

요약
API Rate Limiting: 2026년 서비스 안정성 뚝딱!
과도한 트래픽으로부터 백엔드 서비스를 보호하고 안정성을 확보하는 API Rate Limiting의 개념부터 다양한 구현 전략, Spring Boot 예시까지 완벽하게 알아봅니다.
핵심 키워드: API Rate Limiting, 트래픽 제어, 서비스 안정성
이 글의 순서
1. API Rate Limiting, 왜 필요할까요? (배경/도입)
2. 핵심 전략 파헤치기: 다양한 Rate Limiting 알고리즘
3. 분산 환경에서 Rate Limiting: 도전과 해결
4. Spring Boot와 Redis로 Rate Limiting 구현하기
5. 자주 묻는 질문 (FAQ)
배경/도입
API Rate Limiting, 왜 필요할까요?
안녕하세요, 권퓨터입니다! 2026년, 웹 서비스는 그 어느 때보다 복잡하고 사용자 트래픽은 폭발적으로 증가하고 있습니다. 이러한 환경에서 API를 개발하고 운영하는 백엔드 개발자라면, 서비스의 안정성과 가용성을 최우선으로 고려해야 합니다. 무분별한 API 요청은 서버 자원을 고갈시키고, 서비스 장애로 이어질 수 있기 때문이죠. 마치 고속도로에 갑자기 수많은 차량이 한꺼번에 몰려들면 극심한 교통 체증이 발생하는 것과 비슷합니다.
여기서 등장하는 핵심 개념이 바로 API Rate Limiting (API 속도 제한)입니다. Rate Limiting은 특정 기간 동안 사용자가 API에 보낼 수 있는 요청의 수를 제한하는 기술입니다. 단순히 요청을 막는 것을 넘어, 서비스를 보호하고 모든 사용자에게 공정한 접근 기회를 제공하는 중요한 역할을 합니다. 예를 들어, 한 사용자가 1분 안에 100회 이상의 요청을 보내면, 그 사용자의 추가 요청을 잠시 차단하는 방식이죠.
Rate Limiting이 필요한 주요 이유는 다음과 같습니다.
1. 서비스 안정성 확보: 과도한 요청으로 인한 서버 과부하를 방지하여 서비스가 중단되지 않도록 합니다.
2. 악의적인 공격 방어: DDoS 공격이나 무차별 대입(Brute-force) 공격과 같은 악의적인 시도로부터 시스템을 보호합니다.
3. 자원 공정 분배: 모든 사용자가 제한된 서버 자원을 공정하게 사용할 수 있도록 보장합니다.
4. 비용 절감: 불필요한 요청 처리를 줄여 인프라 비용을 절감할 수 있습니다.
5. API 오용 방지: 개발자가 의도치 않게 API를 과도하게 호출하는 경우를 방지합니다.
이번 글에서는 API Rate Limiting의 다양한 전략들을 살펴보고, 실제 Spring Boot 환경에서 Redis를 활용하여 어떻게 구현할 수 있는지 ‘뚝딱’ 알려드릴게요. 저와 함께 서비스 안정성의 비법을 파헤쳐 봅시다!
핵심 내용
핵심 전략 파헤치기: 다양한 Rate Limiting 알고리즘
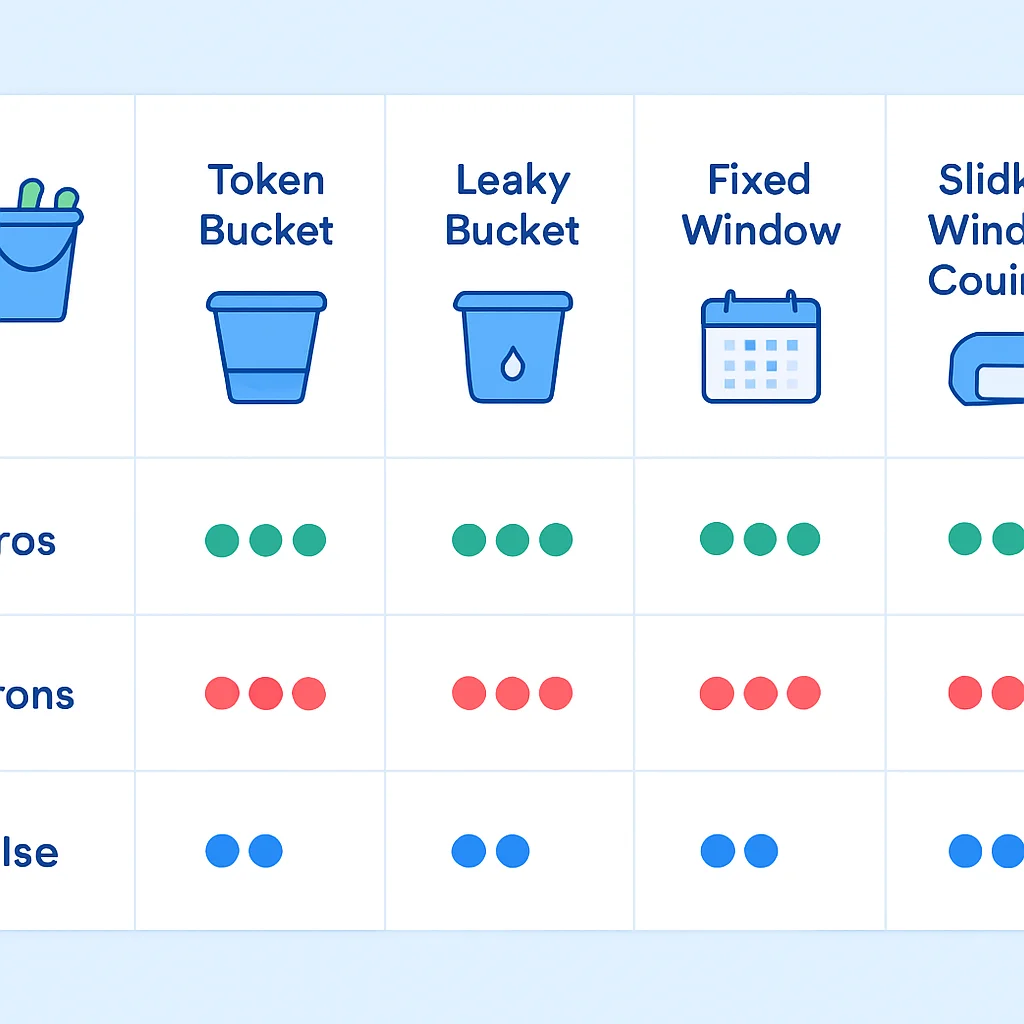
API Rate Limiting을 구현하는 데에는 여러 가지 알고리즘이 있습니다. 각 알고리즘은 장단점이 명확하므로, 서비스의 특성과 요구사항에 맞춰 적절한 전략을 선택하는 것이 중요합니다. 여기서는 가장 널리 사용되는 다섯 가지 알고리즘을 자세히 살펴보겠습니다.
1. 토큰 버킷 (Token Bucket) 알고리즘
토큰 버킷 알고리즘은 가장 널리 사용되는 Rate Limiting 기법 중 하나입니다. 마치 물이 채워지는 버킷과 같다고 생각하면 이해하기 쉽습니다. 버킷에는 정해진 용량(버스트 허용량)이 있고, 일정 속도(Rate)로 토큰이 버킷에 채워집니다. API 요청이 들어오면 버킷에서 토큰을 하나 꺼내 사용하고, 토큰이 없으면 요청은 거부되거나 대기열에 들어갑니다.
작동 방식:
★ 버킷(Bucket): 최대 저장 가능한 토큰의 수 (예: 100개).
★ 토큰 생성 속도(Rate): 초당 버킷에 추가되는 토큰의 수 (예: 초당 10개).
★ 요청이 오면 토큰을 사용하고, 없으면 요청을 거부합니다. 버킷이 가득 차면 더 이상 토큰이 추가되지 않습니다.
장점:
✓ 버스트 트래픽 처리: 버킷에 쌓여 있는 토큰만큼 일시적인 대량 요청(버스트)을 허용할 수 있어 유연합니다.
✓ 구현이 비교적 간단합니다.
단점:
✗ 토큰이 갑자기 많이 소진되면 잠시 동안 요청을 처리하지 못할 수 있습니다.
2. 리키 버킷 (Leaky Bucket) 알고리즘
리키 버킷 알고리즘은 토큰 버킷과 비슷하지만, 버킷에 물이 채워지고 일정 속도로 물이 새어 나가는 수도꼭지와 같은 개념입니다. 요청이 들어오면 버킷에 추가되고, 버킷이 가득 차면 추가 요청은 거부됩니다. 버킷에 있는 요청들은 정해진 일정한 속도로 처리됩니다.
작동 방식:
★ 버킷(Bucket): 처리 대기 중인 요청들을 저장하는 큐.
★ 누출 속도(Leak Rate): 버킷에서 요청이 처리되어 나가는 일정한 속도 (예: 초당 5개 요청).
★ 버킷이 가득 차면 새로운 요청은 버려집니다.
장점:
✓ 안정적인 처리율: 요청을 일정한 속도로 처리하여 백엔드 시스템의 부하를 안정적으로 유지합니다.
✓ 버스트 트래픽을 평활화(smoothing)하는 데 효과적입니다.
단점:
✗ 버스트 트래픽 시 요청이 지연될 수 있으며, 버킷 용량 초과 시 요청이 손실될 수 있습니다.
✗ 토큰 버킷에 비해 구현이 조금 더 복잡할 수 있습니다.
3. 고정 윈도우 카운터 (Fixed Window Counter) 알고리즘
이 알고리즘은 가장 단순한 방법입니다. 일정한 시간 간격(윈도우)을 정하고, 그 윈도우 동안의 요청 수를 카운트합니다. 윈도우가 시작되면 카운트를 0으로 초기화하고, 요청이 들어올 때마다 카운트를 증가시킵니다. 카운트가 설정된 임계값을 초과하면 해당 윈도우 동안의 모든 추가 요청을 거부합니다.
작동 방식:
★ 윈도우(Window): 고정된 시간 간격 (예: 1분).
★ 카운터(Counter): 각 윈도우 동안의 요청 수 (예: 최대 100개).
★ 윈도우가 끝나면 카운터는 초기화됩니다.
장점:
✓ 구현이 매우 간단하고 효율적입니다.
단점:
✗ 윈도우 경계 문제(Edge Case Problem): 윈도우 경계에 요청이 집중될 경우, 설정된 제한보다 2배 많은 요청이 허용될 수 있습니다. 예를 들어, 1분당 100회 제한일 때, 0분 59초에 100회 요청, 1분 01초에 100회 요청이 들어오면 실제로는 2초 동안 200회 요청이 처리되는 문제가 발생합니다.
✗ 버스트 트래픽에 취약합니다.
4. 슬라이딩 윈도우 로그 (Sliding Window Log) 알고리즘
고정 윈도우 카운터의 ‘윈도우 경계 문제’를 해결하기 위해 고안된 알고리즘입니다. 각 요청의 타임스탬프를 저장하고, 현재 시점에서 (현재 시간 – 윈도우 크기) 이전에 발생한 모든 요청을 제거한 후 남은 요청 수를 카운트합니다.
작동 방식:
★ 로그(Log): 각 요청의 정확한 타임스탬프를 저장합니다.
★ 윈도우(Window): 현재 시간을 기준으로 이전 N초/분 동안의 요청만 유효하게 봅니다.
★ 요청 시, 유효 윈도우 내의 요청만 필터링하여 카운트합니다.
장점:
✓ 가장 정확한 제어: 고정 윈도우의 경계 문제를 완벽하게 해결하여, 어떤 시점에서든 정확히 N초/분 동안의 요청 수를 제한합니다.
단점:
✗ 높은 메모리 사용량: 모든 요청의 타임스탬프를 저장해야 하므로, 트래픽이 많을수록 메모리 사용량이 급증합니다.
✗ 분산 환경에서 구현 시 동기화 오버헤드가 클 수 있습니다.
5. 슬라이딩 윈도우 카운터 (Sliding Window Counter) 알고리즘
슬라이딩 윈도우 로그의 메모리 오버헤드를 줄이면서도 고정 윈도우의 경계 문제를 완화하는 절충안입니다. 현재 윈도우와 이전 윈도우의 카운트를 가중 평균하여 사용합니다.
작동 방식:
★ 고정된 작은 윈도우(Bucket): 예를 들어, 1시간 제한을 1분 단위의 작은 윈도우 60개로 나눕니다.
★ 각 작은 윈도우마다 요청 수를 카운트합니다.
★ 현재 시간 기준의 N분 전까지의 카운트를 계산할 때, 현재 작은 윈도우의 카운트와 이전 작은 윈도우의 카운트를 시간 비율에 따라 가중치를 주어 합산합니다.
장점:
✓ 정확성과 효율성 절충: 슬라이딩 윈도우 로그보다 메모리 사용량이 적으면서도 고정 윈도우보다 정확합니다.
✓ 윈도우 경계 문제를 크게 완화합니다.
단점:
✗ 고정 윈도우보다는 구현이 복잡하고, 슬라이딩 윈도우 로그보다는 덜 정확합니다.
자, 이렇게 다양한 알고리즘들을 알아봤는데요. 각 알고리즘의 특징을 한눈에 비교해볼 수 있는 표를 준비했습니다.
문제 해결
분산 환경에서 Rate Limiting: 도전과 해결
단일 서버 환경에서는 Rate Limiting 구현이 비교적 간단합니다. 하지만 현대의 백엔드 서비스는 대부분 여러 서버 인스턴스로 구성된 분산 환경에서 운영됩니다. 이 경우, 각 인스턴스가 독립적으로 Rate Limiting을 수행하면 심각한 문제가 발생할 수 있습니다.
1. 분산 환경에서의 동기화 문제
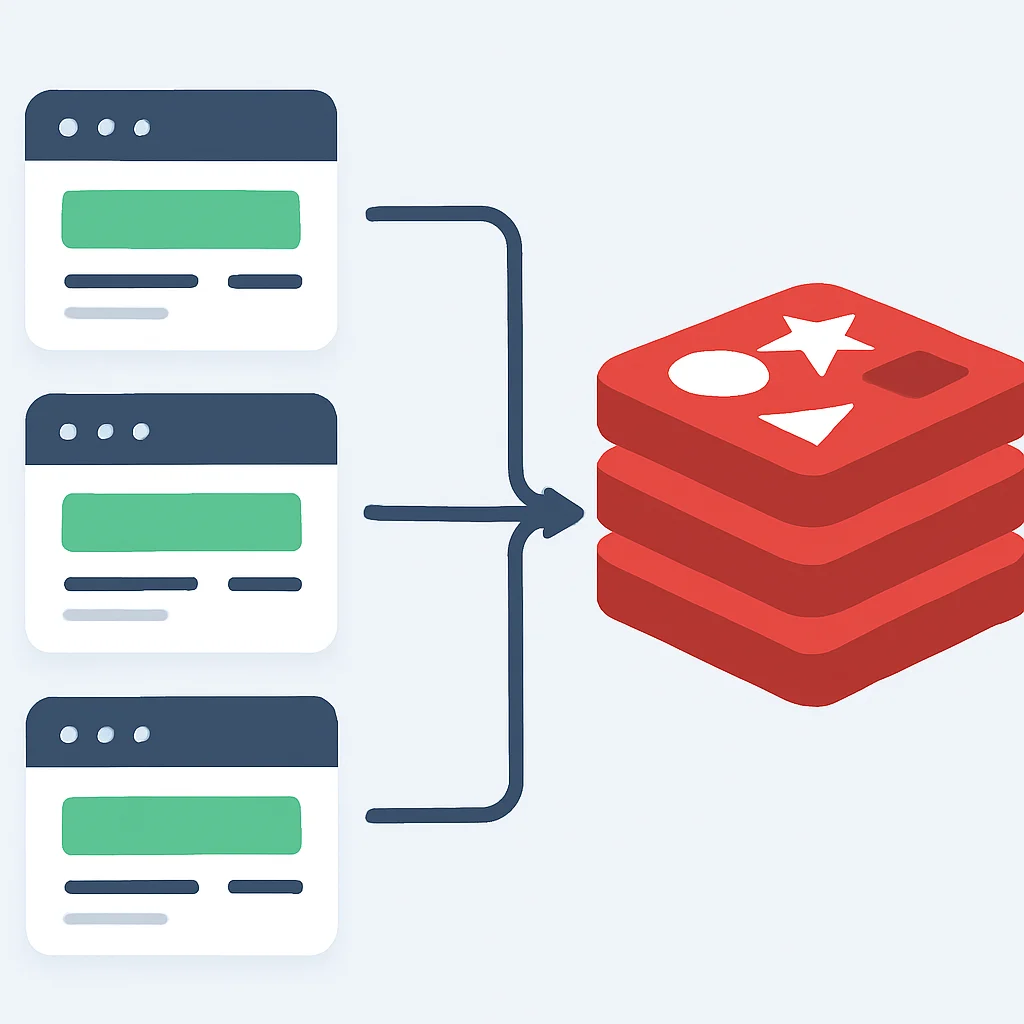
예를 들어, 1분당 100회 요청 제한이 있는 API가 3개의 서버 인스턴스에서 서비스되고 있다고 가정해봅시다. 만약 각 인스턴스가 자체적으로 요청을 카운트한다면, 실제로는 한 사용자가 300회(100회 * 3)의 요청을 보낼 수 있게 됩니다. 이는 설정된 제한을 훨씬 초과하여 시스템에 과부하를 줄 수 있습니다. 즉, 모든 인스턴스가 동일한 Rate Limiting 정책을 공유하고, 요청 카운트를 중앙에서 관리해야 합니다.
해결책: 중앙 집중식 카운터 사용
이 문제를 해결하기 위해 Redis나 Memcached와 같은 분산 캐시 또는 Cassandra와 같은 분산 데이터베이스를 활용하여 요청 카운트를 중앙에서 관리합니다. 각 서버 인스턴스는 요청이 들어올 때마다 중앙 저장소에 카운트를 요청하고, 제한 초과 여부를 확인합니다.
Redis를 활용한 간단한 Rate Limiting (고정 윈도우 카운터) 예시입니다. INCR 명령으로 카운트를 증가시키고, EXPIRE 명령으로 윈도우 만료 시간을 설정합니다. 이 두 명령은 Redis 트랜잭션(MULTI/EXEC) 또는 Lua 스크립트를 사용하여 아토믹(atomic)하게 실행하는 것이 중요합니다.
-- Redis Lua 스크립트 예시 (토큰 버킷 또는 고정 윈도우 카운터)
local key = KEYS[1] -- Rate Limiting을 적용할 키 (예: user:123:api:/path)
local limit = tonumber(ARGV[1]) -- 최대 허용 요청 수
local window = tonumber(ARGV[2]) -- 윈도우 시간 (초)
local current_count = redis.call('INCR', key)
if current_count == 1 then
redis.call('EXPIRE', key, window)
end
if current_count > limit then
return 0 -- 제한 초과
else
return 1 -- 요청 허용
end
2. 과부하 시 동작 및 사용자 경험
Rate Limiting에 의해 요청이 거부되었을 때, 사용자에게 어떤 응답을 줄 것인지도 중요합니다. 일반적으로 HTTP 상태 코드 429 Too Many Requests를 반환합니다. 또한, 클라이언트가 언제 다시 요청을 시도해야 할지 알려주는 Retry-After 헤더를 포함하는 것이 좋습니다.
예시 HTTP 응답:
HTTP/1.1 429 Too Many Requests
Content-Type: application/json
Retry-After: 60 -- 60초 후에 다시 시도하세요.
{
"code": "TOO_MANY_REQUESTS",
"message": "Too many requests. Please try again after 60 seconds."
}
클라이언트 측에서는 지수 백오프(Exponential Backoff) 전략을 사용하여 재시도 간격을 점진적으로 늘려 서버의 부담을 줄여야 합니다. 예를 들어, 첫 재시도는 1초 후, 두 번째는 2초 후, 세 번째는 4초 후와 같이 시간을 늘려가는 방식입니다.
3. 세분화된 Rate Limiting
모든 API 요청에 일률적인 제한을 적용하는 것은 비효율적일 수 있습니다. 특정 API 엔드포인트는 더 많은 요청을 허용해야 할 수 있고, 다른 엔드포인트는 더 엄격한 제한이 필요할 수 있습니다. 또한, 사용자 등급(예: 일반 사용자, 프리미엄 사용자)에 따라 다른 제한을 적용하는 것도 일반적입니다.
해결책: 다양한 기준으로 키 생성
Rate Limiting의 기준이 되는 키를 다양하게 생성하여 세분화된 제한을 적용할 수 있습니다.
★ IP 주소 기반: ip:{client_ip}
★ 사용자 ID 기반: user:{user_id}
★ API 엔드포인트 기반: endpoint:{api_path}
★ 조합 기반: user:{user_id}:endpoint:{api_path}
★ 사용자 등급 기반: tier:{user_tier}:{user_id}
실전 적용
Spring Boot와 Redis로 Rate Limiting 구현하기
이제 이론을 바탕으로 실제 Spring Boot 애플리케이션에서 Redis를 활용한 Rate Limiting을 구현해볼 시간입니다. 여기서는 AOP(Aspect-Oriented Programming)와 커스텀 어노테이션을 사용하여 유연하고 재사용 가능한 Rate Limiter를 만들어보겠습니다. 우리는 슬라이딩 윈도우 카운터에 가까운 방식을 Redis의 ZADD, ZREMRANGEBYSCORE, ZCARD 명령을 조합하여 구현해볼 수 있습니다.
1. 프로젝트 설정
먼저, Spring Boot 프로젝트에 Redis 관련 의존성을 추가합니다. pom.xml (Maven) 또는 build.gradle (Gradle)에 다음 의존성을 추가해주세요.
Spring Data Redis와 Spring AOP를 위한 의존성입니다. Redis와의 통신 및 AOP를 활용한 Rate Limiting 구현에 필요합니다.
<!-- Maven (pom.xml) -->
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
그리고 application.properties (또는 application.yml)에 Redis 연결 정보를 설정합니다.
spring.redis.host=localhost
spring.redis.port=6379
2. @RateLimit 커스텀 어노테이션 정의
API 메서드에 적용할 커스텀 어노테이션을 만듭니다. 이 어노테이션은 제한 시간(duration)과 허용 요청 수(limit)를 인자로 받습니다.
이 어노테이션은 메서드 수준에서 적용되며, duration(제한 시간, 초 단위)과 limit(허용 요청 수)를 설정할 수 있게 합니다.
// src/main/java/com/kwonputer/ratelimiter/annotation/RateLimit.java
package com.kwonputer.ratelimiter.annotation;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import java.util.concurrent.TimeUnit;
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface RateLimit {
long duration() default 1; // 제한 시간 (기본 1초)
TimeUnit timeUnit() default TimeUnit.SECONDS; // 시간 단위
int limit(); // 허용 요청 수
String keyPrefix() default "rate_limit:"; // Redis 키 접두사
}
3. Rate Limiter Aspect 구현
이제 AOP를 사용하여 @RateLimit 어노테이션이 붙은 메서드가 호출되기 전에 Rate Limiting 로직을 실행하는 Aspect를 구현합니다.
이 Aspect는 @RateLimit 어노테이션이 붙은 메서드를 가로챕니다. 요청자의 IP 주소를 기준으로 Redis 키를 생성하고, Redis의 Sorted Set(ZADD, ZREMRANGEBYSCORE, ZCARD) 명령을 사용하여 슬라이딩 윈도우 로그 방식의 Rate Limiting을 구현합니다. 요청이 제한을 초과하면 TooManyRequestsException을 발생시킵니다.
// src/main/java/com/kwonputer/ratelimiter/aop/RateLimitAspect.java
package com.kwonputer.ratelimiter.aop;
import com.kwonputer.ratelimiter.annotation.RateLimit;
import com.kwonputer.ratelimiter.exception.TooManyRequestsException;
import jakarta.servlet.http.HttpServletRequest;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import java.lang.reflect.Method;
import java.util.Objects;
import java.util.concurrent.TimeUnit;
@Aspect
@Component
public class RateLimitAspect {
private final RedisTemplate<String, String> redisTemplate;
public RateLimitAspect(RedisTemplate<String, String> redisTemplate) {
this.redisTemplate = redisTemplate;
}
@Around("@annotation(com.kwonputer.ratelimiter.annotation.RateLimit)")
public Object rateLimitCheck(ProceedingJoinPoint joinPoint) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
RateLimit rateLimit = method.getAnnotation(RateLimit.class);
// Redis 키 생성 (IP 주소 + 메서드 이름)
HttpServletRequest request = ((ServletRequestAttributes) Objects.requireNonNull(RequestContextHolder.getRequestAttributes())).getRequest();
String ipAddress = request.getRemoteAddr();
String key = rateLimit.keyPrefix() + ipAddress + ":" + method.getName();
long currentTimeMillis = System.currentTimeMillis();
long windowStartMillis = currentTimeMillis - rateLimit.timeUnit().toMillis(rateLimit.duration());
// Redis Sorted Set을 이용한 슬라이딩 윈도우 로그 방식
// 1. 현재 시간 이전에 만료된 요청 제거
redisTemplate.opsForZSet().removeRangeByScore(key, 0, windowStartMillis);
// 2. 현재 요청 추가 (점수는 타임스탬프, 멤버는 고유 ID)
String requestId = ipAddress + ":" + System.nanoTime(); // 고유 요청 ID
redisTemplate.opsForZSet().add(key, requestId, currentTimeMillis);
// 3. 현재 윈도우 내의 요청 수 카운트
Long currentRequests = redisTemplate.opsForZSet().size(key);
if (currentRequests != null && currentRequests > rateLimit.limit()) {
// 제한 초과 시 예외 발생
long retryAfterSeconds = rateLimit.timeUnit().toSeconds(rateLimit.duration()) - (currentTimeMillis - windowStartMillis) / 1000;
request.setAttribute("retryAfter", Math.max(1, retryAfterSeconds));
throw new TooManyRequestsException("Too many requests. Please try again later.");
}
// 윈도우 만료 시간 설정 (선택 사항: Redis 키가 영원히 남는 것을 방지)
// ZSet은 자동으로 만료되지 않으므로, TTL을 설정하여 관리하는 것이 좋습니다.
// 다만, ZSet의 TTL은 ZSet 내의 요소에 개별적으로 적용되지 않습니다.
// 여기서는 ZSet 자체의 TTL을 설정하여 전체 키가 만료되도록 합니다.
// 실제 운영 환경에서는 ZSet의 크기 관리를 위해 주기적인 클리닝 작업이 필요할 수 있습니다.
if (redisTemplate.getExpire(key, TimeUnit.SECONDS) == -1) { // TTL이 설정되지 않았을 경우
redisTemplate.expire(key, rateLimit.duration(), rateLimit.timeUnit());
}
return joinPoint.proceed(); // 메서드 실행
}
}
4. 예외 처리 핸들러
Rate Limiting에 의해 요청이 거부되었을 때, TooManyRequestsException이 발생합니다. 이 예외를 처리하여 적절한 HTTP 응답(429)을 반환하는 핸들러를 구현합니다.
이 컨트롤러 어드바이스는 TooManyRequestsException이 발생했을 때 HTTP 429 상태 코드와 함께 Retry-After 헤더를 클라이언트에게 보냅니다.
// src/main/java/com/kwonputer/ratelimiter/exception/GlobalExceptionHandler.java
package com.kwonputer.ratelimiter.exception;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.bind.annotation.ExceptionHandler;
import jakarta.servlet.http.HttpServletRequest;
import java.util.HashMap;
import java.util.Map;
@ControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(TooManyRequestsException.class)
public ResponseEntity<Map<String, String>> handleTooManyRequestsException(TooManyRequestsException ex, HttpServletRequest request) {
Map<String, String> errorResponse = new HashMap<>();
errorResponse.put("code", "TOO_MANY_REQUESTS");
errorResponse.put("message", ex.getMessage());
long retryAfter = (long) request.getAttribute("retryAfter");
return ResponseEntity.status(HttpStatus.TOO_MANY_REQUESTS)
.header("Retry-After", String.valueOf(retryAfter))
.body(errorResponse);
}
}
5. 컨트롤러에 Rate Limiting 적용
이제 Rate Limiting을 적용하고 싶은 API 메서드에 @RateLimit 어노테이션을 붙이기만 하면 됩니다. 정말 ‘뚝딱’이죠?
아래 컨트롤러 예시에서는 /api/hello 엔드포인트에 10초당 최대 5회 요청 제한을 적용했습니다. /api/unlimited 엔드포인트는 제한이 없습니다.
// src/main/java/com/kwonputer/ratelimiter/controller/TestController.java
package com.kwonputer.ratelimiter.controller;
import com.kwonputer.ratelimiter.annotation.RateLimit;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.concurrent.TimeUnit;
@RestController
@RequestMapping("/api")
public class TestController {
@GetMapping("/hello")
@RateLimit(duration = 10, timeUnit = TimeUnit.SECONDS, limit = 5) // 10초에 5회 요청 제한
public ResponseEntity<String> sayHello() {
return ResponseEntity.ok("Hello, Rate Limited API!");
}
@GetMapping("/unlimited")
public ResponseEntity<String> sayHelloUnlimited() {
return ResponseEntity.ok("Hello, Unlimited API!");
}
}

6. 성능 테스트 및 모니터링
Rate Limiting이 제대로 동작하는지 확인하고, 시스템에 미치는 영향을 파악하기 위해 성능 테스트와 모니터링은 필수적입니다. JMeter, k6, Postman Collection Runner와 같은 도구를 사용하여 과도한 요청을 발생시켜 Rate Limiting이 예상대로 작동하는지 검증할 수 있습니다.
또한, Prometheus와 Grafana를 사용하여 Redis의 지표(예: 명령어 처리량, 메모리 사용량)와 애플리케이션의 Rate Limiting 관련 지표(예: 제한 초과 횟수, 허용된 요청 횟수)를 시각화하여 실시간으로 모니터링하는 것이 좋습니다. 이를 통해 Rate Limiting 정책을 최적화하고 잠재적인 문제를 조기에 발견할 수 있습니다.
FAQ
자주 묻는 질문
Q. API Rate Limiting이 왜 중요한가요?
A. Rate Limiting은 서비스 안정성 확보, DDoS 공격 방어, 자원 공정 분배, 그리고 API 오용 방지를 위해 매우 중요합니다. 과도한 트래픽으로부터 백엔드 시스템을 보호하여 서비스 장애를 예방하고 사용자 경험을 개선합니다.
Q. 어떤 Rate Limiting 전략을 선택해야 하나요?
A. 서비스의 특성에 따라 다릅니다. 버스트 트래픽 허용이 중요하다면 토큰 버킷, 서버 부하를 안정적으로 유지하고 싶다면 리키 버킷, 가장 정확한 제한이 필요하다면 슬라이딩 윈도우 로그(메모리 고려), 혹은 그 절충안인 슬라이딩 윈도우 카운터가 좋습니다. 가장 간단한 구현은 고정 윈도우 카운터이지만 윈도우 경계 문제를 인지해야 합니다.
Q. Rate Limiting을 우회하려는 공격은 어떻게 막나요?
A. Rate Limiting은 1차적인 방어선이며, 완벽한 방어는 어렵습니다. IP 주소, 사용자 인증 정보, 요청 헤더 등 다양한 기준으로 복합적인 제한을 적용하고, 봇 감지 시스템(WAF)이나 Captcha와 같은 추가 보안 장치를 함께 사용하는 것이 효과적입니다.
Q. Rate Limiting 적용 시 사용자 경험은 어떻게 관리해야 하나요?
A. 요청이 제한될 경우 HTTP 429 상태 코드와 함께 Retry-After 헤더를 명확히 제공해야 합니다. 클라이언트는 이 헤더를 참고하여 지수 백오프 전략으로 재시도하여 불필요한 요청을 줄이고, 사용자에게는 친절한 메시지나 진행 표시를 통해 대기 상황을 알려주어야 합니다.
Q. 분산 환경에서 Rate Limiting을 구현하려면 어떻게 해야 하나요?
A. 여러 서버 인스턴스가 독립적으로 카운트하지 않도록, Redis와 같은 중앙 집중식 데이터 저장소를 사용하여 모든 요청 카운터를 동기화해야 합니다. Redis의 INCR, EXPIRE, 또는 Sorted Set(ZADD, ZCARD) 명령을 아토믹하게 사용하는 것이 핵심입니다.
결론 및 향후 전망
결론 및 향후 전망
지금까지 API Rate Limiting의 중요성부터 다양한 알고리즘, 그리고 Spring Boot와 Redis를 활용한 실제 구현 방법까지 자세히 살펴보았습니다. 2026년, 복잡하고 고도화되는 웹 서비스 환경에서 Rate Limiting은 더 이상 선택 사항이 아닌 필수적인 요소입니다. 적절한 Rate Limiting 전략은 서비스의 안정성을 보장하고, 사용자에게 쾌적한 경험을 제공하며, 궁극적으로는 비즈니스 연속성을 지키는 핵심적인 방어막 역할을 합니다.
앞으로 Rate Limiting 기술은 더욱 발전할 것입니다. AI 기반의 동적 Rate Limiting은 실시간 트래픽 패턴을 분석하여 자동으로 제한 정책을 조정하고, 특정 유형의 공격을 더욱 정교하게 방어할 수 있게 될 것입니다. 또한, 서버리스(Serverless) 아키텍처나 에지 컴퓨팅(Edge Computing) 환경에서의 Rate Limiting 구현 방식도 새로운 도전 과제로 떠오르고 있습니다.
권퓨터와 함께 서비스 안정성을 ‘뚝딱’ 만들어가는 여정에 도움이 되셨기를 바랍니다. 여러분의 백엔드 서비스가 항상 든든하게 운영되기를 응원합니다! 다음에도 유익한 정보로 찾아올게요.
긴 글을 읽어주셔서 감사합니다!
오늘 다룬 API Rate Limiting 내용이 여러분의 백엔드 개발에 큰 도움이 되기를 바랍니다.
궁금한 점이 있다면 언제든지 댓글로 남겨주세요! 권퓨터가 성심성의껏 답변해드리겠습니다.