

요약
2026년 개발자를 위한 AI 트렌드: LLM & 생성형 AI 실전 활용법
2026년, 개발자들이 주목해야 할 LLM과 생성형 AI의 최신 트렌드를 분석하고 실제 프로젝트에 적용 가능한 활용법을 소개합니다.
핵심 키워드: LLM, 생성형 AI, 개발자 AI 활용
이 글의 순서
1. 2026년, 개발자의 필수 역량이 된 AI
2. 2026년 LLM, 어디까지 진화했나?
3. 개발자를 위한 생성형 AI 실전 가이드
4. AI 프로젝트, 이것만 알면 성공!
5. 2026년, AI와 함께 성장하는 개발자의 미래
6. 자주 묻는 질문 (FAQ)
배경
2026년, 개발자의 필수 역량이 된 AI
안녕하세요, 권퓨터입니다! 2026년 현재, 인공지능(AI) 기술은 더 이상 SF 영화 속 이야기가 아닙니다. 특히 대규모 언어 모델(LLM)과 생성형 AI는 소프트웨어 개발의 패러다임을 근본적으로 바꾸고 있습니다. 단순한 보조 도구를 넘어, 이제 AI는 개발 생산성을 혁신하고, 새로운 서비스와 애플리케이션을 창조하는 핵심 동력으로 자리매김했습니다.
과거에는 AI 전문가나 데이터 과학자만의 영역으로 여겨졌던 AI가 이제는 프런트엔드, 백엔드, 모바일 개발자 등 모든 개발 직군에 걸쳐 필수적인 역량이 되고 있습니다. 코드를 자동으로 생성하고, 복잡한 시스템을 설계하며, 사용자 경험을 개인화하는 등 AI의 활용 범위는 상상을 초월합니다. 이러한 변화 속에서 개발자들은 AI 기술을 이해하고 자신의 프로젝트에 효과적으로 적용하는 방법을 숙지해야 합니다.
2026년의 기술 트렌드를 정확히 파악하고, LLM과 생성형 AI를 실전에서 어떻게 활용할 수 있을지 구체적인 방법을 함께 탐구해보고자 합니다. 이 글을 통해 개발자 여러분이 AI 시대의 변화를 주도하고, 더욱 혁신적인 솔루션을 만들어나가는 데 필요한 통찰력을 얻어가시길 바랍니다.
핵심 포인트
2026년, LLM과 생성형 AI는 개발 생산성을 혁신하고 새로운 서비스 창조의 핵심 동력으로 부상하며, 모든 개발 직군에 필수적인 역량이 되고 있습니다.
핵심 분석
2026년 LLM, 어디까지 진화했나?
멀티모달 LLM의 부상: 텍스트를 넘어선 이해
2026년 LLM 트렌드의 가장 두드러진 특징은 바로 ‘멀티모달리티(Multimodality)’의 강화입니다. 초기 LLM이 텍스트 데이터에만 집중했다면, 이제는 이미지, 오디오, 비디오 등 다양한 형태의 데이터를 동시에 이해하고 처리하는 능력이 비약적으로 발전했습니다. OpenAI의 GPT-4o, Google의 Gemini 1.5 Pro와 같은 모델들은 텍스트 질문에 이미지를 분석하여 답변하거나, 음성으로 대화하며 실시간으로 복잡한 정보를 처리하는 수준에 도달했습니다.
개발자 입장에서는 이러한 멀티모달 LLM을 활용하여 더욱 풍부하고 직관적인 사용자 인터페이스를 구축할 수 있습니다. 예를 들어, 사용자가 사진을 찍어 올리면 해당 이미지에 대한 설명을 텍스트로 제공하고, 이와 관련된 추가 정보를 검색하거나 다음 액션을 제안하는 애플리케이션을 쉽게 구현할 수 있습니다. 또한, 음성 인터페이스를 통해 복잡한 작업을 지시하고 결과를 시각적으로 확인하는 새로운 형태의 서비스도 가능해집니다.
멀티모달 LLM은 의료 분야에서 의료 영상 분석 및 진단 보조, 교육 분야에서 시각 자료를 활용한 학습 콘텐츠 생성, 전자상거래 분야에서 이미지 기반 상품 추천 등 무궁무진한 활용 가능성을 제공합니다. 개발자들은 이러한 모델의 API를 활용하여 기존의 텍스트 기반 서비스에서는 불가능했던 혁신적인 사용자 경험을 설계할 수 있게 됩니다.
핵심 포인트
멀티모달 LLM은 텍스트를 넘어 이미지, 오디오, 비디오를 동시에 이해하여, 개발자들이 직관적인 UI 및 혁신적인 서비스(예: 이미지 기반 추천, 음성 인터페이스)를 구축할 수 있도록 돕습니다.
에이전트 기반 LLM 시스템: 자율적인 작업 수행 능력
또 다른 중요한 트렌드는 LLM이 단순한 질의응답을 넘어 스스로 목표를 설정하고, 계획을 수립하며, 외부 도구를 사용하여 작업을 수행하는 ‘에이전트(Agent)’로서의 진화입니다. LangChain, AutoGPT, CrewAI와 같은 프레임워크들은 이러한 에이전트 시스템 구축을 위한 강력한 기반을 제공합니다. 에이전트 LLM은 기억(Memory), 도구 사용(Tool Use), 계획(Planning), 자기 성찰(Self-reflection) 등의 기능을 통해 복잡한 문제도 단계적으로 해결할 수 있습니다.
개발자들은 이러한 에이전트 기반 LLM을 활용하여 반복적이고 시간 소모적인 업무를 자동화하거나, 복잡한 비즈니스 프로세스를 지능적으로 처리하는 시스템을 구축할 수 있습니다. 예를 들어, 웹 검색을 통해 최신 정보를 수집하고, 스프레드시트를 분석하며, 이메일을 작성하는 일련의 작업을 하나의 AI 에이전트가 처리하도록 만들 수 있습니다. 이는 개발자의 생산성을 극대화하고, 더 가치 있는 창의적인 작업에 집중할 수 있게 합니다.
다음은 LangChain을 사용하여 간단한 AI 에이전트를 구성하는 개념적인 코드 예시입니다. 실제 구현에서는 더 많은 도구와 복잡한 체인 구조가 필요합니다.
코드 설명
이 파이썬 코드는 LangChain 라이브러리를 사용하여 간단한 AI 에이전트를 설정하는 방법을 보여줍니다. LLM과 외부 도구(예: 계산기)를 연결하여 사용자의 질문에 따라 적절한 도구를 호출하고 문제를 해결합니다. 이는 LLM이 단순한 텍스트 생성기를 넘어, 실제 작업을 수행하는 ‘에이전트’로 동작하는 핵심 원리를 보여줍니다.
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_react_agent, Tool
from langchain import hub
# 1. LLM 초기화 (여기서는 OpenAI 모델 사용)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 2. 사용할 도구 정의 (예: 간단한 계산기 도구)
def calculate_expression(expression: str) -> str:
"""Calculates a mathematical expression."""
try:
return str(eval(expression))
except Exception as e:
return f"Error: {e}"
tools = [
Tool(
name="Calculator",
func=calculate_expression,
description="Useful for when you need to answer questions about math.",
),
]
# 3. ReAct 프롬프트 로드
prompt = hub.pull("hwchase17/react")
# 4. 에이전트 생성
agent = create_react_agent(llm, tools, prompt)
# 5. AgentExecutor 생성 (에이전트 실행기)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 6. 에이전트 실행 예시
print("--- 에이전트 실행 시작 ---")
response = agent_executor.invoke({"input": "What is 123 * 456?"})
print("\n--- 에이전트 실행 결과 ---")
print(response["output"])
response = agent_executor.invoke({"input": "What is the capital of France?"})
print("\n--- 에이전트 실행 결과 ---")
print(response["output"])
소형 LLM (SLM)과 온디바이스 AI: 효율성과 접근성의 증대
대규모 LLM의 강력함은 인정하지만, 높은 운영 비용과 지연 시간(latency)은 여전히 개발자들에게 부담으로 작용합니다. 2026년에는 이러한 문제를 해결하기 위해 ‘소형 LLM(SLM, Small Language Model)’과 ‘온디바이스 AI(On-device AI)’의 중요성이 더욱 커지고 있습니다. Microsoft의 Phi-3, Google의 Gemma 2B, Meta의 Llama 3 8B와 같은 모델들은 적은 파라미터로도 상당한 성능을 발휘하며, 모바일 기기나 엣지 디바이스에서도 구동 가능한 수준에 도달했습니다.
SLM은 클라우드 API 호출 없이 로컬에서 AI 기능을 제공함으로써 비용을 절감하고, 개인정보 보호를 강화하며, 네트워크 연결 없이도 작동할 수 있다는 장점이 있습니다. 이는 개발자들이 스마트폰 앱, 스마트 가전, 임베디드 시스템 등 다양한 환경에서 AI 기능을 구현할 수 있는 새로운 기회를 제공합니다. 예를 들어, 오프라인 환경에서도 작동하는 번역 앱, 개인 비서 앱, 실시간 음성 인식 기능 등을 SLM을 통해 개발할 수 있습니다.
다음은 대규모 LLM과 소형 LLM의 주요 특징을 비교한 표입니다.
LLM 유형별 비교
| 특징 | 대규모 LLM (예: GPT-4o) | 소형 LLM (예: Phi-3) |
|---|---|---|
| 파라미터 수 | 수천억 개 이상 | 수십억 개 이하 |
| 성능 및 범용성 | 매우 높음, 광범위한 작업 처리 | 특정 작업에 최적화, 우수함 |
| 운영 비용 | 높음 (클라우드 API) | 낮음 (로컬/온디바이스) |
| 지연 시간 (Latency) | 네트워크 영향, 상대적으로 높음 | 매우 낮음 (로컬 처리) |
| 개인정보 보호 | 데이터 전송 필요, 상대적 취약 | 로컬 처리, 매우 우수 |
| 주요 활용 분야 | 복잡한 연구, 범용 AI 서비스 | 모바일 앱, 엣지 컴퓨팅, 임베디드 시스템 |
핵심 포인트
소형 LLM(SLM)은 비용 효율성, 낮은 지연 시간, 강화된 개인정보 보호를 제공하며, 모바일 및 엣지 디바이스 등 로컬 환경에서 AI 기능을 구현하는 데 핵심적인 역할을 합니다.
실전 활용
개발자를 위한 생성형 AI 실전 가이드
코드 생성 및 자동화: 생산성 극대화
생성형 AI는 개발자의 코딩 방식을 혁신하고 있습니다. GitHub Copilot, Amazon CodeWhisperer, Google의 AlphaCode와 같은 도구들은 주석이나 함수명만으로 코드를 자동 완성하거나, 특정 요구 사항에 맞는 코드를 통째로 생성해줍니다. 2026년에는 이러한 코드 생성 도구들이 더욱 고도화되어 단순한 구문 완성을 넘어, 복잡한 로직과 알고리즘까지 제안하는 수준에 이르렀습니다.
개발자들은 생성형 AI를 활용하여 다음과 같은 이점을 얻을 수 있습니다:
- 생산성 향상: 반복적인 코드 작성 시간을 줄여 핵심 로직 개발에 집중할 수 있습니다.
- 코드 품질 개선: AI가 제안하는 모범 사례나 효율적인 코드를 학습하여 코드 품질을 높일 수 있습니다.
- 새로운 기술 학습: 익숙하지 않은 라이브러리나 프레임워크 사용 시 AI의 도움을 받아 빠르게 학습하고 적용할 수 있습니다.
- 테스트 코드 자동 생성: 기능 코드에 대한 유닛 테스트나 통합 테스트 코드를 AI가 자동으로 생성하여 개발 시간을 단축하고 버그를 줄일 수 있습니다.
특히 테스트 코드 자동 생성은 개발 주기 단축에 큰 영향을 미칩니다. 개발자가 직접 테스트 케이스를 설계하고 코드를 작성하는 데 드는 시간과 노력을 AI가 상당 부분 덜어주기 때문입니다. 이는 개발자가 더 많은 기능을 구현하거나, 기존 코드의 리팩토링 및 최적화에 집중할 수 있게 합니다.
활용 사례: 테스트 코드 자동 생성
AI 기반 코드 어시스턴트가 특정 함수나 클래스에 대한 유닛 테스트 코드를 자동으로 생성하여 개발자가 수동으로 작성하는 시간을 절약하고, 테스트 커버리지를 높입니다. 예를 들어, calculate_total(items, discount_rate) 함수가 있을 때, AI가 다양한 입력값과 엣지 케이스를 고려한 테스트 케이스를 자동으로 만들어줍니다.

지능형 검색 및 정보 추출: RAG 패턴의 힘
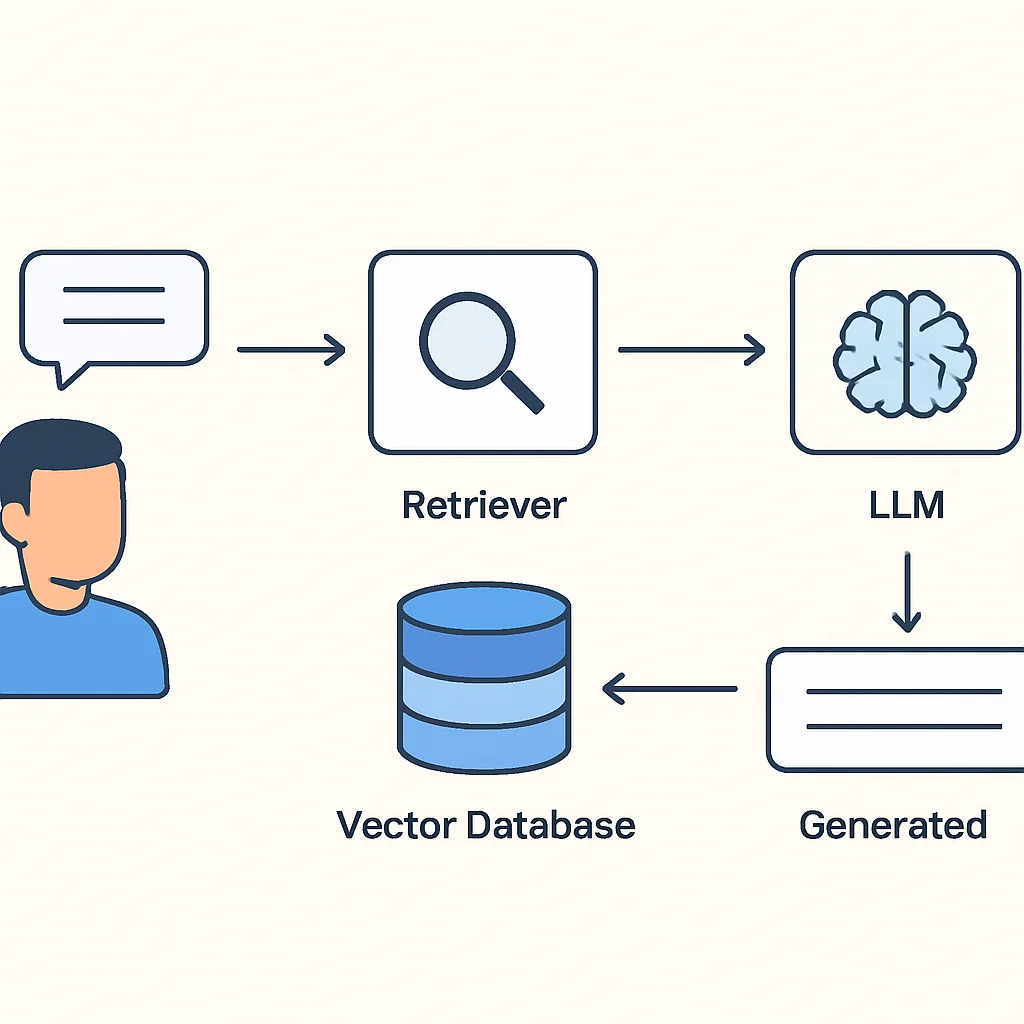
LLM은 방대한 지식을 가지고 있지만, 최신 정보나 특정 도메인에 특화된 정보에는 한계가 있습니다. 이를 보완하기 위해 ‘검색 증강 생성(RAG, Retrieval Augmented Generation)’ 패턴이 2026년 AI 애플리케이션 개발의 핵심 기법으로 자리 잡았습니다. RAG는 외부 데이터베이스나 문서에서 관련 정보를 검색한 후, 이 정보를 LLM에 전달하여 답변의 정확성과 신뢰성을 높이는 방식입니다.
개발자들은 RAG를 활용하여 기업 내부 문서 검색 시스템, 고객 지원 챗봇, 법률 및 의료 정보 시스템 등 다양한 분야에서 AI의 ‘환각(Hallucination)’ 현상을 줄이고, 최신 정보를 기반으로 한 정확한 답변을 제공할 수 있습니다. 벡터 데이터베이스(예: Pinecone, Weaviate, ChromaDB)는 RAG 시스템에서 관련 문서를 효율적으로 검색하는 데 필수적인 기술입니다.
다음은 RAG 시스템의 기본적인 동작 원리를 설명하는 개념적인 코드입니다. 실제 구현에서는 임베딩 모델, 벡터 데이터베이스, LLM 연동 등 복잡한 과정이 필요합니다.
코드 설명
이 파이썬 코드는 RAG(검색 증강 생성) 시스템의 핵심 아이디어를 보여줍니다. 사용자의 질문이 들어오면, 먼저 미리 준비된 문서 집합에서 질문과 가장 관련성이 높은 문서를 검색합니다. 그 다음, 검색된 문서의 내용과 원래 질문을 함께 LLM에 전달하여, LLM이 이 문맥을 바탕으로 정확하고 정보가 풍부한 답변을 생성하도록 합니다. 이는 LLM의 한계인 ‘환각’을 줄이고 최신 정보 반영을 돕는 강력한 패턴입니다.
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 1. 문서 집합 (실제로는 벡터 데이터베이스에 저장)
documents = {
"doc1": "권퓨터 블로그는 AI, 개발 트렌드, IT 기술 활용법에 대한 글을 제공합니다.",
"doc2": "2026년 AI 트렌드는 멀티모달 LLM과 생성형 AI의 실전 활용이 중요합니다.",
"doc3": "개발자는 LLM을 통해 코드 생성 및 자동화를 할 수 있습니다.",
"doc4": "RAG는 LLM의 정확성을 높이는 데 사용되는 중요한 패턴입니다.",
"doc5": "소형 LLM은 온디바이스 AI 구현에 유리하며 비용 효율적입니다."
}
# 2. 문서 임베딩 (간단화를 위해 임의의 벡터 사용, 실제는 임베딩 모델 사용)
# 각 문서를 5차원 벡터로 표현했다고 가정
document_embeddings = {
"doc1": np.array([0.1, 0.2, 0.7, 0.4, 0.3]),
"doc2": np.array([0.8, 0.6, 0.1, 0.2, 0.5]),
"doc3": np.array([0.2, 0.3, 0.8, 0.5, 0.4]),
"doc4": np.array([0.7, 0.5, 0.2, 0.8, 0.1]),
"doc5": np.array([0.6, 0.1, 0.4, 0.3, 0.9])
}
# 3. 질문 임베딩 함수 (실제는 임베딩 모델 사용)
def get_query_embedding(query_text):
# 질문과 유사한 임의의 벡터 반환 (실제로는 AI 모델이 임베딩 생성)
if "AI 트렌드" in query_text:
return np.array([0.75, 0.65, 0.15, 0.25, 0.55])
elif "개발자 활용" in query_text:
return np.array([0.25, 0.35, 0.75, 0.55, 0.45])
elif "RAG" in query_text:
return np.array([0.65, 0.55, 0.25, 0.75, 0.15])
else:
return np.array([0.1, 0.1, 0.1, 0.1, 0.1])
# 4. 관련 문서 검색 함수 (Retrieval)
def retrieve_relevant_documents(query_embedding, top_k=2):
similarities = {}
for doc_id, doc_emb in document_embeddings.items():
similarity = cosine_similarity(query_embedding.reshape(1, -1), doc_emb.reshape(1, -1))[0][0]
similarities[doc_id] = similarity
# 유사도에 따라 정렬하여 상위 k개 문서 반환
sorted_docs = sorted(similarities.items(), key=lambda item: item[1], reverse=True)
relevant_docs_content = []
for doc_id, _ in sorted_docs[:top_k]:
relevant_docs_content.append(documents[doc_id])
return relevant_docs_content
# 5. LLM 호출 함수 (Generation, 매우 간소화된 버전)
def generate_response_with_llm(query, context):
context_str = "\n".join(context)
# 실제 LLM은 이 context를 바탕으로 답변을 생성합니다.
# 여기서는 간단히 컨텍스트와 질문을 합쳐서 반환
if context:
return f"제공된 정보를 바탕으로 답변합니다: '{context_str}'. 질문: '{query}'"
else:
return f"제공된 정보가 충분하지 않아 일반적인 답변을 드립니다. 질문: '{query}'"
# RAG 시스템 실행 예시
user_query = "2026년 AI 트렌드는 무엇인가요?"
query_emb = get_query_embedding(user_query)
retrieved_context = retrieve_relevant_documents(query_emb)
final_response = generate_response_with_llm(user_query, retrieved_context)
print("--- RAG 시스템 실행 시작 ---")
print(f"사용자 질문: {user_query}")
print(f"검색된 관련 문서: {retrieved_context}")
print(f"LLM 최종 답변: {final_response}")
user_query_2 = "권퓨터 블로그는 어떤 내용을 다루나요?"
query_emb_2 = get_query_embedding(user_query_2)
retrieved_context_2 = retrieve_relevant_documents(query_emb_2)
final_response_2 = generate_response_with_llm(user_query_2, retrieved_context_2)
print(f"\n사용자 질문: {user_query_2}")
print(f"검색된 관련 문서: {retrieved_context_2}")
print(f"LLM 최종 답변: {final_response_2}")
주의사항
합성 데이터는 실제 데이터의 분포를 완벽하게 반영하지 못할 수 있으며, 생성 과정에서 원본 데이터의 편향이 증폭될 위험도 있습니다. 따라서 실제 배포 전에는 반드시 생성된 데이터의 품질과 모델 성능에 미치는 영향을 충분히 검증해야 합니다.
콘텐츠 및 미디어 생성: 창의적 작업의 확장
생성형 AI는 텍스트뿐만 아니라 이미지, 비디오, 오디오 등 다양한 형태의 콘텐츠를 창조하는 데 탁월한 능력을 보여줍니다. DALL-E, Midjourney, Stable Diffusion과 같은 Text-to-Image 모델들은 텍스트 프롬프트만으로 고품질의 이미지를 생성하며, Text-to-Video 모델은 짧은 텍스트 설명으로 동영상을 만들어냅니다. 또한, Text-to-Audio 기술은 배경 음악이나 음성 효과를 자동으로 생성하기도 합니다.
개발자들은 이러한 생성형 미디어 AI를 활용하여 게임 에셋, 마케팅 콘텐츠, 웹사이트 디자인 요소, 심지어는 전체 애니메이션이나 짧은 영화까지 제작할 수 있습니다. 이는 콘텐츠 제작에 필요한 시간과 비용을 획기적으로 줄여주며, 개인 개발자나 소규모 팀도 고품질의 미디어 콘텐츠를 쉽게 만들 수 있도록 지원합니다. 예를 들어, 게임 개발에서 필요한 수백 가지의 아이템 아이콘이나 배경 이미지를 AI로 빠르게 생성하고, 이를 기반으로 개발자가 수정 및 보완하는 워크플로우를 구축할 수 있습니다.
장점
✓ 제작 시간 단축: 수작업 대비 압도적인 속도로 콘텐츠 생성
✓ 비용 절감: 전문 디자이너/아티스트 고용 비용 절감
✓ 창의성 증폭: 다양한 아이디어와 스타일을 즉시 시각화하여 탐색 가능
✓ 개인화 콘텐츠: 사용자 맞춤형 미디어 콘텐츠 실시간 생성
단점
✗ 저작권 문제: AI 생성 콘텐츠의 저작권 귀속 및 침해 문제
✗ 품질 일관성: 특정 스타일이나 브랜드 가이드라인 준수 어려움
✗ ‘프롬프트 장인’ 필요: 원하는 결과를 얻기 위한 정교한 프롬프트 엔지니어링 능력 요구
✗ 윤리적 문제: 딥페이크 등 악용 가능성
문제 해결
AI 프로젝트, 이것만 알면 성공!
프롬프트 엔지니어링의 어려움과 해결책
LLM의 성능은 얼마나 효과적으로 질문(프롬프트)을 작성하느냐에 따라 크게 달라집니다. 명확하고 구체적인 프롬프트를 작성하는 것은 마치 AI와 대화하는 기술과 같습니다. 잘못된 프롬프트는 엉뚱하거나 불완전한 답변을 초래할 수 있습니다.
해결 — 구조화된 프롬프트와 CoT(Chain-of-Thought) 기법 활용
프롬프트 엔지니어링은 LLM을 효과적으로 활용하기 위한 핵심 기술입니다. 단순히 질문을 던지는 것을 넘어, LLM이 사고 과정을 거치도록 유도하는 Chain-of-Thought(CoT) 프롬프팅 기법은 복잡한 문제 해결 능력을 비약적으로 향상시킵니다. 또한, 역할 부여, 제약 조건 명시, 예시 제공 등 구조화된 프롬프트 작성 방법을 익히는 것이 중요합니다. LangChain과 같은 프레임워크는 이러한 프롬프트 작성을 위한 다양한 템플릿과 도구를 제공합니다.
코드 설명
이 프롬프트는 LLM에게 특정 역할을 부여하고, 단계별 사고 과정을 거쳐 문제에 대한 해결책을 도출하도록 유도하는 CoT(Chain-of-Thought) 기법의 예시입니다. “단계별로 생각하고…”라는 지시어를 통해 LLM이 논리적인 추론 과정을 거치도록 함으로써, 더 정확하고 심층적인 답변을 얻을 수 있습니다.
"당신은 IT 전문가입니다. 다음 문제에 대해 단계별로 생각하고, 각 단계를 설명한 후 최종 해결책을 제시하세요.
문제: '파이썬에서 비동기 프로그래밍을 할 때, 와 키워드는 어떻게 작동하며, 어떤 상황에 주로 사용되나요?'"
비용 효율적인 LLM 운용의 필요성
대규모 LLM API를 사용하는 것은 강력한 성능을 제공하지만, 사용량에 비례하여 발생하는 비용은 무시할 수 없는 수준입니다. 특히 대규모 트래픽이 예상되는 서비스에서는 비용 최적화가 필수적입니다.
해결 — SLM 활용, RAG, 캐싱, 배치 추론 전략
비용 효율적인 LLM 운용을 위해서는 여러 전략을 조합해야 합니다. 우선, 모든 작업에 최고성능의 대규모 LLM을 사용할 필요는 없습니다. 간단한 작업에는 GPT-4o-mini나 Phi-3와 같은 소형 LLM을 활용하여 비용을 절감할 수 있습니다. 또한, 위에서 설명한 RAG 패턴을 통해 LLM에 전달하는 입력 토큰 수를 줄여 비용을 최적화할 수 있습니다.
자주 발생하는 질의에 대한 답변을 캐싱(Caching)하여 LLM 호출 횟수를 줄이는 것도 효과적입니다. 대규모 요청이 예상될 때는 실시간 추론보다는 배치 추론(Batch Inference)을 사용하여 API 호출 비용을 낮출 수 있습니다. 마지막으로, 모델 양자화(Quantization)와 같은 기술을 통해 모델 크기를 줄여 온디바이스 배포를 고려하는 것도 장기적인 비용 절감에 기여합니다.
핵심 포인트
LLM 프로젝트의 성공을 위해서는 프롬프트 엔지니어링 기술을 숙달하고(CoT, 구조화), 소형 LLM, RAG, 캐싱, 배치 추론 등 다양한 비용 최적화 전략을 결합하여 효율적인 운용 방안을 마련해야 합니다.
마무리
2026년, AI와 함께 성장하는 개발자의 미래
지금까지 2026년 개발자들이 주목해야 할 LLM과 생성형 AI의 주요 트렌드와 실전 활용법에 대해 자세히 살펴보았습니다. 멀티모달 LLM의 등장으로 AI의 이해 범위가 확장되고, 에이전트 기반 시스템으로 자율적인 작업 수행 능력이 강화되었으며, 소형 LLM을 통해 효율성과 접근성이 크게 향상되었습니다.
또한, 코드 생성 및 자동화를 통한 생산성 극대화, RAG 패턴을 활용한 지능형 검색, 생성형 AI를 통한 데이터 증강 및 콘텐츠 생성 등 개발 현장에서 AI를 적용할 수 있는 다양한 실제 사례들을 알아보았습니다. 물론, 프롬프트 엔지니어링의 어려움이나 비용 효율적인 운용 방안과 같은 도전 과제들도 존재하지만, 이를 해결하기 위한 기술과 전략 또한 빠르게 발전하고 있습니다.
2026년은 AI 기술이 개발자들의 일상에 더욱 깊숙이 파고드는 한 해가 될 것입니다. 이러한 변화를 단순히 수용하는 것을 넘어, 능동적으로 학습하고 적용하는 개발자만이 빠르게 변화하는 기술 환경 속에서 경쟁력을 확보할 수 있습니다. AI는 개발자의 일자리를 위협하는 존재가 아니라, 오히려 개발자의 역량을 증폭시키고 새로운 가치를 창출할 수 있는 강력한 파트너입니다.
권퓨터는 앞으로도 여러분이 AI 기술을 쉽고 재미있게 이해하고, 실제 프로젝트에 적용할 수 있도록 최신 트렌드와 실용적인 정보를 계속해서 공유할 예정입니다. 끊임없이 배우고 탐험하며, AI와 함께 더욱 멋진 미래를 만들어나가는 개발자 여러분을 응원합니다!

자주 묻는 질문 (FAQ)
Q. 2026년 개발자가 꼭 알아야 할 AI 트렌드는 무엇인가요?
2026년에는 멀티모달 LLM, 에이전트 기반 LLM 시스템, 그리고 소형 LLM(SLM) 및 온디바이스 AI의 발전이 핵심 트렌드입니다. 이러한 기술들은 AI의 이해 범위와 자율성을 높이고, 효율성과 접근성을 개선하여 다양한 개발 분야에 혁신을 가져올 것입니다.
Q. 생성형 AI를 활용하여 개발 생산성을 높이는 구체적인 방법은 무엇인가요?
생성형 AI는 코드 자동 생성 및 완성, 리팩토링, 유닛 및 통합 테스트 코드 생성 등을 통해 개발 생산성을 크게 높일 수 있습니다. GitHub Copilot과 같은 도구를 활용하여 반복적인 코딩 작업을 줄이고, 핵심 로직 개발에 집중하며, 새로운 기술을 빠르게 학습할 수 있습니다.
Q. LLM의 ‘환각’ 현상을 줄이고 정확성을 높이는 방법은 무엇인가요?
LLM의 환각 현상을 줄이고 답변의 정확성을 높이려면 RAG(검색 증강 생성) 패턴을 활용하는 것이 효과적입니다. 외부 데이터베이스나 문서를 검색하여 관련 정보를 LLM에 컨텍스트로 제공함으로써, LLM이 최신 정보를 기반으로 신뢰성 높은 답변을 생성하도록 유도할 수 있습니다.
Q. 소형 LLM(SLM)이 대규모 LLM에 비해 어떤 장점을 가지나요?
소형 LLM은 대규모 LLM 대비 낮은 운영 비용, 짧은 지연 시간, 강화된 개인정보 보호 기능을 제공합니다. 이는 모바일 앱, 엣지 컴퓨팅, 임베디드 시스템 등 로컬 환경에서 AI 기능을 구현하는 데 매우 유리하며, 네트워크 연결 없이도 작동할 수 있습니다.
긴 글을 읽어주셔서 감사합니다!
2026년 AI 트렌드를 통해 개발자 여러분의 성장과 혁신에 도움이 되었기를 바랍니다.
궁금한 점이 있으면 언제든지 댓글로 남겨주세요! 권퓨터가 성심성의껏 답변해드리겠습니다.