

요약
Redis 시작 가이드 2026: 캐싱부터 실시간 데이터 처리까지 뚝딱!
Redis의 기본 개념부터 설치, 캐싱 및 실시간 데이터 처리 활용법을 쉽고 상세하게 알아봅니다.
핵심 키워드: 캐싱, 실시간 데이터, 인메모리
이 글의 순서
1. Redis, 왜 지금 주목받는가?
2. Redis의 주요 특징과 5가지 핵심 데이터 구조
3. Redis 설치 및 기본 명령어 마스터하기
4. Redis를 활용한 캐싱 전략 심층 분석
5. Redis로 실시간 데이터 처리 시스템 구축
6. Redis 운영 시 주의사항 및 최적화 팁
7. 자주 묻는 질문 (FAQ)
INTRO
Redis, 왜 지금 주목받는가?
안녕하세요, 권퓨터입니다! 2026년 현재, 빠르게 변화하는 IT 환경 속에서 데이터베이스의 역할은 그 어느 때보다 중요해졌습니다. 특히 실시간 데이터 처리와 고성능이 요구되는 현대 웹 서비스에서 Redis는 빼놓을 수 없는 핵심 기술로 자리매김했습니다. 하지만 Redis가 정확히 무엇이고, 어떻게 활용해야 하는지 막막하게 느끼는 분들도 많으실 겁니다. 이 글에서는 Redis의 기본 개념부터 실제 활용 사례까지, 초보자도 쉽게 이해할 수 있도록 자세히 설명해 드릴게요.
Redis는 ‘REmote DIctionary Server’의 약자로, 오픈소스 인메모리(In-Memory) 데이터 구조 스토어입니다. 이름에서 알 수 있듯이, 데이터를 디스크가 아닌 메인 메모리에 저장하여 매우 빠른 읽기/쓰기 성능을 제공하는 것이 특징이죠. 관계형 데이터베이스(RDB)나 전통적인 NoSQL 데이터베이스들이 디스크 I/O에 의존하는 것과 달리, Redis는 메모리에서 직접 데이터를 처리하기 때문에 밀리초 단위의 응답 시간을 기대할 수 있습니다.
“데이터 처리 속도가 곧 서비스 경쟁력! Redis는 이 경쟁에서 우위를 점하게 해주는 강력한 도구입니다.”
그렇다면 왜 이렇게 빠른 속도가 필요할까요? 넷플릭스, 트위치, 인스타그램과 같은 대규모 서비스들을 떠올려 보세요. 수많은 사용자가 동시에 접속하고, 실시간으로 콘텐츠를 스트리밍하거나 피드를 업데이트합니다. 이때 사용자 요청 하나하나를 디스크 기반 데이터베이스에서 처리한다면 엄청난 지연이 발생할 수밖에 없습니다. Redis는 이러한 고성능, 고가용성 요구사항을 충족시키기 위해 탄생했으며, 캐싱, 세션 관리, 실시간 랭킹, 메시지 큐 등 다양한 분야에서 핵심적인 역할을 수행하고 있습니다.
핵심 포인트
Redis는 인메모리 데이터 구조 스토어로, 디스크 I/O 없이 메모리에서 데이터를 처리하여 초고속 성능을 제공합니다. 이는 현대의 고성능 웹 서비스에 필수적인 요소입니다.
FEATURES
Redis의 주요 특징과 5가지 핵심 데이터 구조
Redis가 단순한 ‘빠른 저장소’를 넘어 강력한 도구로 평가받는 이유는 바로 다양한 데이터 구조를 지원하기 때문입니다. 일반적인 Key-Value 저장소와 달리, Redis는 개발자가 필요에 따라 적절한 데이터 구조를 선택하여 복잡한 로직을 효율적으로 구현할 수 있게 돕습니다. 지금부터 Redis의 5가지 핵심 데이터 구조와 각 구조의 특징, 그리고 활용 사례를 자세히 살펴보겠습니다.
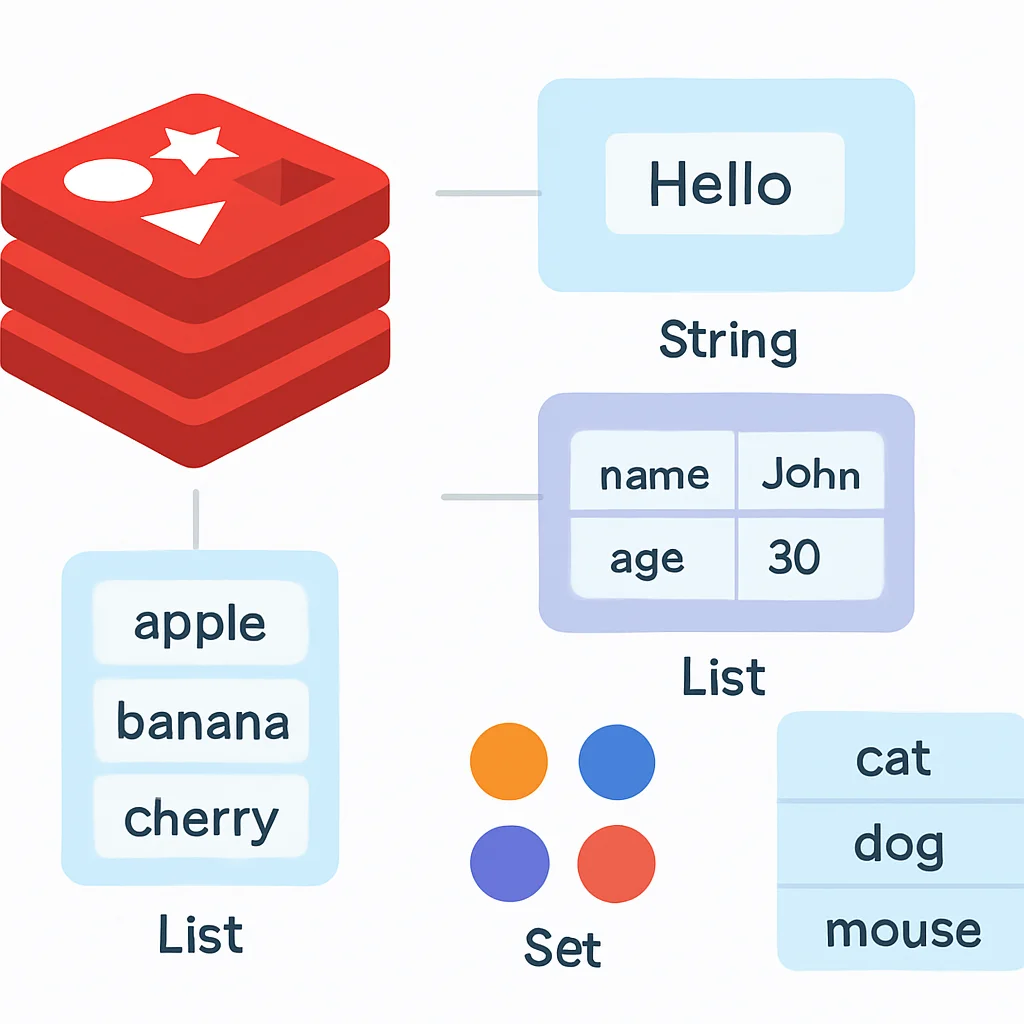
1. String (문자열)
Redis의 가장 기본적인 데이터 타입입니다. 텍스트, 이진 데이터, JPEG 이미지 등 모든 종류의 데이터를 저장할 수 있으며, 최대 512MB까지 저장 가능합니다. 카운터(Counter)나 세션 정보 저장에 주로 활용됩니다.
주요 String 명령어
SET key value — 키에 값을 저장합니다.
GET key — 키에 저장된 값을 가져옵니다.
INCR key — 키에 저장된 값을 1 증가시킵니다 (원자적 연산).
2. Hash (해시)
객체를 표현하기에 적합한 데이터 타입입니다. 하나의 키 안에 여러 개의 필드(field)와 값(value) 쌍을 저장할 수 있어, 사용자 프로필이나 제품 정보와 같이 여러 속성을 가진 데이터를 효율적으로 관리할 때 유용합니다.
주요 Hash 명령어
HSET key field value — 해시에 필드와 값을 저장합니다.
HGET key field — 해시에서 특정 필드의 값을 가져옵니다.
HGETALL key — 해시의 모든 필드와 값을 가져옵니다.
3. List (리스트)
삽입된 순서대로 정렬되는 문자열 컬렉션입니다. 양쪽 끝에서 데이터를 빠르게 추가하거나 제거할 수 있어(Linked List 구현), 메시지 큐, 최근 방문 기록, 알림 피드 등을 구현할 때 활용됩니다.
주요 List 명령어
LPUSH key value [value …] — 리스트의 왼쪽에 값을 추가합니다.
RPUSH key value [value …] — 리스트의 오른쪽에 값을 추가합니다.
LPOP key — 리스트의 왼쪽에서 값을 제거하고 반환합니다.
LRANGE key start stop — 리스트의 지정된 범위의 요소를 가져옵니다.
4. Set (셋)
정렬되지 않은 문자열 컬렉션으로, 중복된 멤버를 허용하지 않습니다. 유일한 값들의 집합을 저장하고 싶을 때 사용하며, 태그 시스템, 고유 방문자 수 계산, 친구 목록 등에 활용됩니다.
주요 Set 명령어
SADD key member [member …] — 셋에 멤버를 추가합니다.
SMEMBERS key — 셋의 모든 멤버를 가져옵니다.
SISMEMBER key member — 멤버가 셋에 존재하는지 확인합니다.
SINTER key1 [key2 …] — 여러 셋의 교집합을 구합니다.
5. Sorted Set (정렬된 셋)
셋과 유사하지만, 모든 멤버가 고유한 스코어(score)를 가지고 스코어에 따라 정렬됩니다. 랭킹 시스템, 우선순위 큐, 리더보드 등 정렬된 데이터가 필요한 곳에 이상적입니다.
주요 Sorted Set 명령어
ZADD key score member [score member …] — 정렬된 셋에 스코어와 멤버를 추가합니다.
ZRANGE key start stop [WITHSCORES] — 지정된 범위의 멤버를 스코어 순으로 가져옵니다.
ZSCORE key member — 멤버의 스코어를 가져옵니다.
이러한 다양한 데이터 구조 덕분에 Redis는 단순한 캐시 서버를 넘어, 복잡한 비즈니스 로직을 구현하는 데 필요한 강력한 빌딩 블록을 제공합니다. 개발자는 각 데이터의 특성에 맞춰 최적의 구조를 선택함으로써 성능과 효율성을 극대화할 수 있습니다.
INSTALLATION
Redis 설치 및 기본 명령어 마스터하기
Redis를 직접 설치하고 사용해보는 것은 그 개념을 이해하는 가장 좋은 방법입니다. 2026년 현재, Redis를 설치하는 가장 쉽고 권장되는 방법 중 하나는 Docker를 활용하는 것입니다. Docker는 컨테이너 기반 가상화 기술로, 복잡한 환경 설정 없이 Redis를 빠르게 구축하고 실행할 수 있게 해줍니다. 이 섹션에서는 Docker를 이용한 Redis 설치 방법과 redis-cli를 통한 기본 명령어 사용법을 알아보겠습니다.
Docker로 Redis 설치하기
먼저, 시스템에 Docker가 설치되어 있어야 합니다. Docker Desktop을 설치하면 Docker 엔진과 CLI 도구를 한 번에 사용할 수 있습니다. 설치가 완료되었다면, 터미널(또는 명령 프롬프트)을 열고 다음 명령어를 실행하여 Redis 컨테이너를 시작할 수 있습니다.
코드 설명
이 명령어는 Docker Hub에서 최신 Redis 이미지를 다운로드하고, my-redis-server라는 이름으로 컨테이너를 실행합니다. -p 6379:6379는 호스트의 6379 포트를 컨테이너의 6379 포트에 연결하여 외부에서 Redis에 접근할 수 있도록 합니다. --requirepass your_password는 Redis 서버에 접속할 때 필요한 비밀번호를 설정합니다. 실제 운영 환경에서는 반드시 강력한 비밀번호를 사용해야 합니다.
docker run --name my-redis-server -p 6379:6379 -d redis/redis-stack-server:latest --requirepass "your_strong_password_here"컨테이너가 성공적으로 실행되었는지 확인하려면 다음 명령어를 사용합니다.
docker psmy-redis-server 컨테이너가 ‘Up’ 상태로 보인다면 성공입니다!
redis-cli로 Redis와 상호작용하기
Redis 컨테이너가 실행 중이라면, redis-cli를 사용하여 Redis 서버에 접속하고 명령어를 실행할 수 있습니다. Docker 환경에서는 컨테이너 내부의 redis-cli를 사용하는 것이 가장 편리합니다.
코드 설명
이 명령어는 my-redis-server 컨테이너 내부로 접속하여 redis-cli를 실행합니다. 비밀번호가 설정되어 있다면 AUTH 명령어로 인증해야 합니다.
docker exec -it my-redis-server redis-cli
AUTH your_strong_password_here
PING
SET mykey "Hello, Redis!"
GET mykey
LPUSH mylist "item1" "item2" "item3"
LRANGE mylist 0 -1
HSET user:1 name "Kwonputer" email "[email protected]"
HGETALL user:1
QUIT위 명령어를 순서대로 실행해보면 Redis의 기본적인 String, List, Hash 데이터 구조에 데이터를 저장하고 조회하는 과정을 직접 경험할 수 있습니다. PING 명령어로 서버 연결 상태를 확인하고, QUIT으로 redis-cli를 종료할 수 있습니다.
CACHING
Redis를 활용한 캐싱 전략 심층 분석
Redis의 가장 대표적인 활용 사례는 바로 캐싱(Caching)입니다. 캐싱은 자주 접근하는 데이터를 임시로 저장하여 데이터베이스나 외부 API 호출 횟수를 줄여 서비스 응답 속도를 높이고 부하를 분산하는 기술입니다. Redis는 인메모리 특성상 매우 빠른 캐시 역할을 수행하며, 다양한 캐싱 전략을 지원하여 개발자가 효율적인 시스템을 구축할 수 있도록 돕습니다.
캐싱의 중요성과 Redis의 역할
웹 서비스에서 사용자의 요청이 들어오면 대부분 데이터베이스에서 데이터를 조회해야 합니다. 이 과정은 디스크 I/O를 포함하므로 상대적으로 느립니다. 만약 동일한 데이터를 수천, 수만 명의 사용자가 동시에 요청한다면 데이터베이스에 과부하가 걸려 서비스 지연이나 장애로 이어질 수 있습니다. 이때 Redis를 캐시로 사용하면, 한 번 조회된 데이터를 Redis에 저장해두고 다음 요청 시 데이터베이스 대신 Redis에서 바로 데이터를 가져와 응답 속도를 획기적으로 개선할 수 있습니다.
주요 캐싱 전략
Redis를 활용한 캐싱은 크게 세 가지 전략으로 나눌 수 있습니다.
1. Cache-Aside (Look-Aside Cache)
애플리케이션이 캐시를 먼저 확인하고, 데이터가 없으면 데이터베이스에서 가져와 캐시에 저장한 후 반환하는 방식입니다. 가장 흔하게 사용되는 전략입니다.
2. Write-Through Cache
데이터를 업데이트할 때, 캐시와 데이터베이스에 동시에 기록하는 방식입니다. 캐시와 데이터베이스의 일관성을 유지하기 쉽습니다.
3. Write-Back Cache
데이터를 업데이트할 때, 먼저 캐시에만 기록하고 일정 시간 후 또는 특정 조건이 충족될 때 데이터베이스에 기록하는 방식입니다. 쓰기 성능이 매우 빠르지만, 데이터 유실 위험이 있습니다.
Python을 이용한 Cache-Aside 구현 예시
가장 일반적인 Cache-Aside 전략을 Python redis-py 라이브러리를 사용하여 구현하는 예시입니다. 여기서는 TTL (Time To Live)을 설정하여 캐시 데이터의 만료 시간을 지정하는 것이 중요합니다.
코드 설명
이 Python 코드는 Redis를 캐시로 사용하여 사용자 데이터를 조회하는 함수를 보여줍니다. get_user_data 함수는 먼저 Redis에서 데이터를 찾고, 없으면 get_user_from_db (가상의 데이터베이스 함수)에서 가져와 Redis에 EX (만료 시간)와 함께 저장합니다. 이렇게 하면 동일한 요청이 다시 들어올 때 데이터베이스에 접근하지 않고 Redis에서 빠르게 응답할 수 있습니다.
import redis
import json
import time
# Redis 클라이언트 연결 (Docker 컨테이너 비밀번호와 동일하게 설정)
r = redis.Redis(host='localhost', port=6379, password='your_strong_password_here', decode_responses=True)
# 가상의 데이터베이스 조회 함수
def get_user_from_db(user_id):
print(f"데이터베이스에서 user:{user_id} 조회 중...")
time.sleep(1) # DB 조회 지연 시뮬레이션
return {"id": user_id, "name": f"User {user_id}", "email": f"user{user_id}@example.com"}
# Cache-Aside 전략 구현 함수
def get_user_data(user_id):
cache_key = f"user:{user_id}"
# 1. 캐시에서 데이터 조회
cached_data = r.get(cache_key)
if cached_data:
print(f"캐시에서 user:{user_id} 데이터 가져옴.")
return json.loads(cached_data)
# 2. 캐시에 데이터가 없으면 데이터베이스에서 조회
user_data = get_user_from_db(user_id)
# 3. 데이터베이스에서 가져온 데이터를 캐시에 저장 (TTL 60초)
r.setex(cache_key, 60, json.dumps(user_data))
print(f"데이터베이스에서 user:{user_id} 데이터 가져와 캐시에 저장.")
return user_data
if __name__ == "__main__":
print("--- 첫 번째 조회 (DB에서 가져옴) ---")
user_1_data = get_user_data(1)
print(f"User 1 데이터: {user_1_data}")
print("\n--- 두 번째 조회 (캐시에서 가져옴) ---")
user_1_data_cached = get_user_data(1)
print(f"User 1 데이터 (캐시): {user_1_data_cached}")
print("\n--- 새로운 사용자 조회 (DB에서 가져옴) ---")
user_2_data = get_user_data(2)
print(f"User 2 데이터: {user_2_data}")
print("\n--- 캐시 만료 대기 (60초 후 재조회 시 DB 접근) ---")
# time.sleep(65) # 실제 테스트 시 주석 해제
# user_1_data_expired = get_user_data(1)
# print(f"User 1 데이터 (만료 후): {user_1_data_expired}")핵심 포인트
캐싱은 Redis의 가장 강력한 기능 중 하나입니다. Cache-Aside, Write-Through, Write-Back 등 다양한 전략을 이해하고, 데이터의 특성과 서비스 요구사항에 맞춰 적절한 캐싱 전략을 선택하는 것이 중요합니다. TTL 설정으로 캐시의 유효성을 관리하는 것도 필수적입니다.
REALTIME
Redis로 실시간 데이터 처리 시스템 구축
Redis는 단순한 캐시 서버를 넘어, 실시간 데이터 처리를 위한 강력한 도구로도 활용됩니다. 특히 Pub/Sub (Publish/Subscribe) 메시징 패턴과 Redis Stream은 실시간 채팅, 알림 서비스, 이벤트 스트리밍 등 다양한 실시간 시스템을 구축하는 데 필수적인 기능을 제공합니다.
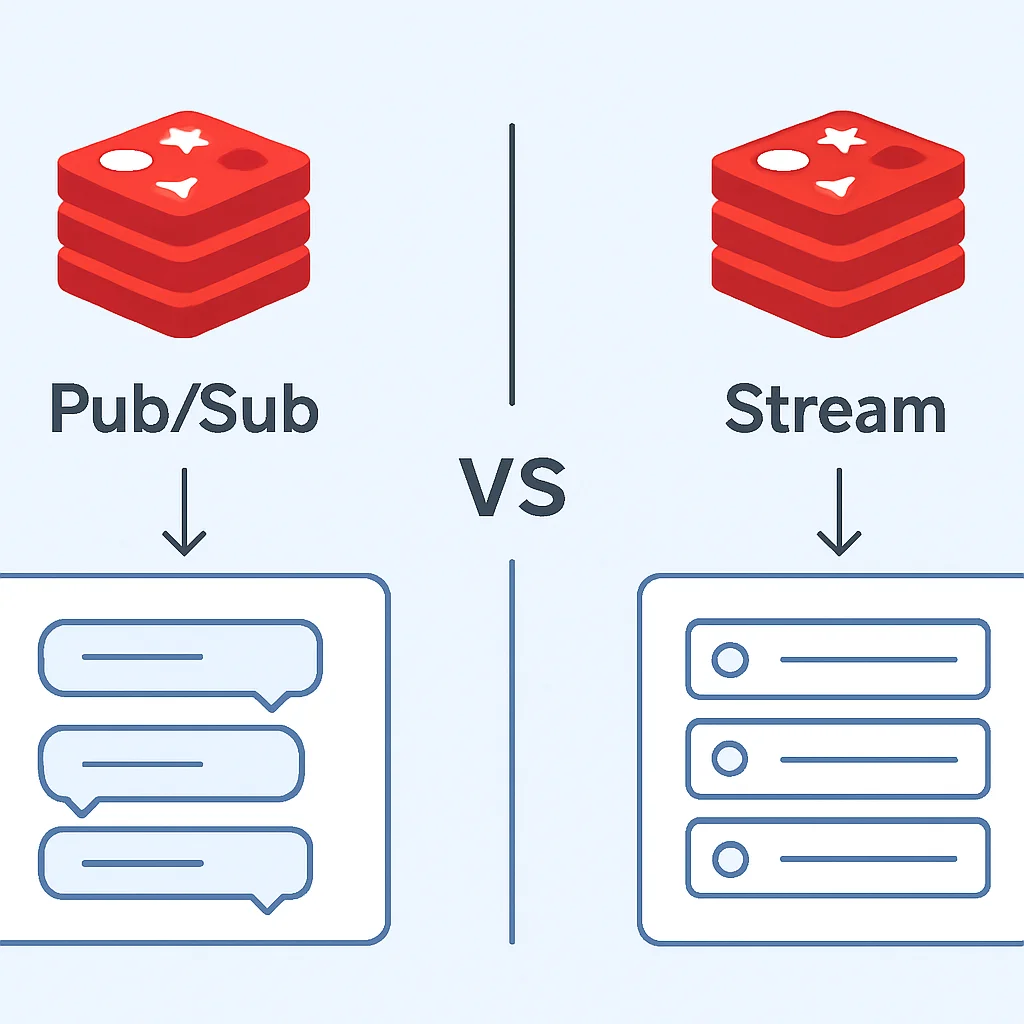
Pub/Sub (발행/구독) 모델
Redis Pub/Sub은 메시지를 발행하는 Publisher와 메시지를 수신하는 Subscriber로 구성됩니다. Publisher가 특정 채널에 메시지를 발행하면, 해당 채널을 구독하고 있는 모든 Subscriber가 메시지를 실시간으로 수신합니다. 이는 실시간 채팅방, 알림 시스템, 주식 시세 업데이트 등 다양한 분야에서 활용될 수 있습니다.
코드 설명
아래 코드는 Python으로 Redis Pub/Sub 시스템을 구현한 예시입니다. publisher.py는 chat_channel에 메시지를 발행하고, subscriber.py는 해당 채널을 구독하여 메시지를 수신합니다. 두 스크립트를 동시에 실행하면 실시간 메시지 전달을 확인할 수 있습니다.
# publisher.py
import redis
import time
r = redis.Redis(host='localhost', port=6379, password='your_strong_password_here', decode_responses=True)
channel = "chat_channel"
print("Publisher 시작. 메시지 발행 중...")
for i in range(5):
message = f"안녕하세요! {i+1}번째 메시지입니다."
r.publish(channel, message)
print(f"'{channel}' 채널에 메시지 발행: {message}")
time.sleep(1)
print("Publisher 종료.")
# subscriber.py
import redis
r = redis.Redis(host='localhost', port=6379, password='your_strong_password_here', decode_responses=True)
p = r.pubsub()
channel = "chat_channel"
p.subscribe(channel)
print(f"Subscriber 시작. '{channel}' 채널 구독 중...")
try:
for message in p.listen():
if message['type'] == 'message':
print(f"'{channel}' 채널에서 메시지 수신: {message['data']}")
except KeyboardInterrupt:
print("Subscriber 종료.")
p.unsubscribe(channel)
p.close()Redis Stream을 이용한 안정적인 메시지 처리
Pub/Sub은 실시간성이 좋지만, 메시지 유실에 대한 보장이 없습니다. Subscriber가 연결되어 있지 않은 동안 발행된 메시지는 수신할 수 없습니다. 이러한 문제를 해결하기 위해 Redis 5.0부터 도입된 것이 바로 Redis Stream입니다. Stream은 Kafka와 유사하게 메시지를 영속적으로 저장하고, Consumer Group을 통해 여러 Consumer가 메시지를 분산 처리할 수 있도록 지원하여 더욱 안정적인 메시지 큐 기능을 제공합니다.
문제 01
Pub/Sub 메시지 유실 문제
Pub/Sub 모델에서는 Subscriber가 오프라인일 때 발행된 메시지는 영구적으로 유실됩니다. 메시지 처리의 안정성이 중요한 시스템에는 적합하지 않습니다.
해결 — Redis Stream으로 메시지 영속성 및 분산 처리
Redis Stream은 모든 메시지를 영구적으로 저장하여 유실을 방지합니다. 또한, Consumer Group을 통해 여러 Consumer가 동일한 Stream의 메시지를 분산 처리하고, 각 Consumer가 어디까지 처리했는지(Offset)를 Redis가 관리하여 안정적인 메시지 처리를 보장합니다.
# Redis Stream 기본 명령어 예시
# 메시지 추가
XADD my_stream * event_type "user_login" user_id "123" timestamp "1678886400"
# 특정 Stream에서 메시지 읽기
XRANGE my_stream - + COUNT 10
# Consumer Group 생성
XGROUP CREATE my_stream my_group 0-0 MKSTREAM
# Consumer Group의 Consumer로 메시지 읽기
XREADGROUP GROUP my_group my_consumer COUNT 1 STREAMS my_stream >
# 메시지 처리 후 ACK (승인)
XACK my_stream my_group message_id핵심 포인트
Redis는 Pub/Sub을 통해 실시간 메시징 기능을 제공하며, Redis Stream을 통해 메시지 유실 없이 안정적으로 이벤트를 처리하고 Consumer Group으로 분산 처리까지 가능합니다. 이는 실시간 채팅, 알림, 이벤트 스트리밍 등 다양한 실시간 시스템 구축에 필수적인 기능입니다.
OPERATIONS
Redis 운영 시 주의사항 및 최적화 팁
Redis는 강력한 성능을 제공하지만, 효율적이고 안정적으로 운영하기 위해서는 몇 가지 주의사항과 최적화 팁을 알아두는 것이 좋습니다. 특히 인메모리 특성상 메모리 관리, 데이터 영속성, 그리고 고가용성(High Availability) 확보는 Redis 운영의 핵심입니다.
1. 메모리 관리
Redis는 모든 데이터를 메모리에 저장하므로, 물리적 메모리 용량을 초과하지 않도록 주의해야 합니다. 메모리가 부족하면 Redis 성능 저하, 심지어 서비스 장애로 이어질 수 있습니다. maxmemory 설정을 통해 Redis가 사용할 수 있는 최대 메모리를 제한하고, maxmemory-policy를 통해 메모리 한계 도달 시 어떤 데이터를 제거할지(예: LRU, LFU) 지정해야 합니다.
주의사항
Redis 서버의 메모리 사용량을 지속적으로 모니터링해야 합니다. INFO memory 명령어를 통해 현재 메모리 사용량을 확인할 수 있습니다. 시스템의 전체 메모리 중 Redis에 할당하는 비율을 적절히 조절하고, OOM(Out Of Memory) 상황을 방지해야 합니다.
2. 데이터 영속성 (Persistence)
Redis는 기본적으로 인메모리 데이터베이스이지만, 데이터 유실을 방지하기 위한 영속성(Persistence) 옵션을 제공합니다. 주요 방법은 두 가지입니다.
RDB (Redis Database Backup)
특정 시점의 스냅샷을 바이너리 파일(dump.rdb)로 디스크에 저장합니다. 데이터 복구가 빠르지만, 스냅샷 간의 데이터는 유실될 수 있습니다.
AOF (Append Only File)
Redis에 실행되는 모든 쓰기 명령어를 로그 파일(appendonly.aof)로 기록합니다. RDB보다 데이터 유실 가능성이 적지만, 파일 크기가 커질 수 있고 복구 시간이 더 걸릴 수 있습니다.
일반적으로 두 가지 방법을 함께 사용하여 데이터 유실을 최소화하는 하이브리드 전략을 권장합니다.
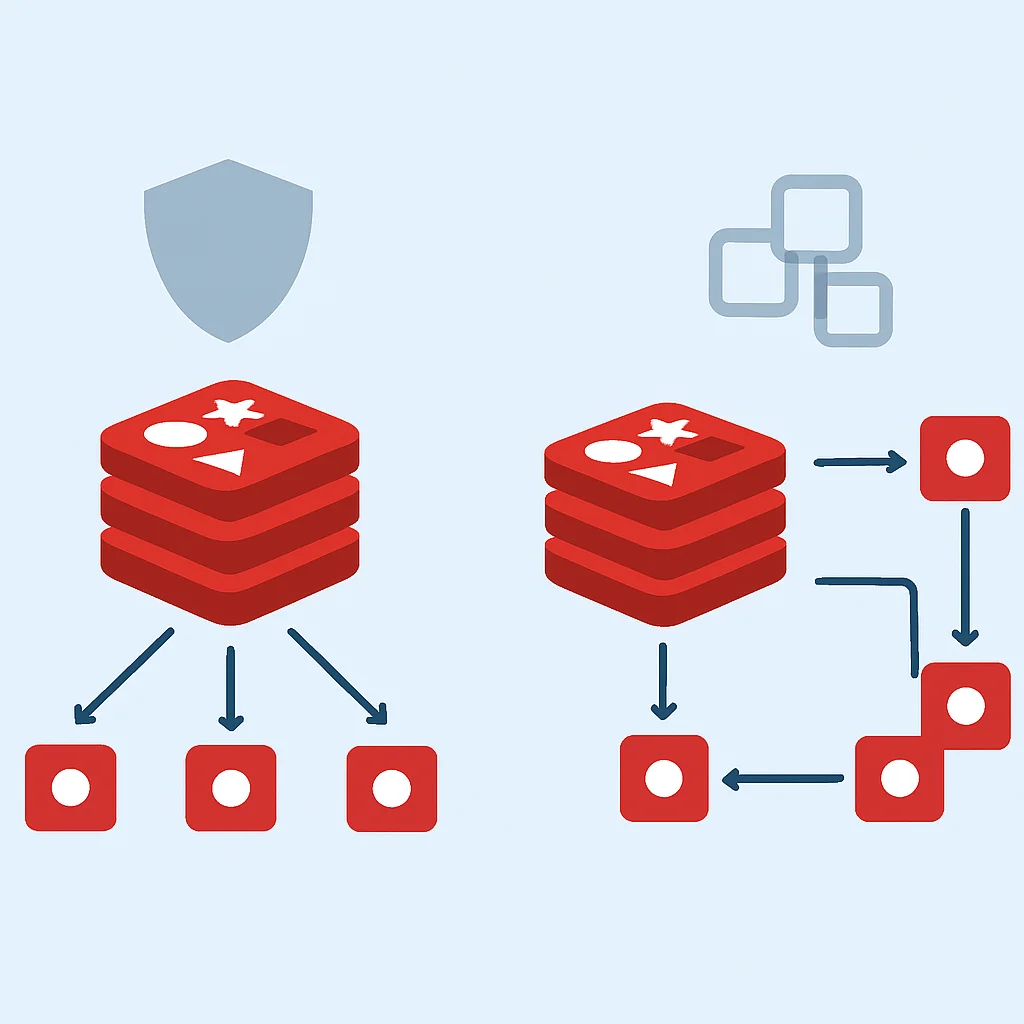
3. 고가용성 (High Availability) 및 확장성 (Scalability)
단일 Redis 인스턴스는 단일 장애점(Single Point of Failure)이 될 수 있습니다. 서비스 중단 없이 Redis를 운영하기 위해서는 고가용성과 확장성을 고려해야 합니다.
Redis Sentinel
Redis 서버의 상태를 모니터링하고, 마스터 서버에 장애가 발생하면 자동으로 슬레이브 서버 중 하나를 새로운 마스터로 승격시키는 기능을 제공합니다. 고가용성 확보에 필수적입니다.
Redis Cluster
데이터를 여러 Redis 인스턴스에 분산 저장(샤딩)하고, 각 인스턴스의 고가용성을 보장합니다. 대규모 데이터를 처리하고 높은 처리량을 요구하는 환경에서 사용됩니다.
핵심 포인트
Redis 운영 시 메모리 관리(maxmemory), 데이터 유실 방지를 위한 영속성 설정(RDB, AOF), 그리고 서비스 중단 없는 운영을 위한 고가용성(Sentinel, Cluster) 확보는 필수적입니다. 주기적인 모니터링과 백업 전략을 수립하여 안정적인 서비스를 유지해야 합니다.
자주 묻는 질문 (FAQ)
Q. Redis는 왜 이렇게 빠른가요?
Redis는 데이터를 디스크가 아닌 메인 메모리에 저장하고 처리하기 때문에 디스크 I/O에 대한 지연 없이 초고속으로 데이터를 읽고 쓸 수 있습니다. 또한, C언어로 구현되어 있고, 단일 스레드로 동작하여 컨텍스트 스위칭 오버헤드를 줄이는 등 효율적인 아키텍처를 가지고 있습니다.
Q. Redis는 관계형 데이터베이스(RDB)를 완전히 대체할 수 있나요?
아니요, Redis는 관계형 데이터베이스를 완전히 대체하기보다는 보완하는 역할을 합니다. Redis는 빠른 속도와 다양한 데이터 구조를 제공하지만, 복잡한 쿼리, 트랜잭션의 ACID 보장, 대규모 데이터의 영구 저장 등은 관계형 데이터베이스가 여전히 강점을 가집니다. 일반적으로 Redis는 캐싱, 세션 관리, 실시간 랭킹 등 특정 고성능 요구사항에 사용되고, 중요하고 영구적인 데이터는 RDB에 저장하는 하이브리드 방식으로 많이 사용됩니다.
Q. Redis 데이터는 서버가 다운되면 모두 사라지나요?
기본적으로 메모리 기반이므로 서버가 다운되면 데이터가 유실될 위험이 있습니다. 하지만 Redis는 RDB (스냅샷)와 AOF (명령어 로그)라는 두 가지 영속성 옵션을 제공하여 데이터를 디스크에 저장할 수 있습니다. 이 기능을 설정하면 서버 재시작 시 저장된 데이터를 복구할 수 있습니다.
Q. Redis를 사용하면 어떤 장점이 있나요?
Redis의 주요 장점은 초고속 데이터 처리 속도, 다양한 데이터 구조 지원, 높은 확장성 및 가용성, 그리고 Pub/Sub 및 Stream을 통한 실시간 데이터 처리 기능입니다. 이를 통해 서비스 응답 속도를 향상시키고, 데이터베이스 부하를 줄이며, 복잡한 실시간 기능을 효율적으로 구현할 수 있습니다.
긴 글을 읽어주셔서 감사합니다!
지금까지 Redis의 기본 개념부터 설치, 주요 데이터 구조, 캐싱 전략, 실시간 데이터 처리, 그리고 운영 시 주의사항까지 폭넓게 다루어 보았습니다.
Redis는 2026년에도 빠르게 진화하는 IT 환경에서 여러분의 서비스를 한 단계 더 발전시킬 수 있는 강력한 무기입니다. 이 가이드가 Redis를 이해하고 실제 프로젝트에 적용하는 데 도움이 되기를 바랍니다.
궁금한 점이 있으면 언제든지 댓글로 남겨주세요!