

2026년 나만의 LLM 파인튜닝 가이드
Hugging Face Transformers와 LoRA 기법으로 적은 비용으로 고성능 대규모 언어 모델을 만드는 실전 가이드입니다.
핵심 키워드: Hugging Face, LoRA, LLM 파인튜닝
이 글의 순서
1. 나만의 LLM, 왜 지금 필요한가?
2. LLM 파인튜닝의 핵심: Hugging Face Transformers
3. LoRA: 적은 비용으로 똑똑하게 파인튜닝하는 비법
4. 데이터 준비부터 학습까지: 실전 파인튜닝 워크플로우
5. 흔히 겪는 문제와 해결 팁
6. FAQ: LLM 파인튜닝 궁금증 해소
7. 나만의 AI, 미래를 디자인하다
배경/도입
나만의 LLM, 왜 지금 필요한가?
2026년, 대규모 언어 모델(LLM)은 이미 우리 일상과 비즈니스에 깊숙이 스며들었습니다. ChatGPT, Gemini, Claude와 같은 모델들은 놀라운 성능으로 전 세계를 놀라게 했죠. 하지만 이 강력한 범용 LLM들도 특정 분야에서는 한계를 드러내곤 합니다. 예를 들어, 특정 기업의 내부 문서 분석, 아주 전문적인 의학/법률 자문, 혹은 개인화된 취향을 반영하는 창작 활동 등에서는 일반적인 LLM이 기대만큼의 정확도나 깊이를 제공하지 못할 수 있습니다.
바로 이 지점에서 ‘나만의 LLM 파인튜닝’의 중요성이 부각됩니다. 파인튜닝(Fine-tuning)이란 이미 학습된 거대한 LLM을 특정 데이터셋에 맞춰 추가 학습시키는 과정을 의미합니다. 마치 잘 훈련된 운동선수가 특정 종목에서 더 좋은 성적을 내기 위해 맞춤 훈련을 받는 것과 같죠. 이를 통해 범용 LLM을 특정 도메인에 특화시키거나, 특정 스타일로 대화하게 하거나, 특정 작업을 더 잘 수행하도록 만들 수 있습니다.
과거에는 LLM 파인튜닝이 방대한 컴퓨팅 자원과 전문 지식을 요구하는 고난이도 작업이었습니다. 하지만 2026년 현재는 Hugging Face와 같은 오픈소스 생태계의 발전, 그리고 LoRA(Low-Rank Adaptation)와 같은 효율적인 파인튜닝 기법의 등장으로 인해, 개인 개발자나 중소기업도 합리적인 비용과 노력으로 자신만의 똑똑한 LLM을 구축할 수 있는 시대가 열렸습니다. 이 글에서는 이러한 기술들을 활용하여 나만의 LLM을 만드는 실전 가이드를 제공하고자 합니다. 이제 더 이상 범용 AI에만 의존하지 않고, 여러분의 필요에 꼭 맞는 AI를 직접 만들어 보세요!
핵심 포인트
범용 LLM의 한계를 극복하고 특정 도메인이나 개인화된 요구사항에 최적화된 AI를 만들기 위해 파인튜닝은 2026년 필수적인 기술이 되었습니다.
핵심 내용 1
LLM 파인튜닝의 핵심: Hugging Face Transformers
Hugging Face는 현재 LLM 개발 및 연구 분야에서 사실상의 표준으로 자리매김한 플랫폼입니다. 특히 Transformers 라이브러리는 수많은 사전 학습된 모델(Pre-trained Models)과 이를 손쉽게 활용할 수 있는 도구들을 제공하여, 개발자들이 복잡한 딥러닝 프레임워크의 내부 구현에 얽매이지 않고도 AI 모델을 구축하고 파인튜닝할 수 있도록 돕습니다.
Hugging Face Transformers의 역할과 장점
Hugging Face Transformers는 BERT, GPT, T5, Llama 등 다양한 LLM 아키텍처를 PyTorch, TensorFlow, JAX와 같은 딥러닝 프레임워크 위에서 일관된 API로 사용할 수 있게 해줍니다. 주요 장점은 다음과 같습니다:
✓ 광범위한 모델 지원: 수천 개의 사전 학습된 모델이 Hugging Face Hub에 공개되어 있어, 원하는 모델을 쉽게 찾아 사용할 수 있습니다.
✓ 표준화된 인터페이스: 모델 로드, 토크나이징, 추론 등 모든 과정이 통일된 방식으로 이루어져 학습 곡선을 낮춥니다.
✓ 활발한 커뮤니티와 생태계: 문제 발생 시 해결책을 찾기 쉽고, 새로운 기능이나 모델이 빠르게 공유됩니다. datasets, accelerate, peft 등 관련 라이브러리도 풍부합니다.
이러한 장점 덕분에 Hugging Face Transformers는 2026년 현재 LLM 파인튜닝을 위한 가장 강력하고 접근성 높은 도구라고 할 수 있습니다.
주요 구성 요소: AutoModel, AutoTokenizer, Pipeline
Transformers 라이브러리를 사용할 때 가장 많이 접하게 될 세 가지 핵심 클래스입니다.
● AutoModelForCausalLM: 텍스트 생성(Causal Language Modeling)을 위한 모델을 자동으로 로드합니다. 모델 이름만 지정하면 해당 모델의 아키텍처에 맞는 클래스를 찾아줍니다.
● AutoTokenizer: 모델에 맞는 토크나이저를 자동으로 로드합니다. 텍스트를 모델이 이해할 수 있는 숫자 토큰 시퀀스로 변환하는 역할을 합니다.
● pipeline: 모델과 토크나이저를 한데 묶어 특정 태스크(텍스트 생성, 번역, 요약 등)를 쉽게 수행할 수 있도록 추상화된 고수준 API입니다. 간단한 추론에 유용합니다.
코드 설명
다음 코드는 Hugging Face Transformers를 사용하여 GPT-2 모델과 토크나이저를 로드하고, 간단한 텍스트 생성 파이프라인을 구축하는 예시입니다.
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
# 1. 모델과 토크나이저 로드
# 예시로 GPT-2를 사용합니다. 실제 LLM 파인튜닝 시에는 더 큰 모델을 사용합니다.
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 2. 텍스트 생성 파이프라인 구축
# device=-1은 CPU 사용, device=0은 첫 번째 GPU 사용을 의미합니다.
generator = pipeline("text-generation", model=model, tokenizer=tokenizer, device=-1)
# 3. 텍스트 생성 예시
prompt = "권퓨터는 인공지능 기술에 대해"
result = generator(prompt, max_length=50, num_return_sequences=1)
print(result[0]['generated_text'])
# 출력 예시:
# 권퓨터는 인공지능 기술에 대해 더 많은 지식을 습득하고 싶어합니다.
# 그는 인공지능 기술을 활용하여 사람들의 삶을 더 편리하고 풍요롭게 만들고 싶어합니다.
핵심 포인트
Hugging Face Transformers는 LLM을 쉽게 다룰 수 있게 해주는 강력한 추상화 계층을 제공하며, AutoModel과 AutoTokenizer는 그 핵심입니다.

[그림 1] Hugging Face Transformers는 LLM 개발의 핵심 허브 역할을 합니다.
핵심 내용 2
LoRA: 적은 비용으로 똑똑하게 파인튜닝하는 비법
아무리 Hugging Face가 편리하다고 해도, 수십억 개의 파라미터를 가진 LLM을 통째로 파인튜닝(Full Fine-tuning)하는 것은 여전히 엄청난 컴퓨팅 자원을 요구합니다. 예를 들어, 7B(70억) 파라미터 모델을 16비트 정밀도로 파인튜닝하려면 최소 14GB의 VRAM이 필요하며, 옵티마이저 상태 등 추가 메모리까지 고려하면 30GB 이상의 VRAM이 필요할 수 있습니다. 이는 일반적인 GPU 환경에서는 감당하기 어렵습니다.
LoRA의 등장: 파인튜닝의 게임 체인저
이러한 문제를 해결하기 위해 등장한 것이 바로 LoRA(Low-Rank Adaptation)입니다. LoRA는 Parameter-Efficient Fine-Tuning (PEFT) 기법 중 하나로, 전체 모델의 모든 파라미터를 업데이트하는 대신, 모델의 특정 계층(주로 어텐션 메커니즘의 선형 계층)에 작은 “어댑터” 모듈을 추가하여 학습시키는 방식입니다. 이 어댑터 모듈은 원본 모델의 가중치 행렬에 저랭크(Low-Rank) 행렬을 더하는 방식으로 작동합니다.
LoRA 작동 원리
기존의 가중치 행렬 W가 있다고 가정해 봅시다. LoRA는 이 W를 직접 수정하는 대신, 두 개의 작은 행렬 A와 B를 도입합니다. 이 두 행렬은 W와 동일한 차원을 가지는 ΔW를 만들고, W' = W + ΔW = W + BA 형태로 결합됩니다. 여기서 A와 B는 훨씬 적은 수의 파라미터를 가집니다. 학습 중에는 오직 A와 B만 업데이트되고, 원본 가중치 W는 고정됩니다. 이를 통해 학습 가능한 파라미터 수를 극적으로 줄일 수 있습니다.
LoRA의 장점
✓ 메모리 효율성: 학습 가능한 파라미터가 적으므로 GPU 메모리 사용량이 현저히 줄어듭니다. 예를 들어, 7B 모델을 LoRA로 파인튜닝하면 Full Fine-tuning 대비 1/10 수준의 VRAM만으로도 가능합니다.
✓ 빠른 학습 속도: 업데이트할 파라미터 수가 적어 학습 속도가 빨라집니다. 동일한 데이터셋으로 Full Fine-tuning에 10시간이 걸린다면, LoRA는 1~2시간 만에 완료될 수 있습니다.
✓ 성능 유지: 놀랍게도 LoRA는 적은 수의 파라미터만 학습함에도 불구하고 Full Fine-tuning에 준하는 성능을 달성하는 경우가 많습니다.
✓ 모델 저장 및 교환 용이: 학습된 LoRA 어댑터는 원본 모델에 비해 매우 작습니다(수 MB 수준). 이 어댑터만 따로 저장하고 다른 원본 모델에 쉽게 적용하거나 교환할 수 있어 효율적인 모델 관리가 가능합니다.
코드 설명
Hugging Face의 peft 라이브러리를 사용하여 LoRA 설정을 정의하고 모델에 적용하는 기본적인 코드 예시입니다. r, lora_alpha, target_modules가 핵심 파라미터입니다.
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model, TaskType
# 1. 원본 모델 로드 (예시: llama-2-7b-hf)
# 실제 사용 시에는 Hugging Face Hub에서 접근 가능한 모델 이름을 사용하세요.
# quantization_config를 사용하여 모델을 4비트로 양자화하여 메모리 사용량을 더욱 줄일 수 있습니다.
# from transformers import BitsAndBytesConfig
# bnb_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16)
# model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=bnb_config, device_map="auto")
model_name = "EleutherAI/gpt-neo-125M" # 예시를 위해 작은 모델 사용
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 2. LoRA 설정 정의
# r: LoRA 랭크 (작을수록 파라미터 감소, 클수록 표현력 증가)
# lora_alpha: LoRA 스케일링 팩터 (r에 비례하여 조정)
# target_modules: LoRA를 적용할 모델의 레이어 이름. 일반적으로 attention 쿼리/값 레이어에 적용.
# lora_dropout: LoRA 모듈에 적용할 드롭아웃 비율
# bias: LoRA 바이어스 학습 여부
# task_type: 수행할 태스크 타입 (여기서는 텍스트 생성)
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], # Llama2 기준 예시, 모델마다 다를 수 있음
lora_dropout=0.05,
bias="none",
task_type=TaskType.CAUSAL_LM
)
# 3. LoRA 모델로 변환
# 원본 모델의 가중치는 고정되고, LoRA 어댑터만 학습됩니다.
peft_model = get_peft_model(model, lora_config)
# 학습 가능한 파라미터 수 확인 (원본 모델 대비 극적으로 감소)
peft_model.print_trainable_parameters()
# 출력 예시:
# trainable params: 196608 || all params: 125307392 || trainable%: 0.1568994060875902
# 전체 파라미터 중 0.15%만 학습 가능!
핵심 포인트
LoRA는 대규모 LLM 파인튜닝 시 발생하는 메모리 및 계산 비용 문제를 획기적으로 해결하는 PEFT 기법으로, 적은 리소스로도 고성능 파인튜닝을 가능하게 합니다.
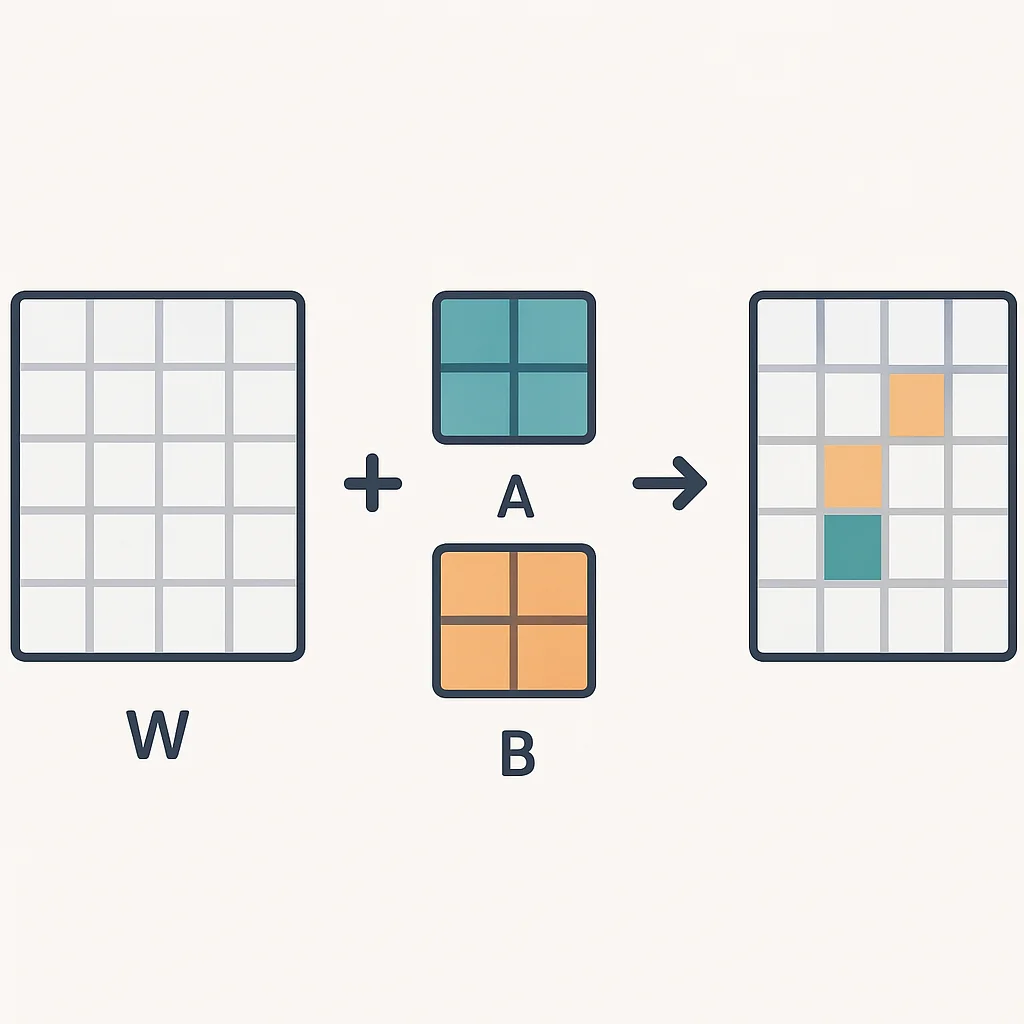
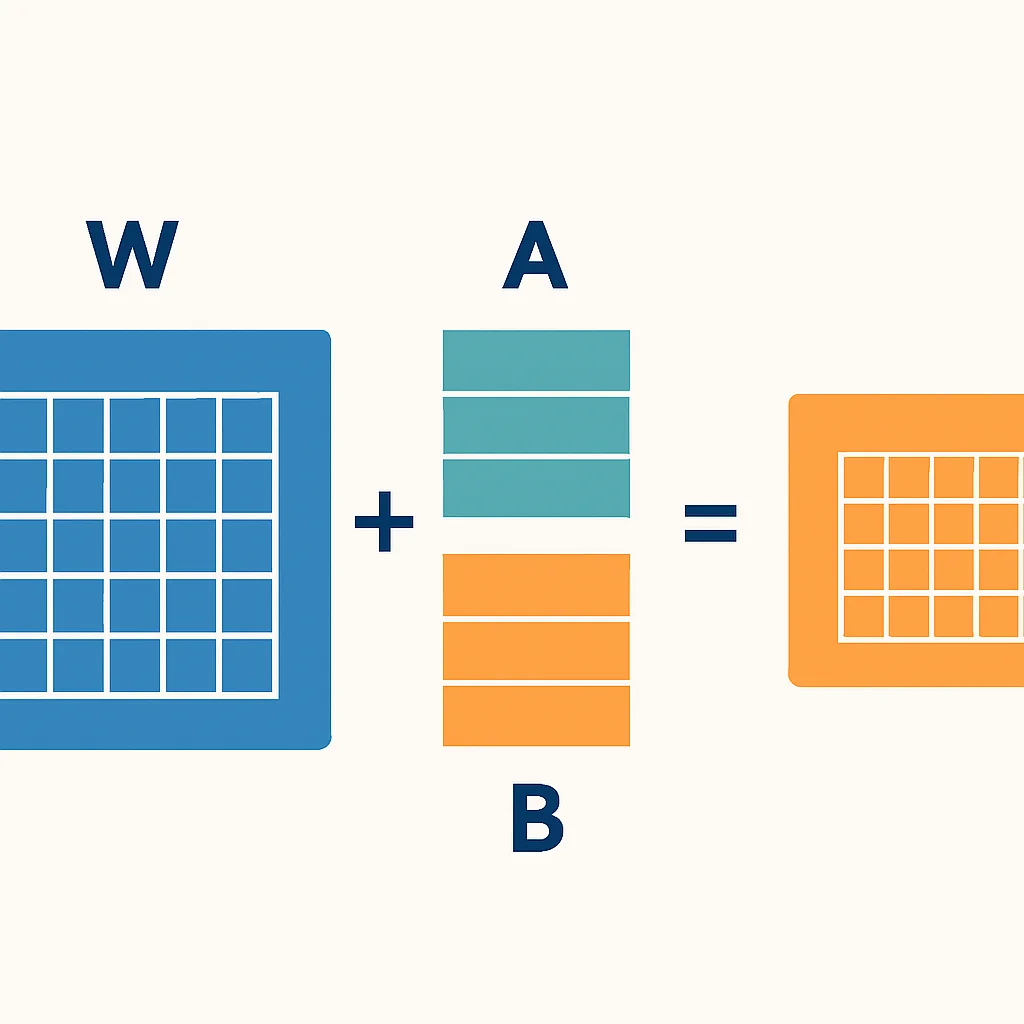
[그림 2] LoRA는 원본 가중치를 고정하고 작은 저랭크 행렬만 학습하여 효율성을 극대화합니다.
실전 적용
데이터 준비부터 학습까지: 실전 파인튜닝 워크플로우
이제 이론을 넘어 실제로 LLM을 파인튜닝하는 과정을 단계별로 살펴보겠습니다. 성공적인 파인튜닝의 8할은 데이터 준비에 달려있다는 것을 명심하세요!
1단계: 고품질 데이터셋 준비 및 전처리
파인튜닝의 성패를 좌우하는 가장 중요한 요소는 학습 데이터의 품질과 양입니다. 여러분의 LLM이 어떤 작업을 수행하길 원하는지에 따라 데이터셋을 구성해야 합니다.
● 데이터 형식: 일반적으로 JSONL(JSON Lines) 또는 CSV 형식을 많이 사용합니다. 각 라인이나 행이 하나의 학습 샘플을 구성합니다.
● 프롬프트-응답 쌍: LLM의 텍스트 생성 능력을 파인튜닝하기 위해서는 “프롬프트(질문)”와 “응답(정답)” 쌍으로 데이터를 구성하는 것이 효과적입니다. 예를 들어, {"prompt": "우리 회사 인사규정에 대해 알려줘", "completion": "우리 회사 인사규정은 다음과 같습니다..."}와 같은 형태입니다.
● 데이터 양: 최소 수백 개에서 수천 개의 고품질 샘플이 필요합니다. 양이 많을수록 좋지만, 품질이 우선입니다. 오염된 데이터는 모델 성능을 저하시킵니다.
● 데이터 전처리:
- 토크나이징: Hugging Face
AutoTokenizer를 사용하여 텍스트를 토큰 ID로 변환합니다. 이때max_length와padding,truncation설정을 적절히 해야 합니다. - 레이블 마스킹: 텍스트 생성 태스크의 경우, 프롬프트 부분은 손실(loss) 계산에서 제외하고 응답 부분만 학습하도록 레이블을 마스킹하는 것이 일반적입니다.
코드 설명
데이터셋을 로드하고 토크나이징하는 예시입니다. datasets 라이브러리를 활용하면 매우 편리합니다.
import torch
from datasets import Dataset
from transformers import AutoTokenizer
# 1. 예시 데이터셋 생성 (실제로는 JSONL 파일 등에서 로드)
data = [
{"instruction": "다음 문장을 긍정적으로 바꿔줘:", "input": "나는 오늘 기분이 좋지 않아.", "output": "나는 오늘 기분이 아주 좋아!"},
{"instruction": "다음 문장을 긍정적으로 바꿔줘:", "input": "이 영화는 정말 지루했어.", "output": "이 영화는 정말 흥미진진했어!"},
{"instruction": "다음 문장을 긍정적으로 바꿔줘:", "input": "내일 시험이 걱정돼.", "output": "내일 시험이 기대돼!"}
]
# Hugging Face Dataset 형식으로 변환
dataset = Dataset.from_list(data)
# 2. 토크나이저 로드 (학습할 모델과 동일한 토크나이저 사용)
model_name = "EleutherAI/gpt-neo-125M" # LoRA 예시와 동일한 모델 사용
tokenizer = AutoTokenizer.from_pretrained(model_name)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token # 패딩 토큰이 없는 경우 EOS 토큰 사용
# 3. 데이터 전처리 함수 정의
def preprocess_function(examples):
# 각 샘플을 '프롬프트 + 응답' 형식으로 결합
# LLM이 특정 포맷을 따르도록 Instruction-Tuning 포맷을 사용할 수 있습니다.
# 예: "### Instruction:\n{instruction}\n### Input:\n{input}\n### Response:\n{output}"
texts = []
for i in range(len(examples["instruction"])):
full_text = f"### Instruction:\n{examples['instruction'][i]}\n### Input:\n{examples['input'][i]}\n### Response:\n{examples['output'][i]}{tokenizer.eos_token}"
texts.append(full_text)
# 토크나이징
tokenized_inputs = tokenizer(
texts,
max_length=256, # 최대 길이 설정
padding="max_length", # 최대 길이에 맞춰 패딩
truncation=True, # 최대 길이를 초과하면 잘라냄
return_tensors="pt"
)
# 레이블 생성 (input_ids를 복사하고, 프롬프트 부분은 -100으로 마스킹하여 loss 계산에서 제외)
labels = tokenized_inputs["input_ids"].clone()
# 프롬프트 부분의 길이를 계산하여 -100으로 마스킹 (옵션: 프롬프트도 학습하고 싶으면 이 부분 생략)
# 여기서는 간단히 전체를 레이블로 사용하고, 실제 학습 시 Trainer가 causal lm loss를 계산합니다.
# 더 정교한 마스킹은 다음 단계에서 Trainer에 전달하기 전에 수행할 수 있습니다.
tokenized_inputs["labels"] = labels
return tokenized_inputs
# 4. 데이터셋 전처리 적용
tokenized_dataset = dataset.map(preprocess_function, batched=True, remove_columns=dataset.column_names)
print(tokenized_dataset[0])
2단계: 학습 환경 설정 및 LoRA 모델 준비
데이터 준비가 완료되었다면, 이제 모델을 로드하고 LoRA 설정을 적용하여 학습을 위한 준비를 해야 합니다. GPU 환경은 필수적이며, Google Colab Pro, Kaggle Notebooks, AWS Sagemaker, Azure ML 등 클라우드 기반 GPU 환경을 활용하는 것이 일반적입니다.
코드 설명
이 코드는 Hugging Face Trainer를 사용하여 LoRA 파인튜닝을 수행하는 전체적인 흐름을 보여줍니다. TrainingArguments로 학습 파라미터를 설정하고, Trainer 객체를 생성하여 train() 메서드를 호출합니다.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer, DataCollatorForLanguageModeling
from peft import LoraConfig, get_peft_model, TaskType
from datasets import Dataset
# GPU 사용 설정
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using device: {device}")
# 1. 모델 및 토크나이저 로드
model_name = "EleutherAI/gpt-neo-125M"
tokenizer = AutoTokenizer.from_pretrained(model_name)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 모델을 4비트로 양자화하여 메모리 사용량 최적화 (LoRA와 함께 사용 시 매우 효과적)
# BitsAndBytesConfig는 transformers 4.30 이상에서 사용 가능
try:
from transformers import BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4", # NormalFloat4 (NF4) quantization
bnb_4bit_compute_dtype=torch.bfloat16, # bfloat16으로 연산
bnb_4bit_use_double_quant=True # 이중 양자화 사용
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto" # 자동으로 GPU에 모델 배치
)
except ImportError:
print("BitsAndBytesConfig not available, loading model without quantization.")
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
# 2. LoRA 설정 정의
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], # GPT-Neo 기준 예시
lora_dropout=0.05,
bias="none",
task_type=TaskType.CAUSAL_LM
)
peft_model = get_peft_model(model, lora_config)
peft_model.print_trainable_parameters()
# 3. 데이터 전처리 (위에서 정의한 preprocess_function 재사용)
data_for_train = [
{"instruction": "다음 문장을 긍정적으로 바꿔줘:", "input": "나는 오늘 기분이 좋지 않아.", "output": "나는 오늘 기분이 아주 좋아!"},
{"instruction": "다음 문장을 긍정적으로 바꿔줘:", "input": "이 영화는 정말 지루했어.", "output": "이 영화는 정말 흥미진진했어!"},
{"instruction": "다음 문장을 긍정적으로 바꿔줘:", "input": "내일 시험이 걱정돼.", "output": "내일 시험이 기대돼!"},
{"instruction": "다음 문장을 긍정적으로 바꿔줘:", "input": "비가 와서 나갈 수 없어.", "output": "비가 와서 집에서 쉬는 게 좋아!"},
{"instruction": "다음 문장을 긍정적으로 바꿔줘:", "input": "숙제가 너무 많아.", "output": "숙제를 다 하면 뿌듯할 거야!"},
{"instruction": "다음 문장을 긍정적으로 바꿔줘:", "input": "친구가 약속을 취소했어.", "output": "친구가 다음엔 더 좋은 약속을 잡아줄 거야!"},
{"instruction": "다음 문장을 긍정적으로 바꿔줘:", "input": "컴퓨터가 너무 느려.", "output": "컴퓨터가 느려도 괜찮아, 잠시 쉬었다 할 수 있지."},
{"instruction": "다음 문장을 긍정적으로 바꿔줘:", "input": "아침에 늦잠을 잤어.", "output": "늦잠을 자서 개운해!"},
{"instruction": "다음 문장을 긍정적으로 바꿔줘:", "input": "밥이 맛이 없어.", "output": "밥이 맛이 없어도 영양분은 충분해."},
{"instruction": "다음 문장을 긍정적으로 바꿔줘:", "input": "날씨가 너무 더워.", "output": "날씨가 더워도 시원한 음료 한 잔 마시면 돼!"}
]
dataset_train = Dataset.from_list(data_for_train)
def preprocess_function(examples):
texts = []
for i in range(len(examples["instruction"])):
full_text = f"### Instruction:\n{examples['instruction'][i]}\n### Input:\n{examples['input'][i]}\n### Response:\n{examples['output'][i]}{tokenizer.eos_token}"
texts.append(full_text)
tokenized_inputs = tokenizer(
texts,
max_length=256,
padding="max_length",
truncation=True,
return_tensors="pt"
)
tokenized_inputs["labels"] = tokenized_inputs["input_ids"].clone()
return tokenized_inputs
tokenized_dataset = dataset_train.map(preprocess_function, batched=True, remove_columns=dataset_train.column_names)
# 4. Data Collator 정의 (Causal Language Modeling을 위한)
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
# 5. TrainingArguments 설정
training_args = TrainingArguments(
output_dir="./lora_finetuned_model", # 모델 저장 경로
per_device_train_batch_size=4, # 배치 크기 (GPU 메모리에 따라 조절)
gradient_accumulation_steps=2, # 기울기 누적 스텝 (실질 배치 크기 4*2=8)
warmup_steps=50, # 웜업 스텝 수
max_steps=200, # 최대 학습 스텝 수 (적은 데이터셋이므로 작게 설정)
learning_rate=2e-4, # 학습률
fp16=True, # 혼합 정밀도 학습 (메모리 및 속도 향상)
logging_steps=10, # 로깅 주기
save_steps=100, # 모델 저장 주기
report_to="none", # wandb 등 리포트 툴 사용 안함
overwrite_output_dir=True,
)
# 6. Trainer 객체 생성 및 학습 시작
trainer = Trainer(
model=peft_model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer,
data_collator=data_collator,
)
print("Starting training...")
trainer.train()
print("Training finished.")
# 학습된 LoRA 어댑터 저장
peft_model.save_pretrained("./lora_finetuned_model")
tokenizer.save_pretrained("./lora_finetuned_model")
print("LoRA adapter and tokenizer saved to ./lora_finetuned_model")
# 7. 파인튜닝된 모델로 추론 테스트
# 원본 모델에 학습된 LoRA 어댑터를 로드
from peft import PeftModel
inference_model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype=torch.bfloat16)
inference_model = PeftModel.from_pretrained(inference_model, "./lora_finetuned_model")
inference_model = inference_model.merge_and_unload() # LoRA 어댑터를 원본 모델에 병합 (선택 사항)
inference_model.eval()
inference_tokenizer = AutoTokenizer.from_pretrained("./lora_finetuned_model")
prompt_test = "### Instruction:\n다음 문장을 긍정적으로 바꿔줘:\n### Input:\n나는 오늘 일이 너무 많아서 피곤해.\n### Response:\n"
input_ids = inference_tokenizer(prompt_test, return_tensors="pt").input_ids.to(device)
with torch.no_grad():
output_tokens = inference_model.generate(
input_ids,
max_new_tokens=50,
num_return_sequences=1,
pad_token_id=inference_tokenizer.eos_token_id,
do_sample=True,
temperature=0.7,
top_k=50,
top_p=0.95
)
generated_text = inference_tokenizer.decode(output_tokens[0], skip_special_tokens=True)
print("\n--- Generated Text ---")
print(generated_text)
# 출력 예시:
# --- Generated Text ---
# ### Instruction:
# 다음 문장을 긍정적으로 바꿔줘:
# ### Input:
# 나는 오늘 일이 너무 많아서 피곤해.
# ### Response:
# 나는 오늘 일이 많아서 뿌듯해!
핵심 포인트
고품질의 데이터셋 구성, 적절한 토크나이징 전처리, 그리고 Hugging Face Trainer를 활용한 학습이 LLM 파인튜닝의 성공적인 워크플로우를 만듭니다.
[그림 3] LLM 파인튜닝의 표준 워크플로우는 체계적인 단계를 거쳐 진행됩니다.
문제 해결
흔히 겪는 문제와 해결 팁
LLM 파인튜닝은 여전히 복잡한 과정이며, 다양한 기술적 문제에 직면할 수 있습니다. 특히 GPU 메모리 부족, 학습 수렴 실패는 초보자들이 가장 많이 겪는 문제입니다. 다음은 흔히 겪는 문제와 그 해결 팁입니다.
문제 01
OOM (Out Of Memory) 에러
GPU 메모리가 부족하여 학습이 중단되는 문제입니다. 특히 큰 모델이나 높은 배치 사이즈를 사용할 때 자주 발생합니다.
해결 — GPU 메모리 최적화 기법 활용
★ LoRA (또는 다른 PEFT 기법) 사용: 가장 효과적인 방법입니다. 학습 가능한 파라미터 수를 획기적으로 줄여줍니다.
★ Quantization (양자화): 모델의 가중치를 FP32에서 FP16, BF16, 또는 8비트/4비트로 낮춰 메모리 사용량을 줄입니다. Hugging Face bitsandbytes 라이브러리를 통해 쉽게 적용할 수 있습니다.
★ Gradient Accumulation (기울기 누적): 배치 사이즈를 줄이는 대신 여러 스텝에 걸쳐 기울기를 누적하여 실질적인 배치 사이즈 효과를 낼 수 있습니다. TrainingArguments의 gradient_accumulation_steps 파라미터를 사용합니다.
★ Mixed Precision Training (혼합 정밀도 학습): FP16(반정밀도)을 사용하여 메모리 사용량을 절반으로 줄이고 학습 속도를 높입니다. TrainingArguments의 fp16=True 설정으로 활성화합니다.
★ 모델 크기 줄이기: 가능하다면 더 작은 규모의 베이스 모델을 선택합니다.
문제 02
학습이 잘 안 되는 경우 (수렴 실패)
학습 손실(loss)이 줄어들지 않거나, 모델의 성능이 개선되지 않는 경우입니다.
해결 — 학습 파라미터 및 데이터 점검
★ 데이터 품질 확인: 가장 먼저 해야 할 일입니다. 오탈자, 잘못된 형식, 편향된 데이터 등은 학습을 방해합니다. 데이터셋을 직접 검토하여 문제가 없는지 확인하세요.
★ 학습률(Learning Rate) 조정: 학습률이 너무 높으면 발산하고, 너무 낮으면 학습이 느리거나 수렴하지 않을 수 있습니다. 1e-5 ~ 5e-5 범위에서 시작하여 2e-4까지 다양한 값을 시도해 보세요.
★ LoRA 파라미터 조정: r 값을 조금 더 높여 모델의 표현력을 늘려보거나, target_modules에 더 많은 레이어를 포함시켜 보세요.
★ 프롬프트 형식 통일: 모델이 학습 데이터의 프롬프트 형식을 일관되게 이해하도록 특정 템플릿을 사용하는 것이 좋습니다. (예: ### Instruction:\n{instruction}\n### Response:\n{response})
★ 학습 스텝 및 에포크 증가: 데이터 양이 충분하다면, 학습 스텝이나 에포크를 늘려 모델이 더 많이 학습할 기회를 제공하세요.
문제 03
추론 속도 저하
파인튜닝된 모델의 추론(inference) 속도가 느려 사용자 경험을 저해하는 경우입니다.
해결 — 최적화된 추론 환경 구축
★ LoRA 어댑터 병합 (Merge and Unload): 학습이 완료된 LoRA 어댑터를 원본 모델에 병합하여 하나의 모델처럼 사용할 수 있습니다. 이렇게 하면 추론 시 PeftModel의 오버헤드가 제거되어 속도가 향상됩니다.
★ Quantization (양자화): 추론 시에도 8비트/4비트 양자화된 모델을 사용하면 메모리 사용량과 함께 추론 속도도 향상될 수 있습니다.
★ torch.compile: PyTorch 2.0부터 도입된 torch.compile은 모델을 최적화하여 CPU/GPU 모두에서 성능을 향상시킬 수 있습니다.
★ FlashAttention: 특히 트랜스포머 기반 모델에서 어텐션 메커니즘의 계산 효율을 크게 높여주는 기법입니다. 최신 GPU와 함께 사용 시 효과적입니다.
★ TensorRT, ONNX Runtime 등 추론 최적화 엔진 활용: 프로덕션 환경에서는 이러한 엔진을 사용하여 모델을 컴파일하고 가속화하는 것이 일반적입니다.
핵심 포인트
LLM 파인튜닝 시 발생하는 문제는 대부분 데이터, 학습 파라미터, 또는 리소스 제약과 관련되어 있습니다. 체계적인 디버깅과 최적화 기법 적용이 중요합니다.
[그림 4] LoRA와 양자화는 GPU 메모리를 절약하는 데 매우 효과적입니다.
FAQ: LLM 파인튜닝 궁금증 해소
Q. 파인튜닝을 꼭 해야 하나요?
아니요, 모든 경우에 파인튜닝이 필요한 것은 아닙니다. 범용 LLM의 프롬프트 엔지니어링만으로 충분한 성능을 낼 수 있다면 파인튜닝은 불필요합니다. 하지만 특정 도메인에 대한 지식, 특정 스타일의 응답, 또는 복잡한 추론 능력이 필요하다면 파인튜닝이 훨씬 효과적입니다.
Q. LoRA는 어떤 모델에 적용할 수 있나요?
LoRA는 트랜스포머 아키텍처를 기반으로 하는 대부분의 LLM에 적용할 수 있습니다. Llama, GPT 계열, T5, Falcon 등 Hugging Face Transformers 라이브러리에서 지원하는 다양한 모델에 PEFT 라이브러리를 통해 쉽게 적용할 수 있습니다. 단, target_modules 설정은 모델 아키텍처에 따라 달라질 수 있습니다.
Q. 파인튜닝 데이터는 얼마나 필요한가요?
필요한 데이터의 양은 모델의 크기, 태스크의 복잡성, 그리고 원하는 성능 수준에 따라 크게 달라집니다. 일반적으로 수백 개에서 수천 개의 고품질 샘플이 권장되며, 수만 개 이상의 데이터가 있다면 더 좋은 성능을 기대할 수 있습니다. 데이터의 양보다는 품질이 더 중요합니다.
Q. 파인튜닝 후 모델 평가는 어떻게 하나요?
파인튜닝된 모델은 검증 데이터셋(Validation Dataset)을 사용하여 평가합니다. 텍스트 생성 태스크의 경우 BLEU, ROUGE와 같은 자동 평가 지표와 함께, 사람의 직접적인 평가(Human Evaluation)가 매우 중요합니다. 생성된 텍스트의 유용성, 일관성, 정확성 등을 종합적으로 판단해야 합니다.