

요약
2026년 MLOps 시작 가이드: 모델 배포부터 모니터링까지 뚝딱!
AI 모델의 성공적인 운영을 위한 MLOps의 기본 개념과 2026년 최신 구축 전략을 소개합니다.
핵심 키워드: MLOps, 모델 배포, AI 모니터링
이 글의 순서
1 MLOps, 왜 지금 주목해야 할까요?
2 MLOps의 핵심 구성 요소 파헤치기
3 MLOps 파이프라인 단계별 구축 전략
4 주요 MLOps 도구 비교 분석: 2026년 선택 가이드
5 MLOps 도입 시 마주치는 문제와 현명한 해결책
6 성공적인 MLOps를 위한 실전 가이드
7 FAQ: MLOps에 대해 궁금한 점
배경 및 도입
MLOps, 왜 지금 주목해야 할까요?
안녕하세요, 권퓨터입니다! 2026년 현재, 인공지능(AI)은 우리 일상과 비즈니스에 깊숙이 스며들어 혁신을 이끌고 있습니다. 하지만 AI 모델을 단순히 개발하는 것을 넘어, 실제 서비스 환경에서 안정적으로 운영하고 지속적으로 개선하는 것은 또 다른 차원의 도전이죠. 여기서 등장하는 개념이 바로 MLOps (Machine Learning Operations)입니다.
과거에는 데이터 과학자들이 모델을 개발하면, 그 모델을 프로덕션 환경에 배포하는 과정이 수동적이고 비효율적인 경우가 많았습니다. 이로 인해 모델 배포에 몇 주에서 몇 달이 걸리기도 하고, 배포 후 성능 저하나 오류 발생 시 신속한 대응이 어려웠죠. AI 기술의 발전 속도가 빨라지면서 이러한 비효율성은 비즈니스 기회 손실로 직결되기 시작했습니다.
MLOps는 머신러닝 시스템의 개발(Dev), 배포(Ops), 운영(Ops) 전 과정을 자동화하고 표준화하여 효율성과 안정성을 극대화하는 방법론입니다. 소프트웨어 개발의 DevOps와 유사하지만, 데이터, 모델, 실험 관리 등 머신러닝 특유의 복잡성을 해결하는 데 초점을 맞춥니다. 2026년 현재, 글로벌 MLOps 시장은 약 15억 달러 규모로 추정되며, 연평균 25% 이상의 고속 성장을 이어가고 있습니다. 이는 기업들이 AI 모델의 가치를 극대화하기 위해 MLOps 도입을 필수적으로 고려하고 있음을 보여주는 명확한 지표입니다.
이 글에서는 MLOps의 기본 개념부터 실제 모델 배포, 모니터링 파이프라인 구축 방법까지 권퓨터와 함께 뚝딱 알아보는 시간을 가질 겁니다. AI 모델을 성공적으로 운영하고 싶은 모든 분들께 이 가이드가 큰 도움이 되기를 바랍니다.
핵심 포인트
MLOps는 AI 모델 개발과 운영의 간극을 메우고, 지속적인 배포와 개선을 통해 모델의 비즈니스 가치를 극대화하는 데 필수적인 방법론입니다.
핵심 내용
MLOps의 핵심 구성 요소 파헤치기
MLOps는 단순한 도구의 집합이 아니라, 머신러닝 모델의 생애 주기 전체를 관리하는 포괄적인 시스템입니다. 이 시스템은 여러 핵심 구성 요소들이 유기적으로 연결되어 작동합니다. 각 구성 요소를 자세히 살펴볼까요?
1. 데이터 관리 (Data Management)
데이터 버전 관리 및 파이프라인
데이터 수집 및 전처리 — 모델 학습에 필요한 데이터를 수집하고 정제하는 과정입니다. 데이터의 품질은 모델 성능에 직접적인 영향을 미치므로 매우 중요합니다.
데이터 버전 관리 (DVC) — 데이터셋은 모델만큼이나 자주 변경될 수 있습니다. 어떤 데이터로 어떤 모델을 학습했는지 추적하기 위해 데이터 버전 관리는 필수적입니다.
피처 스토어 (Feature Store) — 재사용 가능한 피처들을 중앙에서 관리하여 일관된 피처 엔지니어링을 가능하게 하고, 학습/추론 시 피처 불일치 문제를 방지합니다.
2. 모델 개발 및 실험 관리 (Model Development & Experiment Tracking)
코드, 파라미터, 결과 추적
모델 학습 및 튜닝 — 다양한 알고리즘과 하이퍼파라미터를 사용하여 모델을 학습하고 최적화합니다. 이 과정에서 수많은 실험이 이루어집니다.
실험 추적 (Experiment Tracking) — 어떤 코드로, 어떤 데이터셋을, 어떤 하이퍼파라미터로 학습하여 어떤 결과를 얻었는지 기록하고 비교 분석하는 시스템입니다. MLflow, Weights & Biases 등이 대표적입니다.
코드 버전 관리 — 모델 학습 코드, 전처리 스크립트 등 모든 코드는 Git과 같은 시스템으로 철저히 관리되어야 합니다.
3. 모델 레지스트리 (Model Registry)
모델의 중앙 저장소
모델 버전 관리 — 학습된 모델 파일과 메타데이터(성능 지표, 학습 데이터 정보 등)를 중앙 집중적으로 저장하고 관리합니다. 각 모델은 고유한 버전으로 관리됩니다.
모델 스테이징 — 개발, 스테이징, 프로덕션 등 모델의 배포 단계를 관리하여, 특정 버전의 모델이 어떤 단계에 있는지 쉽게 파악하고 제어할 수 있습니다.
모델 거버넌스 — 모델의 승인, 폐기 절차 등을 포함하여 모델의 생애 주기 전반에 걸친 관리를 용이하게 합니다.
4. CI/CD (Continuous Integration/Continuous Delivery) for ML
머신러닝 파이프라인 자동화
지속적 통합 (CI) — 코드 변경 시 자동으로 테스트를 실행하고, 모델 학습 파이프라인을 트리거하여 새로운 모델 버전을 생성합니다.
지속적 전달 (CD) — 검증된 모델을 자동으로 프로덕션 환경에 배포하거나, A/B 테스트 환경으로 전달합니다. 수동 개입을 최소화하여 배포 속도와 안정성을 높입니다.
파이프라인 오케스트레이션 — 데이터 전처리, 모델 학습, 모델 검증, 모델 배포 등 복잡한 MLOps 워크플로우를 정의하고 자동 실행합니다. Kubeflow Pipelines, Airflow 등이 활용됩니다.
5. 모델 배포 (Model Deployment)
모델을 서비스로 전환
서빙 인프라 — 모델을 API 엔드포인트 형태로 제공하여 애플리케이션에서 호출할 수 있도록 합니다. Kubernetes, Docker, 서버리스 함수 등이 사용됩니다.
A/B 테스트 및 Canary 배포 — 새로운 모델 버전을 점진적으로 배포하여 실제 환경에서의 성능을 검증하고 위험을 최소화합니다.
모델 최적화 — 배포 환경에 맞춰 모델을 경량화하거나 최적화하여 추론 속도를 향상시킵니다.
6. 모델 모니터링 및 재학습 (Model Monitoring & Retraining)
모델의 건강 상태 점검
성능 모니터링 — 배포된 모델의 예측 정확도, 지연 시간, 처리량 등 핵심 성능 지표를 실시간으로 추적합니다.
데이터 드리프트 감지 — 모델 학습 시 사용된 데이터 분포와 실제 서비스 환경에서 입력되는 데이터 분포의 변화를 감지합니다. 이는 모델 성능 저하의 주요 원인입니다.
자동 재학습 트리거 — 모델 성능 저하, 데이터 드리프트 감지 등 특정 조건이 충족되면 자동으로 모델 재학습 파이프라인을 트리거합니다.
핵심 포인트
MLOps의 각 구성 요소는 독립적으로 존재하기보다, 마치 톱니바퀴처럼 유기적으로 연결되어 모델의 개발부터 운영, 개선까지의 전체 생애 주기를 원활하게 만듭니다.
구축 전략
MLOps 파이프라인 단계별 구축 전략
MLOps 파이프라인은 모델이 아이디어 단계에서 실제 서비스로 이어지고, 다시 개선되는 순환 과정을 자동화하는 핵심적인 요소입니다. 각 단계를 어떻게 구축해야 할지 구체적인 전략을 살펴보겠습니다.
“지속적인 개선의 고리, MLOps의 심장입니다.”
— MLOps 파이프라인의 핵심 가치
단계 1: 데이터 수집 및 전처리 파이프라인 자동화
1
정확하고 신선한 데이터 확보
MLOps의 시작은 고품질 데이터입니다. 데이터 수집, 정제, 라벨링, 피처 엔지니어링 과정을 자동화하여 모델 학습에 항상 최신 데이터를 제공해야 합니다. 데이터 변경 시 자동으로 후속 파이프라인이 트리거되도록 설정하는 것이 중요합니다.
핵심 기술: Apache Airflow, Kubeflow Pipelines, AWS Step Functions 등 워크플로우 오케스트레이션 도구
데이터 버전 관리: DVC (Data Version Control)를 사용하여 데이터셋 변경 이력을 추적하고 재현성을 확보합니다.
단계 2: 모델 개발 및 실험 관리 자동화
2
효율적인 모델 학습 및 검증
데이터 과학자들이 모델을 개발하고 실험하는 과정에서 발생하는 모든 메타데이터를 자동으로 기록해야 합니다. 모델 학습 코드, 사용된 데이터 버전, 하이퍼파라미터, 성능 지표 등을 체계적으로 관리하여 최적의 모델을 선정하고 재현성을 높입니다.
핵심 기술: MLflow Tracking, Weights & Biases, Comet ML 등 실험 관리 플랫폼
모델 검증: 학습된 모델은 프로덕션 배포 전 엄격한 단위 테스트, 통합 테스트, 성능 테스트를 거쳐야 합니다. 예를 들어, tf.keras.Model.evaluate()나 scikit-learn의 metrics 모듈로 주요 지표(정확도, 정밀도, 재현율, F1-score 등)를 평가하고 기준치를 통과하는지 확인합니다.
단계 3: CI/CD 및 모델 배포 자동화
3
모델 배포의 빠르고 안정적인 경로
검증된 모델은 자동으로 프로덕션 환경에 배포되어야 합니다. 모델 배포는 단순히 모델 파일을 서버에 올리는 것을 넘어, API 엔드포인트 구성, 스케일링, 로드 밸런싱까지 포함합니다. CI/CD 파이프라인을 통해 코드 변경, 새로운 모델 학습, 모델 검증, 배포까지 전 과정이 매끄럽게 연결됩니다.
CI/CD 도구: Jenkins, GitLab CI/CD, GitHub Actions, Azure DevOps 등
모델 서빙: TensorFlow Serving, TorchServe, Seldon Core, NVIDIA Triton Inference Server 등
다음은 GitHub Actions를 사용하여 간단한 모델 학습 및 배포를 자동화하는 파이프라인의 예시입니다. 이 예시는 모델 학습 후 Docker 이미지로 빌드하고 컨테이너 레지스트리에 푸시하는 과정을 보여줍니다.
코드 설명
이 YAML 코드는 GitHub Actions 워크플로우를 정의합니다. main 브랜치에 푸시가 발생하면 실행되며, Python 환경을 설정하고, 모델 학습 스크립트를 실행한 후, 학습된 모델을 Docker 이미지로 빌드하여 GitHub Container Registry에 푸시합니다.
name: MLOps CI/CD Pipeline
on:
push:
branches:
- main
jobs:
build-and-deploy:
runs-on: ubuntu-latest
steps:
- name: 체크아웃 코드
uses: actions/checkout@v4
- name: Python 설정
uses: actions/setup-python@v5
with:
python-version: '3.9'
- name: 의존성 설치
run: |
pip install -r requirements.txt
- name: 모델 학습
run: |
python train_model.py # 모델 학습 스크립트 실행
- name: 학습된 모델 저장 (아티팩트)
uses: actions/upload-artifact@v4
with:
name: trained-model
path: ./model.pkl # 학습된 모델 파일 경로
- name: Docker 로그인
uses: docker/login-action@v3
with:
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Docker 이미지 빌드 및 푸시
run: |
docker build -t ghcr.io/${{ github.repository }}/ml-model:latest .
docker push ghcr.io/${{ github.repository }}/ml-model:latest
이 코드는 모델 학습(train_model.py)을 실행하고, 학습된 모델을 아티팩트로 저장한 다음, 이 모델을 포함하는 Docker 이미지를 빌드하여 컨테이너 레지스트리(GitHub Container Registry)에 푸시하는 과정을 보여줍니다. 실제 배포는 이 이미지를 Kubernetes 클러스터에 배포하는 추가 단계가 필요합니다.
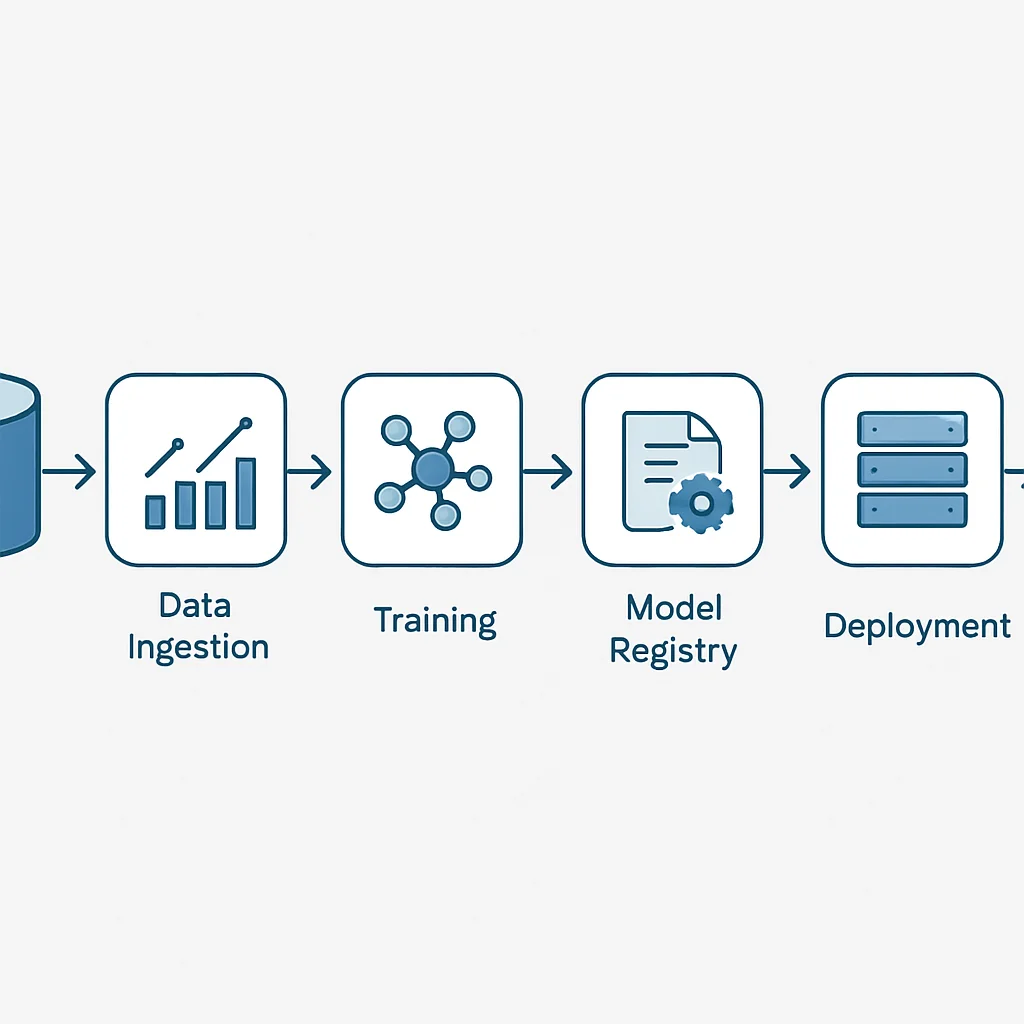

단계 4: 모델 모니터링 및 재학습 파이프라인 구축
4
배포 후 모델의 건강 관리
모델 배포가 끝이 아닙니다. 실제 서비스 환경에서 모델이 어떻게 작동하는지 지속적으로 모니터링하고, 성능 저하가 감지되면 자동으로 재학습을 트리거하여 모델을 업데이트해야 합니다. 이는 모델의 수명을 연장하고 비즈니스 가치를 유지하는 데 결정적입니다.
모니터링 도구: Prometheus, Grafana, Evidently AI, WhyLabs 등
재학습 전략: 주기적 재학습, 성능 임계치 기반 재학습, 데이터 드리프트 기반 재학습 등 다양한 전략을 고려할 수 있습니다.
핵심 포인트
MLOps 파이프라인의 핵심은 ‘자동화’입니다. 데이터 변경부터 모델 배포, 모니터링, 재학습까지 모든 과정을 자동화하여 사람의 개입을 최소화하고 효율성을 극대화해야 합니다.
도구 비교
주요 MLOps 도구 비교 분석: 2026년 선택 가이드
MLOps 생태계는 빠르게 발전하고 있으며, 다양한 오픈소스 및 상용 도구들이 존재합니다. 2026년 현재 가장 많이 활용되는 주요 MLOps 도구들을 비교 분석하여 여러분의 프로젝트에 적합한 선택을 돕겠습니다.
“도구는 목적을 위한 수단일 뿐, 핵심은 프로세스입니다.”
— MLOps 도구 선택의 지혜
주요 MLOps 도구 비교표 (2026년 기준)
아래 표는 대표적인 MLOps 도구들의 주요 특징을 비교한 것입니다. 각 도구는 강점이 다르므로, 팀의 기술 스택, 예산, 요구 사항에 맞춰 신중하게 선택해야 합니다.
2026년 트렌드: 하이브리드 클라우드와 온프레미스 환경을 아우르는 유연한 MLOps 솔루션에 대한 수요가 증가하고 있으며, 특정 클라우드 벤더에 종속되지 않는 오픈소스 기반 솔루션(MLflow + Kubeflow)의 조합도 여전히 강력한 선택지로 부상하고 있습니다. 또한, AI 모델의 설명 가능성(XAI)과 공정성(Fairness)을 높이는 기능이 MLOps 도구에 통합되는 추세입니다.
핵심 포인트
MLOps 도구를 선택할 때는 팀의 기술 스택, 인프라 환경(클라우드/온프레미스), 예산, 그리고 가장 중요한 ‘어떤 문제를 해결하고자 하는가’를 명확히 정의하는 것이 중요합니다.
문제 해결
MLOps 도입 시 마주치는 문제와 현명한 해결책
MLOps는 많은 이점을 제공하지만, 도입 과정에서 여러 가지 도전 과제에 직면할 수 있습니다. 일반적인 문제점들을 짚어보고, 그에 대한 현명한 해결책을 함께 찾아봅시다.
문제 1: 데이터/컨셉 드리프트로 인한 모델 성능 저하
문제 01
모델이 학습했던 세상과 현실이 달라졌어요!
모델은 특정 시점의 데이터로 학습됩니다. 하지만 시간이 지나면서 실제 서비스 환경의 데이터 분포(데이터 드리프트)나 데이터와 타겟 변수 간의 관계(컨셉 드리프트)가 변할 수 있습니다. 이는 모델의 예측 정확도를 급격히 떨어뜨리는 주요 원인입니다.
해결 — 지속적인 데이터 및 성능 모니터링
입력 데이터의 통계적 특성(평균, 표준편차, 분포 등)과 모델의 예측 결과(확률 분포, 오류율)를 지속적으로 모니터링해야 합니다. 일정 임계치를 벗어나면 경고를 발생시키고, 자동으로 재학습 파이프라인을 트리거하여 모델을 업데이트합니다. Evidently AI나 WhyLabs와 같은 도구를 활용하면 효과적입니다.
다음은 간단한 데이터 드리프트 감지 로직의 예시입니다. 학습 데이터와 실시간 데이터를 비교하여 특정 피처의 분포 변화를 감지합니다.
코드 설명
이 Python 코드는 두 개의 데이터셋(학습 데이터와 실시간 데이터)을 입력받아 특정 컬럼의 분포를 Kolmogorov-Smirnov (KS) 테스트로 비교합니다. KS 통계량이 임계값(예: 0.2)을 초과하면 데이터 드리프트가 발생했다고 판단하고 경고 메시지를 출력합니다.
import pandas as pd
from scipy.stats import ks_2samp
def detect_data_drift(baseline_data: pd.DataFrame, current_data: pd.DataFrame, feature_name: str, ks_threshold: float = 0.2) -> bool:
"""
주어진 피처에 대해 데이터 드리프트를 감지합니다.
KS (Kolmogorov-Smirnov) 테스트를 사용하여 두 데이터셋의 분포를 비교합니다.
Args:
baseline_data (pd.DataFrame): 모델 학습에 사용된 기준 데이터 (기준 분포).
current_data (pd.DataFrame): 현재 서비스에서 수집되는 데이터 (현재 분포).
feature_name (str): 드리프트를 감지할 피처의 이름.
ks_threshold (float): KS 통계량 임계값. 이 값을 초과하면 드리프트로 간주합니다.
Returns:
bool: 데이터 드리프트가 감지되면 True, 아니면 False.
"""
if feature_name not in baseline_data.columns or feature_name not in current_data.columns:
print(f"경고: '{feature_name}' 피처가 데이터프레임에 존재하지 않습니다.")
return False
baseline_feature = baseline_data[feature_name]
current_feature = current_data[feature_name]
# KS 테스트 수행
# statistic: 두 분포 간의 최대 절대 차이
# pvalue: 귀무가설(두 분포가 동일하다)을 기각할 확률
statistic, pvalue = ks_2samp(baseline_feature, current_feature)
print(f"피처 '{feature_name}'의 KS 통계량: {statistic:.4f}, p-value: {pvalue:.4f}")
# KS 통계량이 임계값을 초과하면 드리프트로 판단
if statistic > ks_threshold:
print(f"!!! 데이터 드리프트 감지: '{feature_name}' 피처의 분포가 기준 분포와 크게 다릅니다. (KS > {ks_threshold})")
return True
else:
print(f"데이터 드리프트 없음: '{feature_name}' 피처의 분포가 안정적입니다.")
return False
if __name__ == "__main__":
# 예시 데이터 생성
# 기준 데이터 (학습 데이터)
baseline_df = pd.DataFrame({
'feature_a': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'feature_b': [10, 12, 11, 13, 15, 14, 16, 17, 18, 19]
})
# 드리프트가 없는 현재 데이터
current_df_no_drift = pd.DataFrame({
'feature_a': [1.1, 2.2, 3.1, 4.3, 5.0, 6.1, 7.2, 8.0, 9.1, 10.0],
'feature_b': [10.5, 12.1, 11.3, 13.0, 15.2, 14.1, 16.0, 17.5, 18.2, 19.0]
})
# 드리프트가 있는 현재 데이터 (feature_a의 분포가 변화)
current_df_with_drift = pd.DataFrame({
'feature_a': [5, 6, 7, 8, 9, 10, 11, 12, 13, 14], # 평균이 높아짐
'feature_b': [10.5, 12.1, 11.3, 13.0, 15.2, 14.1, 16.0, 17.5, 18.2, 19.0]
})
print("--- 드리프트 없는 경우 ---")
drift_detected = detect_data_drift(baseline_df, current_df_no_drift, 'feature_a')
print(f"드리프트 감지 여부: {drift_detected}\n")
print("--- 드리프트 있는 경우 ---")
drift_detected = detect_data_drift(baseline_df, current_df_with_drift, 'feature_a')
print(f"드리프트 감지 여부: {drift_detected}\n")
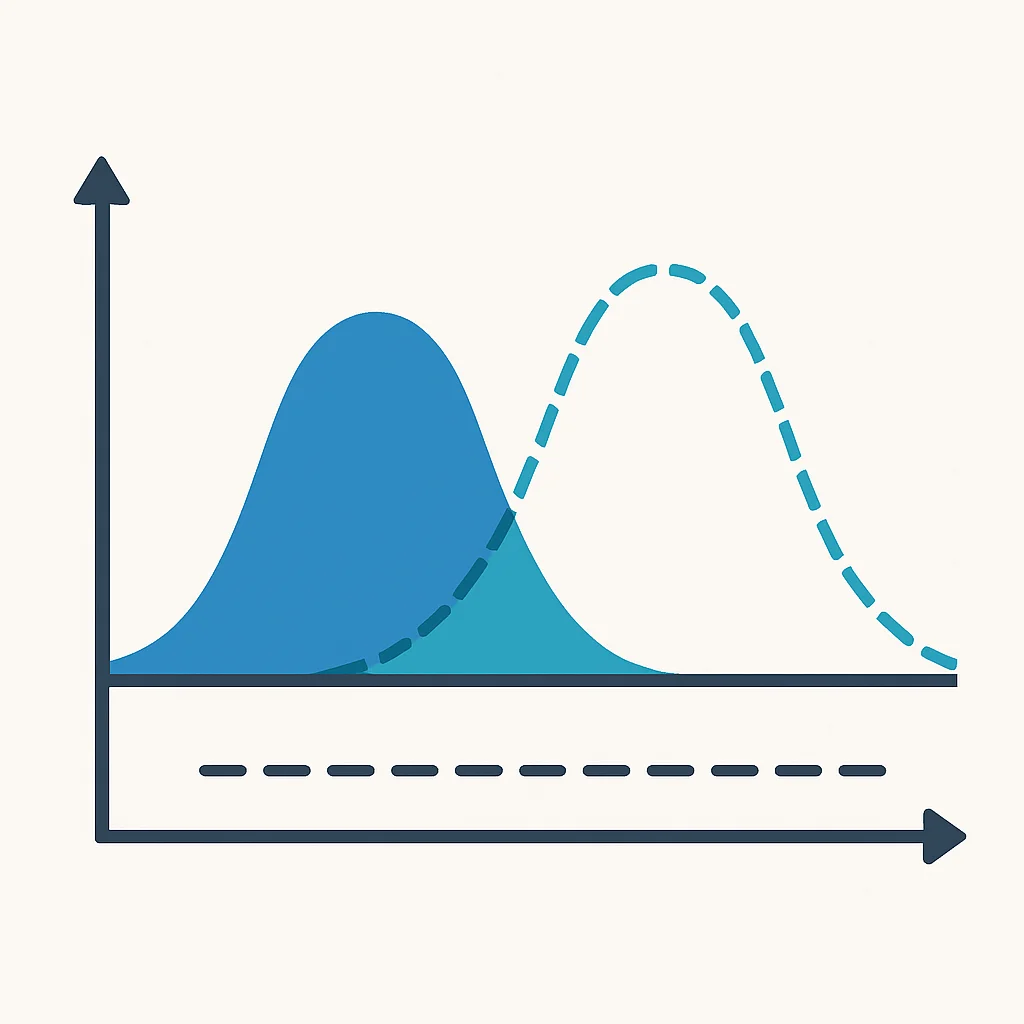
문제 2: 모델 버전 관리 및 재현성 확보의 어려움
문제 02
어떤 모델이 최신이고, 어떤 데이터로 학습했는지 헷갈려요!
여러 버전의 모델, 다양한 데이터셋, 수많은 실험 결과들이 뒤섞이면 어떤 모델이 최적인지, 어떻게 학습되었는지 추적하기가 매우 어려워집니다. 이는 모델의 재현성을 떨어뜨리고 문제 발생 시 원인 파악을 힘들게 합니다.
해결 — 통합된 모델 레지스트리 및 실험 관리 시스템
MLflow Model Registry나 Kubeflow 등 통합된 플랫폼을 사용하여 모델 파일뿐만 아니라 학습 코드, 데이터 버전, 하이퍼파라미터, 성능 지표 등 모든 관련 메타데이터를 중앙 집중적으로 관리해야 합니다. 각 모델 버전에 고유한 ID를 부여하고, 배포 단계를 명확히 구분하여 추적합니다. GitOps 원칙을 적용하여 인프라 및 배포 설정도 버전 관리하는 것이 좋습니다.
문제 3: 초기 투자 비용과 복잡성
문제 03
MLOps 시스템 구축, 너무 복잡하고 비싸지 않나요?
MLOps 시스템을 처음부터 완벽하게 구축하는 것은 상당한 시간, 비용, 전문 인력을 요구하는 복잡한 작업입니다. 특히 중소기업이나 스타트업에게는 큰 부담이 될 수 있습니다.
해결 — 점진적 도입과 클라우드 서비스 활용
처음부터 모든 것을 자동화하기보다, 가장 시급하고 효과가 큰 부분부터 MLOps를 도입하는 점진적 접근 방식을 취합니다. 예를 들어, 모델 배포 자동화부터 시작하거나, 데이터 드리프트 모니터링부터 시작할 수 있습니다. 또한, AWS SageMaker, Google Vertex AI와 같은 클라우드 기반 완전 관리형 MLOps 서비스를 활용하면 인프라 구축 및 관리에 대한 부담을 크게 줄일 수 있습니다. 초기에는 오픈소스 도구를 조합하여 최소한의 기능으로 시작하고, 필요에 따라 확장해 나가는 전략도 좋습니다.
주의사항
MLOps는 단순히 최신 기술을 도입하는 것이 아니라, 팀의 업무 방식과 문화를 변화시키는 과정입니다. 기술 도입 전 충분한 계획과 팀원 간의 합의가 필수적입니다.
핵심 포인트
MLOps 도입은 기술적 도전뿐만 아니라 조직 문화적 변화를 수반합니다. 문제를 예측하고 유연하게 대응하며, 점진적인 개선을 추구하는 것이 성공의 열쇠입니다.
실전 적용
성공적인 MLOps를 위한 실전 가이드
이제 MLOps의 개념과 주요 구성 요소, 그리고 발생할 수 있는 문제점과 해결책까지 알아보았습니다. 그렇다면 실제로 어떻게 MLOps를 성공적으로 적용할 수 있을까요? 몇 가지 실전 가이드를 제시합니다.
1. 작은 성공 사례부터 시작하세요 (PoC)
MLOps는 한 번에 모든 것을 구축하기보다, 작은 규모의 프로젝트나 특정 모델에 대해 MLOps 파이프라인을 시범적으로 구축해보는 것(Proof of Concept, PoC)이 좋습니다. 이를 통해 팀의 역량을 강화하고, 실제 환경에서의 문제점을 파악하며, 성공적인 레퍼런스를 만들어 다른 프로젝트로 확장할 수 있습니다.
활용 사례: 추천 시스템 MLOps
사용자 행동 데이터 변화에 민감한 추천 시스템은 MLOps 도입의 좋은 시작점입니다. 데이터 드리프트 모니터링을 통해 사용자 취향 변화를 감지하고, 자동 재학습 파이프라인으로 최신 트렌드를 반영한 추천 모델을 빠르게 배포할 수 있습니다. 이는 사용자 만족도와 서비스 매출 증대에 직접적인 영향을 미 미칠 수 있습니다.
2. 데이터 과학자, 엔지니어, 운영팀 간의 긴밀한 협업
MLOps는 데이터 과학, 머신러닝 엔지니어링, 소프트웨어 엔지니어링, 운영 등 다양한 분야의 전문가들이 협력해야 성공할 수 있습니다. 각 팀의 역할과 책임을 명확히 하고, 정기적인 커뮤니케이션을 통해 서로의 니즈를 이해하고 솔루션을 함께 만들어나가야 합니다. 예를 들어, 데이터 과학자는 모델의 요구사항과 평가 지표를 정의하고, 엔지니어는 이를 프로덕션에 적합한 형태로 구현하며, 운영팀은 안정적인 인프라를 제공하는 식입니다.
3. 측정하고, 학습하고, 개선하세요 (Measure, Learn, Improve)
모든 MLOps 파이프라인은 지속적인 피드백 루프를 통해 개선되어야 합니다. 모델의 성능 지표, 파이프라인의 실행 시간, 리소스 사용량 등을 꾸준히 측정하고 분석하여 병목 현상이나 개선점을 찾아내야 합니다. 이 데이터를 바탕으로 파이프라인을 최적화하고, 더 나은 모델을 개발하며, 궁극적으로는 비즈니스 목표 달성에 기여해야 합니다.
핵심 포인트
성공적인 MLOps는 기술 도입을 넘어, 조직의 문화와 프로세스를 ‘지속적인 개선’이라는 목표 아래 정렬하는 것입니다. 초기 단계부터 명확한 목표 설정과 유연한 접근 방식이 중요합니다.
참고 자료
더 깊이 있는 MLOps 탐구
MLOps는 방대한 분야인 만큼, 이 글에서 모든 것을 다룰 수는 없었습니다. 더 깊이 있는 학습을 원하시는 분들을 위해 몇 가지 참고 자료를 소개합니다.
참고 자료