

요약
[백엔드] Redis 캐싱 완벽 가이드 2026
느려진 API 응답 속도와 데이터베이스 부하, Redis 캐싱으로 획기적으로 개선하는 2026년 최신 전략을 소개합니다.
핵심 키워드: Redis, 캐싱, 성능 최적화
이 글의 순서
1. 배경: 왜 Redis 캐싱이 필수인가?
2. Redis, 너는 누구냐?
3. 핵심 캐싱 전략 파헤치기
4. Redis 데이터 구조와 캐싱 활용
5. 캐시 무효화와 만료 정책
6. Redis와 Memcached, 무엇이 다를까?
7. 캐싱 환경에서 마주하는 도전과 해결책
8. 실전! 백엔드 Redis 캐싱 구현 가이드
9. 자주 묻는 질문 (FAQ)
10. 마무리: Redis 캐싱, 미래를 위한 선택
배경
왜 Redis 캐싱이 필수인가?
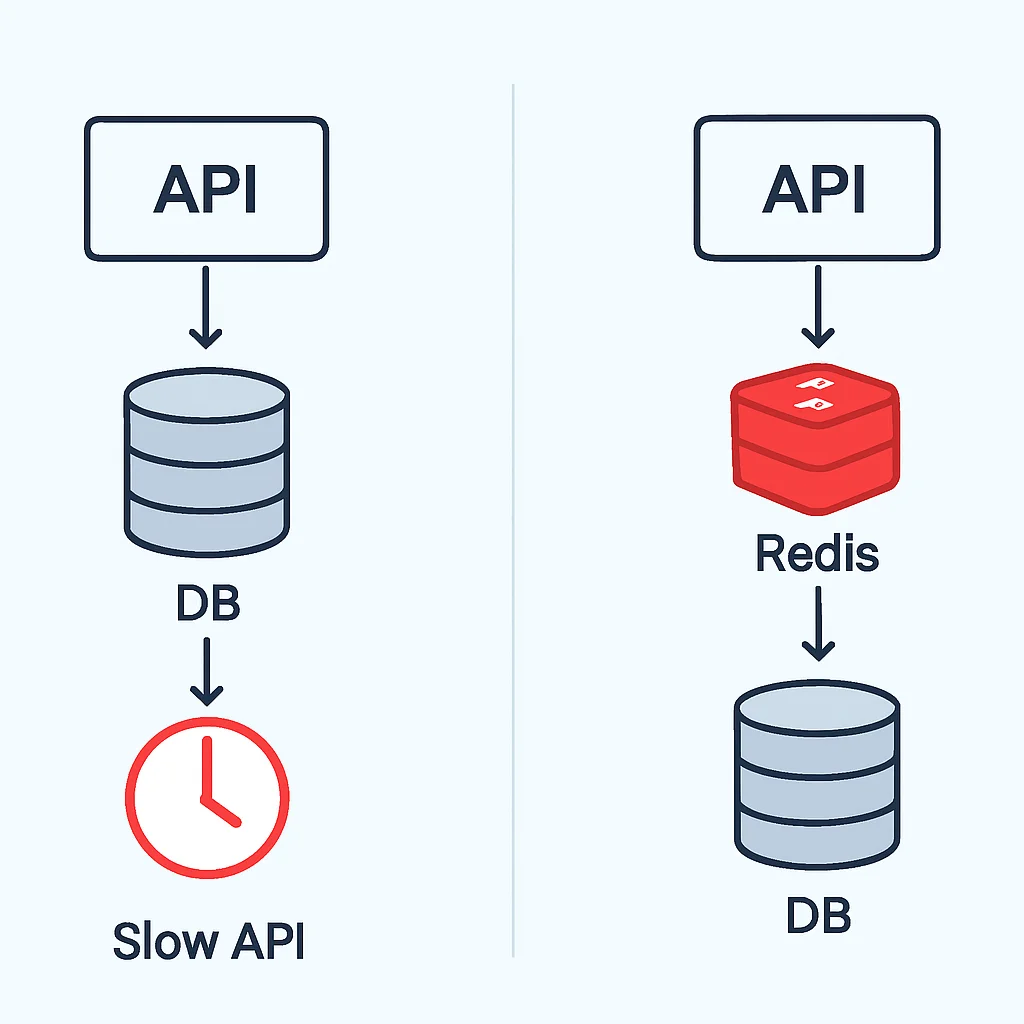
안녕하세요, 권퓨터입니다! 2026년 현재, 우리는 데이터의 홍수 속에서 살아가고 있습니다. 사용자들은 점점 더 빠른 응답 속도를 원하고, 서비스 규모가 커지면서 데이터베이스(DB)에 가해지는 부하는 상상을 초월합니다. 느려진 API 응답은 사용자 경험을 저해하고, 결국 서비스 이탈로 이어질 수 있죠. 아무리 멋진 기능을 구현해도, 느리다면 무슨 소용이 있을까요?
이러한 문제에 직면했을 때, 백엔드 개발자들이 가장 먼저 고려하는 해결책 중 하나가 바로 캐싱(Caching)입니다. 그리고 캐싱 솔루션의 선두 주자로서 Redis는 그 독보적인 성능과 유연성으로 수많은 서비스에서 핵심적인 역할을 하고 있습니다. Redis는 단순한 캐시를 넘어, 다양한 데이터 구조를 지원하는 인메모리 데이터 스토어로서 실시간 데이터 처리, 세션 관리, Pub/Sub 등 광범위한 활용성을 자랑합니다.
이 글에서는 Redis 캐싱이 왜 현대 백엔드 아키텍처에서 필수적인 요소가 되었는지, 그리고 2026년 기준 최적의 캐싱 전략과 실전 활용법을 권퓨터와 함께 자세히 파헤쳐 보겠습니다. 데이터베이스 부하를 줄이고 API 응답 속도를 극적으로 개선하여 사용자들에게 쾌적한 경험을 제공하는 마법 같은 Redis의 세계로 떠나볼까요?
핵심 포인트
현대 웹 서비스는 대량의 데이터와 트래픽으로 인해 데이터베이스 부하와 API 응답 속도 저하 문제를 겪습니다. Redis 캐싱은 이러한 문제를 해결하고 서비스 성능을 획기적으로 개선하는 핵심 기술입니다.
기본 개념
Redis, 너는 누구냐?
Redis(Remote Dictionary Server)는 인메모리(in-memory) 데이터 구조 스토어입니다. 데이터베이스, 캐시 및 메시지 브로커로 사용되며, BSD 라이선스 오픈 소스 프로젝트입니다. 일반적인 관계형 데이터베이스(RDB)나 NoSQL 데이터베이스가 데이터를 디스크에 저장하는 것과 달리, Redis는 메모리에 데이터를 저장하여 압도적인 읽기/쓰기 성능을 제공합니다.
Redis의 주요 특징
1. 인메모리 데이터 스토어
초고속 성능 — 데이터를 RAM에 저장하여 디스크 I/O 없이 밀리초(ms) 단위의 응답 속도를 보장합니다. 일반적인 데이터베이스가 수십~수백 ms의 응답 속도를 보이는 반면, Redis는 수백 마이크로초(µs) 수준의 응답 속도를 보여줍니다. 이는 초당 수십만 건의 요청을 처리할 수 있는 기반이 됩니다.
선택적 영속성 — 데이터를 메모리에 저장하지만, RDB(스냅샷)와 AOF(Append Only File) 방식을 통해 디스크에 데이터를 저장하여 서버 재시작 시 데이터 유실을 방지할 수 있습니다. 캐시 용도로만 사용할 경우 영속성을 비활성화하여 성능을 더욱 최적화할 수도 있습니다.
2. 다양한 데이터 구조 지원
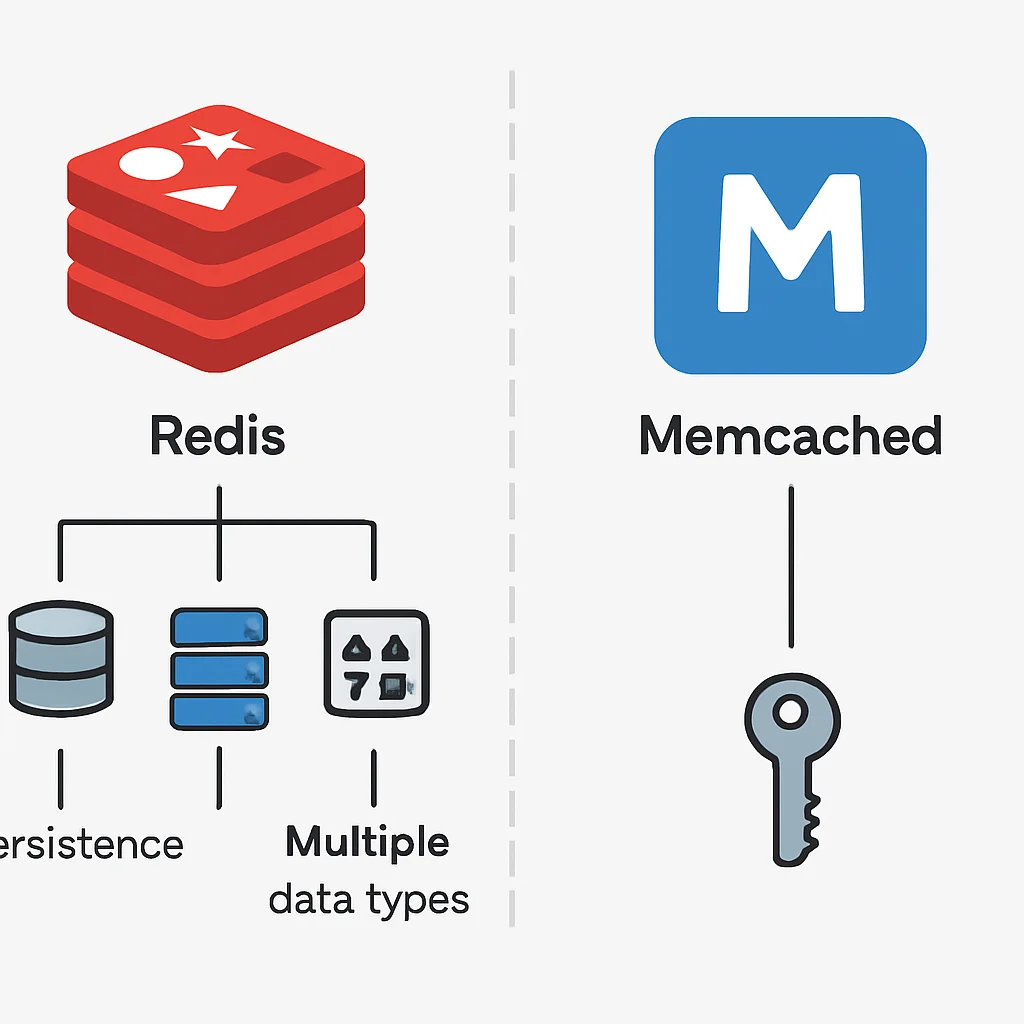
단순 Key-Value를 넘어 — String, Hash, List, Set, Sorted Set 등 5가지 핵심 데이터 구조와 함께 Geospatial, HyperLogLog, Stream 등 고급 데이터 구조를 지원하여 다양한 시나리오에 유연하게 대응할 수 있습니다. 이는 Memcached와 같은 다른 인메모리 캐시 솔루션과의 차별점입니다.
활용성 극대화 — 단순 캐싱뿐만 아니라 랭킹 시스템, 실시간 채팅, 분산 락, 세션 저장소 등 복잡한 기능을 Redis 하나로 구현할 수 있습니다.
3. 단일 스레드와 Non-Blocking I/O
경량화된 아키텍처 — Redis는 기본적으로 단일 스레드로 동작합니다. 이는 복잡한 락(lock) 메커니즘을 피하고 컨텍스트 스위칭 오버헤드를 줄여 높은 성능을 유지할 수 있게 합니다. 하지만 I/O 작업은 Non-Blocking 방식으로 처리하여 여러 클라이언트 요청을 동시에 효율적으로 처리합니다.
CPU 바운드 작업 주의 — 단일 스레드 특성상 CPU를 많이 사용하는 복잡한 명령어(예: 대용량 Set 연산)는 다른 요청의 처리를 지연시킬 수 있으므로 주의해야 합니다.
4. 고가용성 및 확장성
Master-Replica 복제 — 마스터 서버의 데이터를 여러 레플리카 서버에 복제하여 읽기 확장성을 높이고, 마스터 장애 시 레플리카가 마스터로 승격되어 서비스 연속성을 보장합니다.
Redis Sentinel — 마스터-레플리카 시스템의 고가용성을 관리하는 시스템으로, 장애 발생 시 자동으로 마스터를 교체(Failover)하고 클라이언트에게 새로운 마스터 정보를 알려줍니다.
Redis Cluster — 데이터를 여러 노드에 분산 저장(샤딩)하여 대규모 데이터를 처리하고, 쓰기 및 읽기 확장성을 극대화합니다. 샤딩된 각 노드는 자체적인 마스터-레플리카 구조를 가질 수 있습니다.
이러한 특징들 덕분에 Redis는 단순한 캐싱을 넘어, 실시간 분석, 게임 리더보드, 세션 저장, 메시지 큐 등 다양한 고성능 애플리케이션의 핵심 컴포넌트로 활용되고 있습니다. 다음 섹션에서는 Redis를 활용한 구체적인 캐싱 전략들을 살펴보겠습니다.
핵심 포인트
Redis는 인메모리 기반의 초고속 Key-Value 스토어이며, String, Hash, List, Set, Sorted Set 등 다양한 데이터 구조를 지원합니다. 단일 스레드와 Non-Blocking I/O로 고성능을 내며, 복제, Sentinel, Cluster를 통해 고가용성과 확장성을 확보합니다.
캐싱 전략
핵심 캐싱 전략 파헤치기
Redis를 효과적으로 사용하기 위해서는 애플리케이션의 특성에 맞는 캐싱 전략을 선택하는 것이 중요합니다. 주로 사용되는 네 가지 캐싱 전략을 살펴보겠습니다.
1. Cache-Aside (Lazy Loading)
“가장 일반적이고 유연한 캐싱 전략으로, 캐시와 데이터베이스를 애플리케이션 코드에서 직접 관리합니다.”
동작 방식:
1. 읽기 요청 시: 애플리케이션은 먼저 캐시에 데이터가 있는지 확인합니다.
2. 캐시 히트(Cache Hit): 데이터가 캐시에 있으면 즉시 반환합니다.
3. 캐시 미스(Cache Miss): 데이터가 캐시에 없으면 데이터베이스에서 데이터를 조회합니다.
4. 데이터베이스에서 가져온 데이터를 캐시에 저장하고, 사용자에게 반환합니다.
5. 쓰기 요청 시: 애플리케이션은 데이터베이스에 데이터를 먼저 쓰고, 캐시의 해당 데이터를 무효화(삭제)합니다.
장점: 구현이 비교적 간단하고, 캐시의 데이터는 필요한 경우에만 로드되므로 메모리를 효율적으로 사용합니다. 캐시 장애 시에도 데이터베이스에서 직접 데이터를 가져와 서비스를 지속할 수 있습니다.
단점: 캐시 미스 발생 시 첫 번째 요청은 데이터베이스를 거치므로 느립니다. 캐시 무효화 시 데이터베이스와 캐시 간의 일관성 문제가 발생할 수 있습니다.
2. Write-Through
“데이터를 쓸 때 캐시와 데이터베이스에 동시에 쓰는 전략입니다. 항상 캐시와 데이터베이스의 일관성을 유지합니다.”
동작 방식:
1. 애플리케이션은 캐시에 데이터를 씁니다.
2. 캐시는 데이터를 받은 즉시 데이터베이스에도 동일하게 씁니다.
3. 캐시와 데이터베이스 모두 쓰기 작업이 완료되면 애플리케이션에 응답을 반환합니다.
장점: 캐시와 데이터베이스 간의 데이터 일관성이 보장됩니다. 캐시에서 데이터를 읽을 때 항상 최신 데이터를 얻을 수 있습니다.
단점: 쓰기 작업이 캐시와 데이터베이스 모두에 이루어져야 하므로 Cache-Aside보다 쓰기 성능이 느립니다. 모든 쓰기 작업이 캐시를 거치므로 불필요한 데이터까지 캐시에 저장될 수 있습니다.
3. Write-Back (Write-Behind)
“데이터를 쓸 때 먼저 캐시에만 쓰고, 일정 시간 후 또는 특정 조건 만족 시 비동기적으로 데이터베이스에 쓰는 전략입니다.”
동작 방식:
1. 애플리케이션은 캐시에 데이터를 씁니다.
2. 캐시는 즉시 애플리케이션에 응답을 반환합니다.
3. 캐시는 나중에(비동기적으로) 데이터베이스에 데이터를 씁니다.
장점: 쓰기 성능이 매우 빠릅니다. 캐시가 여러 쓰기 작업을 배치(batch)로 묶어 데이터베이스에 한 번에 쓸 수 있어 데이터베이스 부하를 줄일 수 있습니다.
단점: 캐시 서버에 장애가 발생하면 데이터베이스에 아직 반영되지 않은 데이터가 유실될 위험이 있습니다. 데이터베이스와 캐시 간의 일관성이 일시적으로 깨질 수 있습니다.
4. Read-Through
“Cache-Aside와 유사하지만, 캐시 공급자(Cache Provider)가 데이터베이스에서 데이터를 가져오는 책임을 가집니다. 애플리케이션은 캐시만 바라봅니다.”
동작 방식:
1. 애플리케이션은 캐시 공급자에게 데이터를 요청합니다.
2. 캐시 공급자는 캐시에 데이터가 있는지 확인합니다.
3. 캐시 히트: 캐시 공급자가 캐시에서 데이터를 반환합니다.
4. 캐시 미스: 캐시 공급자가 데이터베이스에서 데이터를 조회합니다.
5. 데이터베이스에서 가져온 데이터를 캐시에 저장하고, 애플리케이션에 반환합니다.
장점: 애플리케이션 코드가 더 간결해지고, 캐싱 로직이 캐시 공급자에게 추상화되어 관리하기 쉽습니다. 주로 캐싱 프레임워크(예: Spring Cache)에서 많이 사용됩니다.
단점: 캐시 공급자의 구현이 복잡해질 수 있습니다. 캐시 공급자 장애 시 데이터 접근에 문제가 생길 수 있습니다.
각 전략은 장단점이 명확하므로, 서비스의 읽기/쓰기 비율, 데이터 일관성 요구 사항, 장애 허용치 등을 고려하여 가장 적합한 전략을 선택해야 합니다.
핵심 포인트
Cache-Aside는 가장 일반적이며, Write-Through는 데이터 일관성을 보장하지만 쓰기가 느립니다. Write-Back은 쓰기가 빠르지만 데이터 유실 위험이 있고, Read-Through는 캐싱 로직을 추상화하여 코드의 복잡성을 줄입니다.
데이터 구조
Redis 데이터 구조와 캐싱 활용
Redis의 강력함은 단순히 Key-Value 저장소를 넘어 다양한 데이터 구조를 지원한다는 점에 있습니다. 각 데이터 구조는 특정 캐싱 시나리오에 최적화되어 활용될 수 있습니다.
1. String (문자열)
“가장 기본적인 데이터 타입으로, 바이너리 안전한 문자열을 최대 512MB까지 저장할 수 있습니다.”
캐싱 활용: 웹 페이지 캐시, 사용자 세션 토큰, API 응답 JSON, 이미지/파일의 바이너리 데이터 등 단일 값 형태의 데이터를 캐싱할 때 주로 사용됩니다. 특정 게시글의 전체 내용을 JSON 형태로 저장하고 캐싱하는 것이 대표적인 예시입니다.
주요 명령어: SET key value, GET key, SETEX key seconds value (TTL 포함 설정)
2. Hash (해시)
“필드-값 쌍으로 이루어진 객체를 저장하는 데 사용됩니다. 하나의 키 아래 여러 개의 필드를 관리할 수 있습니다.”
캐싱 활용: 사용자 프로필 정보(이름, 이메일, 주소 등), 제품 상세 정보(이름, 가격, 재고 등), 세션 데이터 등 여러 필드를 가진 객체를 캐싱할 때 효율적입니다. 각 필드를 개별적으로 업데이트하거나 조회할 수 있습니다.
주요 명령어: HSET key field value, HGET key field, HGETALL key
3. List (리스트)
“삽입된 순서대로 정렬되는 문자열 요소들의 컬렉션입니다. 양쪽 끝에서 O(1) 시간 복잡도로 요소를 추가/삭제할 수 있습니다.”
캐싱 활용: 최근 방문한 페이지 목록, 사용자 알림 목록, 실시간 로그, 메시지 큐 등 순서가 중요한 데이터를 캐싱할 때 유용합니다. LPUSH와 RPOP을 사용하여 큐(Queue) 또는 스택(Stack)처럼 활용할 수 있습니다.
주요 명령어: LPUSH key value [value ...], RPOP key, LRANGE key start stop
4. Set (셋)
“중복되지 않는 유일한 문자열 요소들의 컬렉션입니다. 순서는 보장되지 않습니다.”
캐싱 활용: 특정 게시글에 ‘좋아요’를 누른 사용자 ID 목록, 태그 목록, 친구 목록, 온라인 사용자 목록 등 중복을 허용하지 않는 유일한 값들의 집합을 캐싱할 때 사용됩니다. 합집합, 교집합, 차집합 연산을 빠르게 수행할 수 있습니다.
주요 명령어: SADD key member [member ...], SMEMBERS key, SISMEMBER key member
5. Sorted Set (정렬된 셋)
“중복되지 않는 유일한 문자열 요소들과 각 요소에 연결된 점수(score)를 가집니다. 점수를 기준으로 정렬됩니다.”
캐싱 활용: 게임 리더보드, 인기 게시물 목록(조회수 기준), 실시간 랭킹, 점수 기반의 추천 목록 등 순서와 점수가 중요한 데이터를 캐싱할 때 이상적입니다. 특정 범위의 점수를 가진 요소를 빠르게 조회할 수 있습니다.
주요 명령어: ZADD key score member [score member ...], ZRANGE key start stop [WITHSCORES], ZINCRBY key increment member
이처럼 Redis의 다양한 데이터 구조를 이해하고 적절히 활용하면, 단순한 캐싱을 넘어 애플리케이션의 복잡한 요구사항을 효과적으로 해결할 수 있습니다. 각 데이터 구조의 특성을 고려하여 캐싱할 데이터의 형태와 접근 패턴에 맞게 선택하는 것이 중요합니다.
핵심 포인트
Redis는 String, Hash, List, Set, Sorted Set 등 다양한 데이터 구조를 지원하며, 각 구조는 웹 페이지 캐싱, 사용자 프로필, 최근 목록, 고유 사용자 관리, 랭킹 시스템 등 특정 캐싱 시나리오에 최적화되어 활용될 수 있습니다.
정책
캐시 무효화와 만료 정책
캐싱에서 가장 중요한 부분 중 하나는 캐시의 데이터를 언제, 어떻게 만료시키고 무효화할 것인가입니다. 오래된(stale) 데이터는 잘못된 정보를 제공하여 서비스 신뢰도를 떨어뜨릴 수 있기 때문입니다. Redis는 이를 위한 다양한 정책을 제공합니다.
1. TTL (Time To Live)
“데이터가 캐시에 저장된 후 일정 시간이 지나면 자동으로 만료되도록 설정하는 정책입니다.”
설명: Redis의 가장 기본적인 만료 정책으로, 각 키에 대해 만료 시간을 초 단위로 설정할 수 있습니다. EXPIRE key seconds 명령어를 사용하거나, SETEX key seconds value 명령어로 값을 설정과 동시에 만료 시간을 지정할 수 있습니다.
활용: 변경 빈도가 높지 않거나, 약간의 지연된 데이터 일관성이 허용되는 데이터(예: 인기 게시물 목록, 뉴스 피드), 사용자 세션 정보 등에 적합합니다. 예를 들어, 특정 API의 응답 결과를 5분 동안 캐싱하고 싶다면 TTL을 300초로 설정할 수 있습니다.
2. Eviction Policies (메모리 부족 시 데이터 삭제 정책)
Redis 서버의 메모리가 설정된 maxmemory 한계에 도달했을 때, Redis는 어떤 데이터를 삭제할지 결정해야 합니다. 이는 maxmemory-policy 설정으로 제어됩니다.
volatile-lru / allkeys-lru (Least Recently Used)
설명: 가장 최근에 사용되지 않은(가장 오래된) 데이터를 삭제합니다. volatile-lru는 만료 시간이 설정된 키 중에서 LRU 정책을 따르고, allkeys-lru는 모든 키 중에서 LRU 정책을 따릅니다.
활용: 대부분의 캐싱 시나리오에 적합합니다. 자주 접근되는 데이터는 캐시에 유지하고, 사용 빈도가 낮은 오래된 데이터를 자동으로 제거하여 캐시 효율을 높입니다.
volatile-lfu / allkeys-lfu (Least Frequently Used)
설명: 가장 적게 사용된(접근 빈도가 낮은) 데이터를 삭제합니다. volatile-lfu는 만료 시간이 설정된 키 중에서 LFU 정책을 따르고, allkeys-lfu는 모든 키 중에서 LFU 정책을 따릅니다.
활용: LRU보다 더 효율적으로 ‘인기 있는’ 데이터를 유지할 수 있습니다. 예를 들어, 한 번 사용되고 오랫동안 사용되지 않는 데이터가 캐시에 남아있는 경우, LFU는 이를 LRU보다 먼저 제거할 가능성이 높습니다.
volatile-random / allkeys-random
설명: 무작위로 키를 삭제합니다. 마찬가지로 volatile-random은 만료 시간이 설정된 키 중에서, allkeys-random은 모든 키 중에서 무작위로 삭제합니다.
활용: 특별한 우선순위 없이 캐시를 비워야 할 때 사용되지만, 일반적으로 LRU나 LFU보다 효율성이 떨어집니다.
volatile-ttl
설명: 만료 시간이 가장 적게 남은 키부터 삭제합니다. 즉, 만료될 예정인 키들을 우선적으로 제거합니다.
noeviction
설명: 메모리가 가득 차면 더 이상 쓰기 작업을 허용하지 않고 오류를 반환합니다. 캐시가 아닌 데이터베이스로 Redis를 사용할 때 데이터 유실을 막기 위해 사용될 수 있습니다.
일반적으로 캐싱 용도로 Redis를 사용할 때는 allkeys-lru 또는 allkeys-lfu 정책을 가장 많이 사용합니다. 서비스의 데이터 접근 패턴을 분석하여 가장 효율적인 정책을 선택하는 것이 중요합니다.
핵심 포인트
TTL은 특정 데이터의 만료 시간을 설정하며, Eviction Policies는 메모리 부족 시 데이터를 삭제하는 전략입니다. LRU와 LFU는 가장 효율적인 정책으로 널리 사용되며, 서비스의 접근 패턴에 따라 적절한 정책을 선택해야 합니다.
비교 분석
Redis와 Memcached, 무엇이 다를까?
Redis와 Memcached는 모두 널리 사용되는 오픈 소스 인메모리 캐싱 시스템입니다. 둘 다 매우 빠르고 확장성이 뛰어나지만, 내부 아키텍처와 기능 면에서 중요한 차이점이 있습니다. 어떤 상황에 어떤 솔루션이 더 적합한지 비교해 보겠습니다.
Redis vs. Memcached 비교
| 특징 | Redis | Memcached |
|---|---|---|
| 데이터 구조 | String, Hash, List, Set, Sorted Set 등 다양 | 단순 String (Key-Value) |
| 영속성 | RDB(스냅샷), AOF(로그)를 통한 영속성 지원 | 영속성 지원 안 함 (Pure Cache) |
| 복제 (Replication) | Master-Replica 복제 지원 (읽기 확장성, 고가용성) | 내장 복제 기능 없음 (클라이언트가 직접 처리) |
| 클러스터링 | Redis Cluster를 통한 자동 샤딩 및 Failover | 클라이언트 라이브러리를 통해 분산 구현 |
| 트랜잭션 | MULTI/EXEC 명령을 통한 트랜잭션 지원 | 트랜잭션 지원 안 함 |
| Pub/Sub | 메시지 발행/구독 모델 지원 | 지원 안 함 |
| 메모리 관리 | 다양한 Eviction 정책 (LRU, LFU, TTL 등) | LRU 기반의 단순 Eviction 정책 |
| 사용 사례 | 복합 캐싱, 세션 저장소, 랭킹, 실시간 데이터, 큐, 분산 락 | 단순 객체 캐싱, 메모리 캐싱 |
결론:
Memcached는 단순한 Key-Value 캐싱에 특화되어 있으며, 매우 높은 처리량과 낮은 지연 시간을 제공합니다. 만약 애플리케이션이 오직 단순한 객체 캐싱만을 필요로 한다면, Memcached는 여전히 좋은 선택일 수 있습니다. 설정과 사용이 간단하다는 장점도 있습니다.
반면 Redis는 단순 캐싱을 넘어선 다양한 기능을 제공하는 데이터 구조 서버입니다. 복잡한 데이터 구조, 영속성, 복제, 트랜잭션, Pub/Sub 등 강력한 기능을 내장하고 있어, 단순 캐싱을 넘어 세션 관리, 실시간 랭킹, 메시지 큐 등 다양한 용도로 활용될 수 있습니다. 2026년 현재 대부분의 현대적인 백엔드 아키텍처에서는 Redis의 다재다능함 때문에 Memcached보다 Redis를 선호하는 경향이 더욱 강해지고 있습니다.
핵심 포인트
Memcached는 단순 객체 캐싱에 최적화된 반면, Redis는 다양한 데이터 구조, 영속성, 복제, 트랜잭션, Pub/Sub 등 다채로운 기능을 제공하여 복합적인 데이터 처리 및 캐싱 요구사항에 더 적합합니다.
문제 해결
캐싱 환경에서 마주하는 도전과 해결책
Redis 캐싱은 성능 최적화에 강력한 도구이지만, 잘못 사용하면 오히려 복잡성을 증가시키고 새로운 문제를 야기할 수 있습니다. 캐싱 환경에서 흔히 마주치는 도전 과제와 그 해결책을 알아보겠습니다.
문제 01
캐시 일관성 (Cache Coherency) 문제
데이터베이스의 데이터가 변경되었는데 캐시의 데이터는 업데이트되지 않아 오래된(stale) 데이터를 제공하는 문제입니다. 이는 사용자에게 잘못된 정보를 전달할 수 있습니다.
해결 — 캐시 무효화 전략 및 TTL
TTL (Time To Live) 적용: 모든 캐시 데이터에 적절한 만료 시간을 설정하여 오래된 데이터가 자동으로 제거되도록 합니다. 데이터 변경 빈도에 따라 TTL을 조정합니다.
Write-Through 또는 Cache-Aside with Invalidation: 데이터를 업데이트할 때 데이터베이스에 먼저 반영하고, 캐시에 있는 해당 데이터를 즉시 무효화(삭제)합니다. 다음 읽기 요청 시 데이터베이스에서 최신 데이터를 가져와 캐시를 다시 채웁니다.
Pub/Sub을 이용한 분산 캐시 무효화: 마이크로서비스 환경에서는 데이터 변경 이벤트를 발행하고, 관련 캐시를 가진 서비스들이 이 이벤트를 구독하여 캐시를 무효화하는 방식으로 일관성을 유지할 수 있습니다.

문제 02
캐시 부재 (Cache Miss) 및 Thundering Herd
캐시에 데이터가 없어 데이터베이스로 요청이 전달되는 상황을 캐시 미스라고 합니다. 특히 캐시가 만료되거나 초기화된 직후, 수많은 요청이 동시에 캐시 미스를 일으켜 데이터베이스에 엄청난 부하를 주는 현상을 ‘Thundering Herd’라고 합니다.
해결 — 캐시 워밍업 및 분산 락
캐시 워밍업 (Cache Warming): 서비스 시작 또는 캐시 초기화 시, 미리 자주 사용될 데이터를 캐시에 로드하여 캐시 미스율을 낮춥니다.
분산 락 (Distributed Lock): 캐시 미스 발생 시, 여러 애플리케이션 인스턴스가 동시에 데이터베이스로 접근하는 것을 방지하기 위해 Redis의 SETNX (Set if Not eXists) 명령어를 사용하여 분산 락을 구현합니다. 첫 번째 요청만 데이터베이스에 접근하고, 다른 요청들은 락이 해제될 때까지 대기하거나 캐시가 채워지기를 기다립니다.
코드 설명
아래 파이썬 코드는 Redis를 이용한 분산 락 구현 예시입니다. SETNX는 키가 존재하지 않을 때만 값을 설정하며, 락 획득에 성공하면 True를 반환합니다. 락 해제를 위해 DEL을 사용합니다.
import redis
import time
# Redis 클라이언트 연결
r = redis.Redis(host='localhost', port=6379, db=0)
def acquire_lock(lock_name, acquire_timeout=10, lock_timeout=10):
identifier = str(uuid.uuid4()) # 고유한 락 식별자
lock_timeout = int(lock_timeout)
end_time = time.time() + acquire_timeout
while time.time() < end_time:
# SETNX로 락 획득 시도 (키가 없을 경우에만 설정)
if r.setnx(lock_name, identifier):
# 락 획득 성공, 만료 시간 설정
r.expire(lock_name, lock_timeout)
return identifier
# 락이 이미 존재하면 만료 시간 확인
elif not r.ttl(lock_name):
# 만료 시간이 없으면 락이 걸린 채로 멈춘 경우이므로 다시 설정
r.expire(lock_name, lock_timeout)
time.sleep(0.001) # 짧은 대기 후 재시도
return False
def release_lock(lock_name, identifier):
pipe = r.pipeline(True)
while True:
try:
pipe.watch(lock_name) # 락 키 감시
if pipe.get(lock_name).decode('utf-8') == identifier:
pipe.multi()
pipe.delete(lock_name) # 락 해제
pipe.execute()
return True
pipe.unwatch()
break
except redis.exceptions.WatchError:
pass # 락 키가 중간에 변경되었으므로 재시도
return False
# 사용 예시
import uuid
lock_name = "my_resource_lock"
print(f"락 획득 시도: {lock_name}")
lock_id = acquire_lock(lock_name)
if lock_id:
print(f"락 획득 성공! ID: {lock_id}")
try:
# 보호된 자원 접근 로직
print("중요한 작업 수행 중...")
time.sleep(2)
print("작업 완료.")
finally:
if release_lock(lock_name, lock_id):
print(f"락 해제 성공! ID: {lock_id}")
else:
print(f"락 해제 실패! ID: {lock_id}")
else:
print(f"락 획득 실패! 다른 프로세스가 작업 중입니다.")
문제 03
메모리 관리 및 Redis 장애 대응
Redis는 인메모리 기반이므로 메모리 사용량을 효율적으로 관리해야 합니다. 또한, Redis 서버 자체에 장애가 발생했을 때 서비스 중단 없이 대응하는 것이 중요합니다.
해결 — Eviction 정책, 복제, Sentinel, Cluster
적절한 Eviction 정책 설정: maxmemory와 maxmemory-policy를 설정하여 메모리가 부족할 때 어떤 데이터를 자동으로 삭제할지 결정합니다. 일반적으로 allkeys-lru 또는 allkeys-lfu를 사용합니다.
Master-Replica 복제: 마스터 Redis 서버의 데이터를 여러 레플리카 서버에 복제하여 읽기 트래픽을 분산하고, 마스터 장애 시 레플리카가 대체할 수 있도록 합니다.
Redis Sentinel: 마스터-레플리카 시스템의 고가용성을 자동으로 관리합니다. 마스터 장애 시 자동으로 레플리카 중 하나를 새로운 마스터로 승격시키고, 클라이언트에게 새로운 마스터 정보를 알려줍니다.
Redis Cluster: 대규모 데이터와 높은 트래픽을 처리하기 위해 데이터를 여러 노드에 분산(샤딩)하고, 각 노드에 대한 자동 Failover 기능을 제공합니다. 수평 확장이 가능해집니다.
핵심 포인트
캐시 일관성은 TTL, 무효화 전략, Pub/Sub으로 해결하고, 캐시 미스 및 Thundering Herd는 캐시 워밍업과 분산 락으로 방지합니다. 메모리 관리는 Eviction 정책으로, 장애 대응은 복제, Sentinel, Cluster를 통해 고가용성을 확보합니다.
실전 적용
실전! 백엔드 Redis 캐싱 구현 가이드
이제 Redis 캐싱을 실제 백엔드 애플리케이션에 어떻게 적용하는지 파이썬(Flask)과 자바(Spring Boot) 예시를 통해 살펴보겠습니다. 여기서는 Cache-Aside 전략을 기반으로 구현합니다.
1. 파이썬 (Flask) + Redis 캐싱 예시
Flask는 경량 웹 프레임워크로, Redis 클라이언트 라이브러리인 redis-py를 사용하여 쉽게 Redis를 통합할 수 있습니다.
사전 준비: 라이브러리 설치
터미널에서 다음 명령어를 실행하여 필요한 라이브러리를 설치합니다.
pip install Flask redis캐싱 API 구현 (app.py)
코드 설명
이 코드는 Flask 애플리케이션에서 Redis를 캐시로 사용하는 예시입니다. /posts/<post_id> 엔드포인트는 먼저 Redis 캐시에서 게시물 데이터를 찾습니다. 데이터가 없으면 데이터베이스(여기서는 더미 함수)에서 가져온 후 Redis에 저장하고 60초의 TTL을 설정합니다. /posts 엔드포인트는 새로운 게시물을 생성하고, 해당 게시물의 캐시를 무효화합니다.
from flask import Flask, jsonify, request
import redis
import json
import time
app = Flask(__name__)
# Redis 클라이언트 초기화 (기본 localhost:6379)
# 실제 환경에서는 Redis 서버의 IP와 포트를 설정해야 합니다.
redis_client = redis.StrictRedis(host='localhost', port=6379, db=0)
# 더미 데이터베이스 (실제 DB 연동을 시뮬레이션)
# 이 데이터는 Redis 캐시가 비어 있을 때 사용됩니다.
DATABASE = {
1: {"id": 1, "title": "Redis 캐싱의 힘", "content": "Redis로 API 성능을 개선하는 방법입니다.", "author": "권퓨터"},
2: {"id": 2, "title": "파이썬 Flask와 Redis", "content": "간단한 Flask 앱에 Redis를 적용해봅시다.", "author": "권퓨터"},
3: {"id": 3, "title": "캐싱 전략 깊이 탐구", "content": "Cache-Aside, Write-Through 등을 알아봅니다.", "author": "김개발"},
}
next_post_id = 4 # 다음 게시물 ID
# 더미 데이터베이스에서 게시물 조회 함수 (느린 DB 작업 시뮬레이션)
def get_post_from_db(post_id):
time.sleep(0.5) # DB 조회에 0.5초 소요 가정
return DATABASE.get(post_id)
@app.route('/posts/<int:post_id>', methods=['GET'])
def get_post(post_id):
# 1. Redis 캐시에서 데이터 조회 시도
cache_key = f"post:{post_id}"
cached_post = redis_client.get(cache_key)
if cached_post:
print(f"DEBUG: Cache Hit for {cache_key}")
return jsonify(json.loads(cached_post)), 200
# 2. 캐시 미스: 데이터베이스에서 조회
print(f"DEBUG: Cache Miss for {cache_key}. Fetching from DB.")
post = get_post_from_db(post_id)
if not post:
return jsonify({"message": "게시물을 찾을 수 없습니다."}), 404
# 3. 데이터베이스에서 가져온 데이터를 Redis 캐시에 저장 (TTL 60초)
redis_client.setex(cache_key, 60, json.dumps(post)) # 60초 TTL 설정
print(f"DEBUG: Stored {cache_key} in cache with 60s TTL.")
return jsonify(post), 200
@app.route('/posts', methods=['POST'])
def create_post():
global next_post_id
data = request.get_json()
if not data or 'title' not in data or 'content' not in data:
return jsonify({"message": "제목과 내용을 입력해주세요."}), 400
new_post = {
"id": next_post_id,
"title": data['title'],
"content": data['content'],
"author": data.get('author', '익명')
}
DATABASE[next_post_id] = new_post
# 새로운 게시물 생성 후, 해당 게시물의 캐시 무효화 (만약 캐싱되어 있다면)
cache_key = f"post:{next_post_id}"
redis_client.delete(cache_key)
print(f"DEBUG: Cache invalidated for {cache_key} after creation.")
next_post_id += 1
return jsonify(new_post), 201
@app.route('/posts/<int:post_id>', methods=['PUT'])
def update_post(post_id):
data = request.get_json()
if not data:
return jsonify({"message": "수정할 내용을 입력해주세요."}), 400
if post_id not in DATABASE:
return jsonify({"message": "게시물을 찾을 수 없습니다."}), 404
# 데이터베이스 업데이트
DATABASE[post_id].update(data)
# 캐시 무효화
cache_key = f"post:{post_id}"
redis_client.delete(cache_key)
print(f"DEBUG: Cache invalidated for {cache_key} after update.")
return jsonify(DATABASE[post_id]), 200
@app.route('/posts/<int:post_id>', methods=['DELETE'])
def delete_post(post_id):
if post_id not in DATABASE:
return jsonify({"message": "게시물을 찾을 수 없습니다."}), 404
del DATABASE[post_id]
# 캐시 무효화
cache_key = f"post:{post_id}"
redis_client.delete(cache_key)
print(f"DEBUG: Cache invalidated for {cache_key} after deletion.")
return jsonify({"message": "게시물이 삭제되었습니다."}), 204
if __name__ == '__main__':
app.run(debug=True, port=5000)
실행 방법:
1. Redis 서버를 실행합니다 (redis-server).
2. python app.py 명령어로 Flask 앱을 실행합니다.
3. curl이나 Postman 등으로 http://localhost:5000/posts/1에 요청을 보내면서 캐시 히트/미스를 확인해 보세요.
핵심 포인트
파이썬 Flask에서 Redis 캐싱을 구현할 때는 redis-py 라이브러리를 사용하며, Cache-Aside 패턴을 적용하여 읽기 시 캐시 확인, 쓰기 시 캐시 무효화를 수행합니다. setex로 TTL을 설정하여 데이터의 신선도를 유지하는 것이 중요합니다.
2. 자바 (Spring Boot) + Redis 캐싱 예시
Spring Boot는 Spring Data Redis와 @Cacheable 등의 어노테이션을 통해 Redis 캐싱을 매우 편리하게 사용할 수 있도록 지원합니다.
사전 준비: 의존성 추가 (pom.xml 또는 build.gradle)
Spring Initializr에서 Spring Web, Spring Data Redis, Lombok 의존성을 추가합니다. pom.xml 예시:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
Redis 설정 (application.properties)
spring.redis.host=localhost
spring.redis.port=6379
# spring.redis.password=your_password (비밀번호가 있다면)
캐싱 활성화 및 설정 (RedisConfig.java)
코드 설명
이 설정 클래스는 Spring Boot 애플리케이션에서 캐싱 기능을 활성화하고, Redis 캐시 매니저를 구성합니다. @EnableCaching 어노테이션은 캐싱 기능을 켜고, RedisCacheConfiguration을 통해 캐시의 기본 만료 시간(TTL)과 키/값 직렬화 방식을 설정합니다. 여기서는 1분(60초)의 TTL을 설정했습니다.
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import java.time.Duration;
@Configuration
@EnableCaching
public class RedisConfig {
@Bean
public CacheManager cacheManager(RedisConnectionFactory cf) {
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()))
.entryTtl(Duration.ofMinutes(1)); // 캐시 기본 만료 시간 1분 설정
return RedisCacheManager.RedisCacheManagerBuilder.fromConnectionFactory(cf).cacheDefaults(redisCacheConfiguration).build();
}
}
게시물 엔티티 (Post.java)
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Post implements Serializable { // 캐시 직렬화를 위해 Serializable 구현
private Long id;
private String title;
private String content;
private String author;
}
서비스 레이어 (PostService.java)
코드 설명
서비스 레이어에서는 Spring의 캐싱 어노테이션을 활용합니다. @Cacheable("posts")는 posts라는 캐시 공간에서 데이터를 찾아보고, 없으면 메서드를 실행하여 결과를 캐시에 저장합니다. @CachePut("posts")는 항상 메서드를 실행하고 결과를 캐시에 업데이트하며, @CacheEvict("posts")는 캐시에서 해당 데이터를 제거합니다.
import org.springframework.cache.annotation.CacheEvict;
import org.springframework.cache.annotation.CachePut;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Service;
import java.util.HashMap;
import java.util.Map;
import java.util.Optional;
import java.util.concurrent.atomic.AtomicLong;
@Service
public class PostService {
private final Map<Long, Post> database = new HashMap<>();
private final AtomicLong nextId = new AtomicLong(1);
public PostService() {
// 더미 데이터 초기화
database.put(1L, new Post(1L, "Spring Boot Redis 캐싱", "Spring Data Redis를 활용한 캐싱 예제", "권퓨터"));
database.put(2L, new Post(2L, "백엔드 성능 최적화", "Redis 캐싱으로 API 응답 속도 개선", "권퓨터"));
nextId.set(3);
}
@Cacheable(value = "posts", key = "#id")
public Optional<Post> getPostById(Long id) {
System.out.println("DEBUG: Fetching post from DB for ID: " + id); // 캐시 미스 시에만 출력
try {
Thread.sleep(500); // DB 조회 지연 시뮬레이션
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return Optional.ofNullable(database.get(id));
}
@CachePut(value = "posts", key = "#post.id")
public Post createPost(Post post) {
Long id = nextId.getAndIncrement();
post.setId(id);
database.put(id, post);
System.out.println("DEBUG: Created new post with ID: " + id);
return post;
}
@CachePut(value = "posts", key = "#id")
public Optional<Post> updatePost(Long id, Post updatedPost) {
if (database.containsKey(id)) {
database.put(id, updatedPost);
updatedPost.setId(id);
System.out.println("DEBUG: Updated post with ID: " + id);
return Optional.of(updatedPost);
}
return Optional.empty();
}
@CacheEvict(value = "posts", key = "#id")
public boolean deletePost(Long id) {
if (database.containsKey(id)) {
database.remove(id);
System.out.println("DEBUG: Deleted post with ID: " + id);
return true;
}
return false;
}
}
컨트롤러 레이어 (PostController.java)
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import java.util.Optional;
@RestController
@RequestMapping("/api/posts")
public class PostController {
private final PostService postService;
public PostController(PostService postService) {
this.post = postService;
}
@GetMapping("/{id}")
public ResponseEntity<Post> getPost(@PathVariable Long id) {
Optional<Post> post = postService.getPostById(id);
return post.map(ResponseEntity::ok)
.orElseGet(() -> ResponseEntity.notFound().build());
}
@PostMapping
public ResponseEntity<Post> createPost(@RequestBody Post post) {
Post createdPost = postService.createPost(post);
return ResponseEntity.ok(createdPost);
}
@PutMapping("/{id}")
public ResponseEntity<Post> updatePost(@PathVariable Long id, @RequestBody Post post) {
Optional<Post> updatedPost = postService.updatePost(id, post);
return updatedPost.map(ResponseEntity::ok)
.orElseGet(() -> ResponseEntity.notFound().build());
}
@DeleteMapping("/{id}")
public ResponseEntity<Void> deletePost(@PathVariable Long id) {
if (postService.deletePost(id)) {
return ResponseEntity.noContent().build();
}
return ResponseEntity.notFound().build();
}
}
실행 방법:
1. Redis 서버를 실행합니다 (redis-server).
2. IDE(IntelliJ IDEA 등)에서 Spring Boot 애플리케이션을 실행하거나, ./mvnw spring-boot:run (Maven) 또는 ./gradlew bootRun (Gradle) 명령어로 실행합니다.
3. http://localhost:8080/api/posts/1에 요청을 보내면서 콘솔 로그와 응답 시간을 통해 캐시 동작을 확인해 보세요. 첫 요청은 “Fetching post from DB”가 출력되며 500ms 지연되지만, 이후 요청은 즉시 응답될 것입니다.
핵심 포인트
Spring Boot에서는 @EnableCaching과 @Cacheable, @CachePut, @CacheEvict 어노테이션을 사용하여 Redis 캐싱을 선언적으로 구현할 수 있습니다. RedisCacheConfiguration으로 캐시의 기본 만료 시간을 설정하여 캐시 데이터를 효과적으로 관리합니다.
자주 묻는 질문 (FAQ)
Q. Redis 캐싱은 어떤 상황에 가장 효과적인가요?
A. 주로 데이터의 읽기 빈도가 쓰기 빈도보다 훨씬 높은 경우, 즉 ‘읽기 중심(Read-Heavy)’ 서비스에 매우 효과적입니다. 예를 들어, 인기 게시물 조회, 사용자 프로필 조회, 상품 목록 조회 등 동일한 데이터를 여러 번 조회하는 상황에서 데이터베이스 부하를 줄이고 응답 속도를 크게 향상시킬 수 있습니다.
Q. 캐시 일관성 문제는 어떻게 해결할 수 있나요?
A. 캐시 일관성 문제는 모든 캐싱 전략에서 발생할 수 있는 고질적인 문제입니다. 가장 일반적인 해결책은 데이터 변경 시 즉시 관련 캐시를 무효화(삭제)하는 ‘Cache-Aside with Invalidation’ 패턴을 사용하는 것입니다. 또한, 모든 캐시 데이터에 적절한 TTL(Time To Live)을 설정하여 오래된 데이터가 자동으로 만료되도록 하는 것도 중요합니다.
Q. Redis와 데이터베이스는 어떻게 연동되나요?
A. 애플리케이션 코드가 중간에서 Redis와 데이터베이스 간의 연동을 담당합니다. 읽기 요청 시에는 먼저 Redis에서 데이터를 조회하고, 없으면 데이터베이스에서 가져와 Redis에 저장합니다. 쓰기 요청 시에는 데이터베이스에 데이터를 반영하고, Redis에 저장된 해당 데이터를 무효화하는 방식으로 연동됩니다. Spring Data Redis와 같은 프레임워크는 이러한 연동을 어노테이션 기반으로 추상화하여 편리하게 사용할 수 있도록 돕습니다.
Q. Redis 캐싱을 사용할 때 주의해야 할 점은 무엇인가요?
A. 첫째, 캐시 일관성 문제를 항상 고려해야 합니다. 둘째, 캐시 부재(Cache Miss) 시 데이터베이스에 부하가 집중되는 Thundering Herd 현상을 방지하기 위한 전략(분산 락, 캐시 워밍업)을 마련해야 합니다. 셋째, Redis는 인메모리 기반이므로 메모리 사용량을 모니터링하고 적절한 Eviction 정책을 설정해야 합니다. 마지막으로, Redis 서버 자체의 장애에 대비하여 복제(Replication) 및 고가용성(Sentinel/Cluster) 구성을 고려해야 합니다.
Q. Redis 클러스터링은 언제 필요할까요?
A. Redis 클러스터링은 단일 Redis 서버의 메모리 한계를 넘어서는 대규모 데이터를 저장해야 할 때, 또는 단일 서버로 감당할 수 없는 높은 읽기/쓰기 트래픽을 처리해야 할 때 필요합니다. 데이터를 여러 노드에 분산(샤딩)하여 저장하고, 각 노드에 대한 고가용성 및 Failover를 자동으로 제공함으로써 수평 확장을 가능하게 합니다.
마무리
마무리: Redis 캐싱, 미래를 위한 선택
지금까지 2026년 기준 Redis 캐싱의 중요성, 핵심 전략, 다양한 데이터 구조 활용법, 그리고 실제 백엔드 애플리케이션에 적용하는 방법까지 자세히 살펴보았습니다. Redis는 단순한 캐시를 넘어, 현대의 고성능, 고가용성 백엔드 시스템을 구축하는 데 필수적인 도구임을 다시 한번 확인할 수 있었습니다.
{ “@context”: “https://schema.org”, “@type”: “FAQPage”, “mainEntity”: [ { “@type”: “Question”, “name”: “Redis 캐싱은 어떤 상황에 가장 효과적인가요?”, “acceptedAnswer”: { “@type”: “Answer”, “text”: “A. 주로 데이터의 읽기 빈도가 쓰기 빈도보다 훨씬 높은 경우, 즉 ‘읽기 중심(Read-Heavy)’ 서비스에 매우 효과적입니다. 예를 들어, 인기 게시물 조회, 사용자 프로필 조회, 상품 목록 조회 등 동일한 데이터를 여러 번 조회하는 상황에서 데이터베이스 부하를 줄이고 응답 속도를 크게 향상시킬 수 있습니다.” } }, { “@type”: “Question”, “name”: “캐시 일관성 문제는 어떻게 해결할 수 있나요?”, “acceptedAnswer”: { “@type”: “Answer”, “text”: “A. 캐시 일관성 문제는 모든 캐싱 전략에서 발생할 수 있는 고질적인 문제입니다. 가장 일반적인 해결책은 데이터 변경 시 즉시 관련 캐시를 무효화(삭제)하는 ‘Cache-Aside with Invalidation’ 패턴을 사용하는 것입니다. 또한, 모든 캐시 데이터에 적절한 TTL(Time To Live)을 설정하여 오래된 데이터가 자동으로 만료되도록 하는 것도 중요합니다.” } }, { “@type”: “Question”, “name”: “Redis와 데이터베이스는 어떻게 연동되나요?”, “acceptedAnswer”: { “@type”: “Answer”, “text”: “A. 애플리케이션 코드가 중간에서 Redis와 데이터베이스 간의 연동을 담당합니다. 읽기 요청 시에는 먼저 Redis에서 데이터를 조회하고, 없으면 데이터베이스에서 가져와 Redis에 저장합니다. 쓰기 요청 시에는 데이터베이스에 데이터를 반영하고, Redis에 저장된 해당 데이터를 무효화하는 방식으로 연동됩니다. Spring Data Redis와 같은 프레임워크는 이러한 연동을 어노테이션 기반으로 추상화하여 편리하게 사용할 수 있도록 돕습니다.” } }, { “@type”: “Question”, “name”: “Redis 캐싱을 사용할 때 주의해야 할 점은 무엇인가요?”, “acceptedAnswer”: { “@type”: “Answer”, “text”: “A. 첫째, 캐시 일관성 문제를 항상 고려해야 합니다. 둘째, 캐시 부재(Cache Miss) 시 데이터베이스에 부하가 집중되는 Thundering Herd 현상을 방지하기 위한 전략(분산 락, 캐시 워밍업)을 마련해야 합니다. 셋째, Redis는 인메모리 기반이므로 메모리 사용량을 모니터링하고 적절한 Eviction 정책을 설정해야 합니다. 마지막으로, Redis 서버 자체의 장애에 대비하여 복제(Replication) 및 고가용성(Sentinel/Cluster) 구성을 고려해야 합니다.” } }, { “@type”: “Question”, “name”: “Redis 클러스터링은 언제 필요할까요?”, “acceptedAnswer”: { “@type”: “Answer”, “text”: “A. Redis 클러스터링은 단일 Redis 서버의 메모리 한계를 넘어서는 대규모 데이터를 저장해야 할 때, 또는 단일 서버로 감당할 수 없는 높은 읽기/쓰기 트래픽을 처리해야 할 때 필요합니다. 데이터를 여러 노드에 분산(샤딩)하여 저장하고, 각 노드에 대한 고가용성 및 Failover를 자동으로 제공함으로써 수평 확장을 가능하게 합니다.” } } ] }