요약
Prometheus & Grafana 시작 가이드 2026
2026년, 여러분의 서버와 애플리케이션 상태를 실시간으로 파악하고 싶으신가요? Prometheus와 Grafana로 강력한 모니터링 시스템을 직접 구축하는 방법을 쉽고 자세하게 알려드립니다.
핵심 키워드: Prometheus, Grafana, 서버 모니터링, 실시간 대시보드
이 글의 순서
1 2026년, 왜 모니터링이 필수일까요?
2 Prometheus, 지표 수집의 심장
3 Grafana, 시각화의 마법사
4 모니터링 시스템, 직접 구축해볼까요?
5 더 나은 모니터링을 위한 심화 팁
6 자주 묻는 질문 (FAQ)
7 마치며: 안정적인 서비스의 시작
도입
2026년, 왜 모니터링이 필수일까요?
안녕하세요, 권퓨터입니다! 2026년 현재, IT 서비스 환경은 그 어느 때보다 복잡하고 다이내믹하게 변화하고 있습니다. 클라우드, 마이크로서비스, 컨테이너 기술의 확산으로 인해 단일 서버가 아닌 수많은 컴포넌트들이 유기적으로 연결되어 동작하죠. 이러한 환경에서 안정적인 서비스를 제공하기 위해서는 실시간으로 시스템의 상태를 파악하고, 문제가 발생하기 전에 미리 감지하거나, 발생 즉시 원인을 찾아 해결하는 능력이 필수적입니다. 바로 이 지점에서 Prometheus와 Grafana를 활용한 서버 모니터링 시스템 구축이 빛을 발합니다.
과거에는 서버 한두 대만 모니터링해도 충분했지만, 이제는 수십, 수백 대의 서버와 컨테이너, 그리고 각 애플리케이션의 내부 지표까지 통합적으로 관리해야 합니다. 수동으로 모든 로그를 확인하고 지표를 분석하는 것은 불가능에 가깝죠. 그래서 자동화되고 시각화된 모니터링 시스템은 단순히 장애 대응을 넘어, 서비스 성능 최적화와 사용자 경험 향상에도 결정적인 역할을 합니다. 이번 가이드에서는 이 강력한 두 도구를 활용해 여러분만의 모니터링 시스템을 “뚝딱” 만들어보는 여정을 떠나보겠습니다.
“안정적인 서비스는 꼼꼼한 모니터링에서 시작됩니다. 보이지 않는 문제를 미리 찾아내고, 고객에게 최고의 경험을 선사하세요!”
— 권퓨터의 모니터링 철학
Prometheus와 Grafana는 오픈소스 기반의 모니터링 스택으로, 유연성과 확장성 덕분에 많은 기업과 개발자들에게 사랑받고 있습니다. Prometheus는 다양한 소스에서 지표를 수집하고 저장하는 시계열 데이터베이스(TSDB) 역할을 하며, 강력한 쿼리 언어인 PromQL을 제공합니다. Grafana는 이렇게 수집된 데이터를 아름답고 직관적인 대시보드로 시각화하여 한눈에 시스템 상태를 파악할 수 있게 돕습니다. 이 둘의 조합은 마치 눈과 뇌처럼 유기적으로 작동하며, 여러분의 인프라를 든든하게 지켜줄 것입니다.
핵심 포인트
Prometheus는 지표 수집 및 저장을, Grafana는 시각화 및 알림을 담당하는 오픈소스 모니터링 스택입니다. 이 둘의 조합은 현대 IT 인프라 모니터링의 표준으로 자리 잡고 있습니다.
분석
Prometheus, 지표 수집의 심장
Prometheus의 아키텍처 이해하기
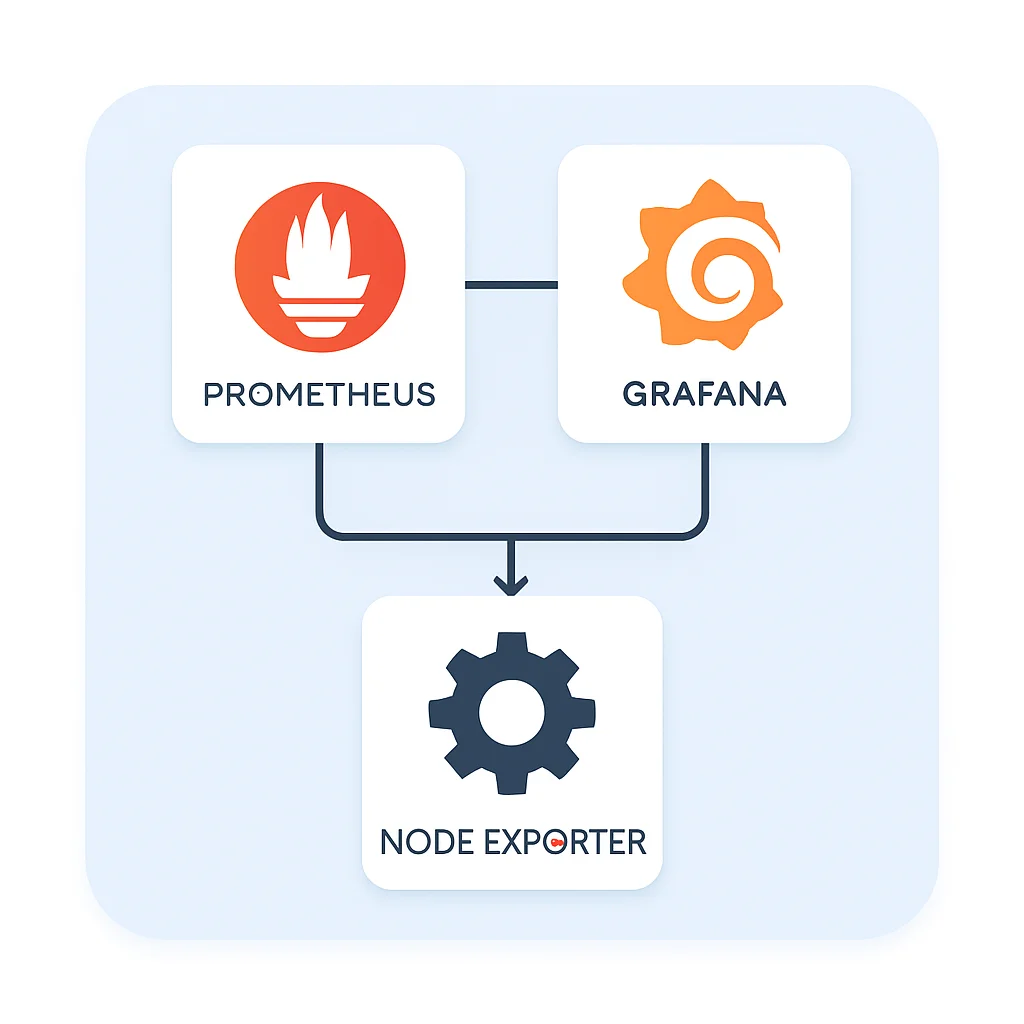
Prometheus는 단일 구성 요소가 아닌 여러 컴포넌트가 유기적으로 연결된 시스템입니다. 그 핵심은 시계열 데이터베이스(TSDB)를 내장한 Prometheus 서버입니다. 이 서버는 설정된 대상(타겟)으로부터 지표를 주기적으로 “긁어오는(Scraping)” 방식으로 데이터를 수집합니다. 지표를 제공하는 대상은 일반적으로 Exporter라고 불립니다.
주요 컴포넌트는 다음과 같습니다:
- Prometheus Server: 지표를 수집하고 저장하며, PromQL을 통해 쿼리할 수 있는 핵심 엔진입니다.
- Exporters: 모니터링 대상(OS, 데이터베이스, 애플리케이션 등)의 지표를 Prometheus가 이해할 수 있는 형식으로 노출하는 작은 서비스입니다. 예를 들어,
Node Exporter는 서버의 CPU, 메모리, 디스크 I/O 같은 OS 지표를 제공합니다. - Pushgateway: 짧은 수명을 가진 배치 작업이나 푸시 기반의 지표 수집이 필요할 때 사용됩니다. 일반적으로 Prometheus는 풀(Pull) 모델이지만, Pushgateway는 예외적인 상황에 활용됩니다.
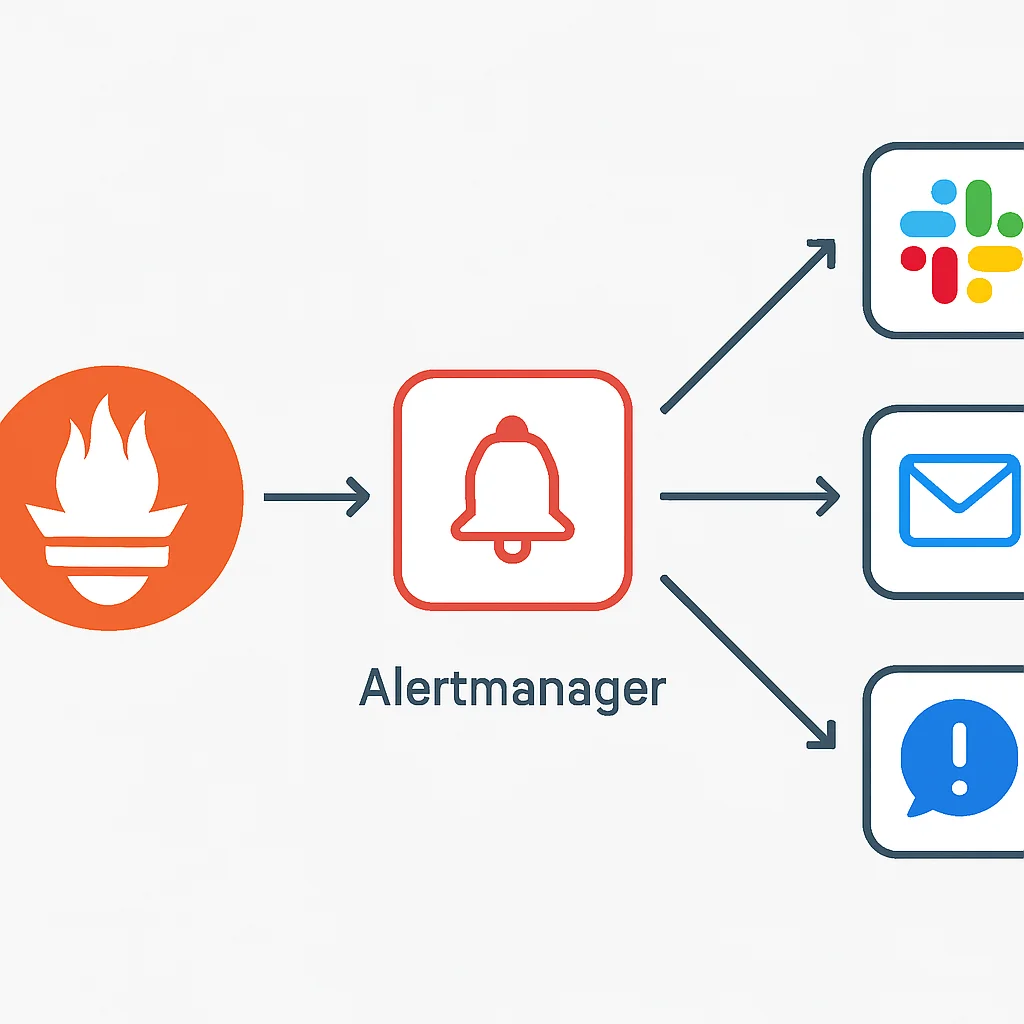
- Alertmanager: Prometheus 서버가 설정된 임계값(Alert Rule)을 초과하는 지표를 감지하면, Alertmanager로 알림을 보냅니다. Alertmanager는 이 알림을 중복 제거, 그룹화하여 Slack, 이메일 등 다양한 채널로 전송합니다.
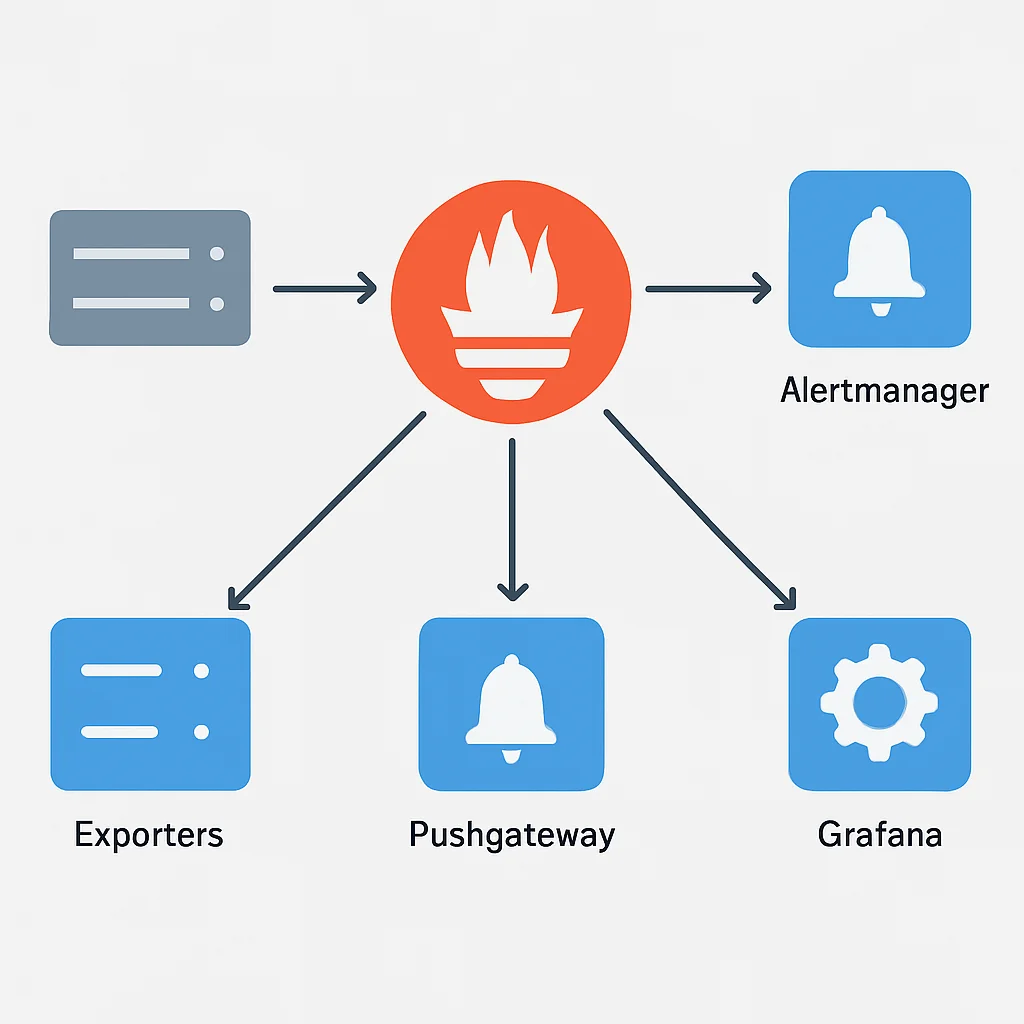
Prometheus의 가장 큰 특징은 Pull 모델을 사용한다는 것입니다. 즉, Prometheus 서버가 직접 모니터링 대상에 접속하여 지표를 가져옵니다. 이 방식은 모니터링 대상에 에이전트를 설치하고 관리하는 부담을 줄여주며, 서버 장애 시에도 Prometheus는 정상적으로 동작하여 지표를 수집하려는 시도를 계속할 수 있습니다.
핵심 포인트
Prometheus는 Pull 모델을 기반으로 Exporter로부터 지표를 수집하고, Alertmanager를 통해 알림을 관리하는 분산 아키텍처를 가집니다. 이는 유연하고 강력한 모니터링 시스템을 가능하게 합니다.
Prometheus 설정과 PromQL 활용
Prometheus는 prometheus.yml 파일을 통해 설정됩니다. 이 파일에는 어떤 대상을 모니터링할지(scrape_configs), 얼마나 자주 지표를 가져올지(scrape_interval), 그리고 어떤 알림 규칙을 적용할지(rule_files) 등이 정의됩니다.
코드 설명
아래는 기본적인 Prometheus 설정 파일 예시입니다. Prometheus 자신과 Node Exporter를 모니터링 대상으로 추가하는 방법을 보여줍니다.
global:
scrape_interval: 15s # 15초마다 지표 수집
evaluation_interval: 15s # 15초마다 규칙 평가
scrape_configs:
- job_name: 'prometheus' # Prometheus 자체 모니터링
static_configs:
- targets: ['localhost:9090'] # Prometheus 서버 주소
- job_name: 'node_exporter' # Node Exporter 모니터링
static_configs:
- targets: ['localhost:9100'] # Node Exporter 주소 (별도 설치 필요)
labels:
instance: 'my-server-01' # 인스턴스 식별을 위한 레이블 추가Prometheus의 진정한 힘은 강력한 쿼리 언어인 PromQL에서 나옵니다. PromQL을 사용하면 수집된 시계열 데이터를 실시간으로 필터링하고, 집계하고, 변환하여 원하는 정보를 추출할 수 있습니다. 예를 들어, 특정 서버의 CPU 사용률을 보거나, 모든 서버의 평균 메모리 사용량을 계산하거나, 지난 5분 동안 HTTP 요청 오류율이 특정 임계값을 초과했는지 확인할 수 있습니다.
“PromQL은 Prometheus의 언어입니다. 이 언어를 마스터하면 여러분의 인프라에서 어떤 질문이든 답을 얻을 수 있습니다!”
— PromQL 전문가 권퓨터
몇 가지 PromQL 예시를 살펴볼까요?
- 서버 전체의 CPU 사용률 (평균):
100 - avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100 - 남은 디스크 공간 (바이트):
node_filesystem_avail_bytes - HTTP 요청 총량:
sum(rate(http_requests_total[5m]))
코드 설명
아래 PromQL 쿼리는 특정 인스턴스(my-server-01)의 지난 5분간의 평균 CPU 사용률을 계산합니다. irate 함수는 빠르게 변화하는 카운터 지표의 초당 증가율을 계산하는 데 유용합니다.
100 - avg(irate(node_cpu_seconds_total{instance="my-server-01:9100", mode="idle"}[5m])) * 100PromQL은 다양한 함수와 연산자를 제공하여 복잡한 지표 분석을 가능하게 합니다. Grafana 대시보드를 구축할 때 이 PromQL 쿼리들이 핵심적인 역할을 하게 됩니다.
시각화
Grafana, 시각화의 마법사
Grafana의 역할과 Prometheus 연동
Prometheus가 지표를 수집하고 저장하는 ‘뇌’라면, Grafana는 이 데이터를 직관적으로 보여주는 ‘눈’과 같습니다. Grafana는 다양한 데이터 소스(Prometheus, InfluxDB, Elasticsearch 등)를 지원하며, 수집된 데이터를 아름답고 기능적인 대시보드로 시각화하는 데 특화되어 있습니다. 그래프, 테이블, 게이지 등 여러 패널 타입을 제공하여 사용자가 원하는 방식으로 데이터를 표현할 수 있습니다.
Grafana를 Prometheus와 연동하는 것은 매우 간단합니다. Grafana에 데이터 소스로 Prometheus를 추가하고, Prometheus 서버의 주소를 지정해주면 됩니다. 이후부터 Grafana는 Prometheus에 PromQL 쿼리를 보내 데이터를 가져와 대시보드에 표시합니다.
“데이터는 그 자체로 의미를 가지지만, 시각화를 통해 비로소 ‘통찰’이 됩니다. Grafana는 이 통찰을 가능하게 하는 최고의 도구죠.”
— 데이터 시각화의 중요성
대시보드 구축과 알림 설정
Grafana에서 대시보드를 만드는 과정은 매우 직관적입니다. “Add new panel”을 클릭하고, 원하는 그래프 타입을 선택한 후, PromQL 쿼리를 입력하면 됩니다. Grafana는 다양한 템플릿 변수를 지원하여 동적인 대시보드를 만들 수 있습니다. 예를 들어, 서버 목록을 드롭다운 메뉴로 만들고, 선택된 서버에 대한 지표만 표시하도록 설정할 수 있습니다.
Grafana는 수많은 공식 및 커뮤니티 대시보드 템플릿을 제공합니다. 특히 Node Exporter를 위한 대시보드(ID 1860, 11074 등)는 설치 후 바로 활용할 수 있어 초기 설정 시간을 크게 단축시켜 줍니다. 대시보드를 가져온 후에는 여러분의 환경에 맞게 커스터마이징하여 사용하면 됩니다.
코드 설명
Grafana 패널에서 CPU 사용률을 시각화하기 위한 PromQL 쿼리입니다. $instance는 Grafana 대시보드에서 설정한 템플릿 변수(드롭다운 메뉴 등)를 통해 동적으로 변경될 수 있습니다.
100 - (avg(irate(node_cpu_seconds_total{job="node_exporter", instance="$instance", mode="idle"}[5m])) * 100)Grafana는 시각화뿐만 아니라 강력한 알림(Alerting) 기능도 제공합니다. 특정 지표가 설정한 임계값을 넘어서거나, 데이터가 일정 시간 동안 수집되지 않을 경우 알림을 발생시킬 수 있습니다. 이 알림은 Prometheus의 Alertmanager와 연동되거나, Grafana 자체의 알림 시스템을 통해 Slack, PagerDuty, 이메일 등 다양한 채널로 전송될 수 있습니다. 2026년 최신 Grafana 버전에서는 통합 알림 시스템이 더욱 강화되어, 모든 알림을 한곳에서 관리할 수 있습니다.
핵심 포인트
Grafana는 Prometheus의 데이터를 직관적인 대시보드로 시각화하며, PromQL 쿼리를 활용해 다양한 패널을 구성할 수 있습니다. 또한, 강력한 알림 기능을 통해 잠재적인 문제에 빠르게 대응할 수 있게 돕습니다.
구축 가이드
모니터링 시스템, 직접 구축해볼까요?
이제 Prometheus와 Grafana를 활용한 서버 모니터링 시스템을 직접 구축해볼 시간입니다. 가장 쉽고 빠르게 시작하는 방법은 Docker Compose를 이용하는 것입니다. 이를 통해 Prometheus 서버, Grafana, 그리고 서버 지표를 수집할 Node Exporter를 한 번에 설정하고 실행할 수 있습니다.
1
Docker 및 Docker Compose 설치
아직 Docker와 Docker Compose가 설치되어 있지 않다면, 각 운영체제에 맞는 공식 가이드를 따라 설치해주세요. (예: Ubuntu의 경우 sudo apt-get install docker-ce docker-ce-cli containerd.io docker-compose-plugin)
2
프로젝트 디렉토리 생성 및 설정 파일 준비
작업할 디렉토리를 만들고, 그 안에 prometheus.yml 파일을 생성합니다. 이 파일은 Prometheus가 어떤 대상을 모니터링할지 정의합니다.
권퓨터 팁: prometheus.yml 파일은 ./prometheus 하위 디렉토리에 두는 것이 일반적입니다.
코드 설명
Prometheus의 기본 설정 파일입니다. Prometheus 서버 자신과 Node Exporter를 모니터링 대상으로 추가합니다. Node Exporter는 localhost:9100에서 지표를 노출하도록 설정합니다.
# prometheus.yml
global:
scrape_interval: 10s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node_exporter'
static_configs:
- targets: ['localhost:9100']
labels:
instance: 'local-server' # 이 서버를 식별할 이름3
Docker Compose 파일 작성
이제 docker-compose.yml 파일을 작성하여 Prometheus, Grafana, Node Exporter를 정의합니다. 이 파일은 모든 서비스의 설정과 네트워크를 한 번에 관리할 수 있게 해줍니다.
코드 설명
아래 docker-compose.yml 파일은 Prometheus, Grafana, Node Exporter 세 가지 서비스를 정의합니다. 각 서비스는 포트 매핑, 볼륨 마운트 등을 통해 설정됩니다. Grafana의 초기 비밀번호는 admin/admin으로 설정됩니다.
# docker-compose.yml
version: '3.8'
services:
prometheus:
image: prom/prometheus:v2.51.1 # 2026년 최신 안정 버전
container_name: prometheus
ports:
- "9090:9090"
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
networks:
- monitoring_network
grafana:
image: grafana/grafana:10.4.1 # 2026년 최신 안정 버전
container_name: grafana
ports:
- "3000:3000"
volumes:
- grafana_data:/var/lib/grafana
environment:
- GF_SECURITY_ADMIN_USER=admin
- GF_SECURITY_ADMIN_PASSWORD=admin
depends_on:
- prometheus
networks:
- monitoring_network
node_exporter:
image: prom/node-exporter:v1.8.0 # 2026년 최신 안정 버전
container_name: node_exporter
ports:
- "9100:9100"
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/host/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.mount-points-exclude=^/(dev|proc|sys|var/lib/docker/.+|var/run/docker.sock)($|/)'
networks:
- monitoring_network
volumes:
prometheus_data: {}
grafana_data: {}
networks:
monitoring_network:
driver: bridge