOLOv8과 함께하는 AI의 미래
지금까지 2026년 현재 가장 강력한 객체 탐지 모델 중 하나인 YOLOv8에 대해 깊이 있게 탐구하고, 여러분만의 모델을 구축하는 실전 가이드까지 살펴보았습니다. YOLOv8은 그 뛰어난 성능과 놀라운 사용 편의성을 바탕으로 컴퓨터 비전 분야의 새로운 가능성을 열어주고 있습니다.
YOLOv8의 Anchor-Free 아키텍처, C2f 모듈, 그리고 Decoupled Head와 같은 혁신적인 개선점들은 모델의 정확도를 한 단계 끌어올리면서도, 여전히 실시간 처리라는 YOLO 시리즈의 핵심 가치를 유지하고 있습니다. 이는 자율주행차의 보행자 인식, 스마트 시티의 교통 흐름 분석, 산업 현장의 불량품 검출 등 다양한 실생활 문제 해결에 더욱 정교하고 신뢰할 수 있는 솔루션을 제공합니다.
“YOLOv8은 단순한 객체 탐지 모델을 넘어, AI 시대를 이끌어갈 핵심 기술이자 무한한 창의성의 도구입니다.”
— 권퓨터
물론, 완벽한 모델은 없습니다. 데이터셋의 품질, 학습 환경, 그리고 하이퍼파라미터 튜닝은 여전히 모델 성능에 큰 영향을 미칩니다. 하지만 Ultralytics에서 제공하는 강력하고 직관적인 라이브러리 덕분에, 이러한 도전 과제들도 훨씬 수월하게 극복할 수 있게 되었습니다. 여러분은 이제 복잡한 딥러닝 이론에 얽매이지 않고도, 몇 줄의 코드로 자신만의 아이디어를 현실로 만들 수 있는 강력한 도구를 손에 넣은 것입니다.
핵심 포인트
2026년, YOLOv8은 객체 탐지 분야의 진입 장벽을 낮추고, 개발자들이 혁신적인 AI 애플리케이션을 창조할 수 있도록 돕는 핵심 기술로 자리매김하고 있습니다. 이제 여러분의 아이디어를 실현할 차례입니다!
앞으로도 YOLOv8은 더욱 발전하고 새로운 기능들을 추가하며 컴퓨터 비전 분야의 발전을 이끌어갈 것입니다. 권퓨터는 여러분이 이 글을 통해 YOLOv8에 대한 이해를 높이고, 직접 모델을 만들며 AI 기술의 재미와 가능성을 경험하시기를 진심으로 바랍니다. 궁금한 점이나 추가적으로 다루고 싶은 주제가 있다면 언제든지 댓글로 남겨주세요! 여러분의 AI 여정을 권퓨터가 응원합니다!
긴 글을 읽어주셔서 감사합니다!
YOLOv8을 통해 여러분만의 멋진 객체 탐지 모델을 만들어보세요. AI 기술은 생각보다 가까이에 있습니다.
궁금한 점이 있으면 댓글로 남겨주세요! 권퓨터가 성심성의껏 답변해 드리겠습니다.