

요약
Spring Data JPA 완벽 가이드 2026
2026년 백엔드 개발의 핵심, Spring Data JPA의 모든 것을 파헤칩니다.
핵심 키워드: 엔티티 설계, N+1 문제 해결, 쿼리 최적화
이 글의 순서
1. Spring Data JPA, 왜 사용해야 할까요?
2. Spring Data JPA 기본기: 엔티티 설계부터 리포지토리까지
3. 쿼리 메소드와 JPQL: 데이터 조회 정복하기
4. 성능 저하의 주범 N+1 문제, 완벽 해결 전략
5. 복잡한 쿼리 처리와 고급 기능 활용
6. Spring Data JPA vs Mybatis: 어떤 것을 선택할까?
7. 자주 묻는 질문 (FAQ)
8. 2026년, Spring Data JPA의 미래
배경/도입
Spring Data JPA, 왜 사용해야 할까요?
안녕하세요, 권퓨터입니다! 2026년에도 백엔드 개발 생태계는 빠르게 진화하고 있습니다. 그중에서도 개발 생산성과 유지보수성을 크게 향상시키는 기술로 Spring Data JPA는 여전히 독보적인 위치를 차지하고 있죠. 하지만 많은 개발자들이 JPA의 강력함에 이끌려 시작했다가, 복잡한 연관관계 매핑이나 N+1 문제 같은 성능 이슈에 부딪혀 어려움을 겪기도 합니다.
이번 포스트에서는 Spring Data JPA를 처음 접하는 분들부터 이미 사용 중이지만 성능 최적화에 목마른 분들까지, 모든 개발자들이 만족할 만한 깊이 있는 가이드를 제공하려고 합니다. 엔티티 설계의 기본 원칙부터 시작해서, 실제 프로젝트에서 마주할 수 있는 N+1 문제의 해결책, 그리고 복잡한 쿼리를 효율적으로 다루는 방법까지, 권퓨터의 노하우를 아낌없이 공유해 드릴게요.
우리가 왜 Spring Data JPA를 사용해야 하는지부터 차근차근 알아볼까요? 핵심은 바로 ‘객체-관계형 데이터베이스 불일치(Object-Relational Impedance Mismatch)’ 문제를 해결하고, 개발자가 비즈니스 로직에 집중할 수 있도록 돕는다는 점입니다. 전통적인 SQL 기반 개발 방식은 객체지향 프로그래밍 패러다임과 데이터베이스의 관계형 패러다임 사이의 간극 때문에 많은 반복적인 코드와 복잡성을 야기했습니다. JPA(Java Persistence API)는 이러한 문제를 해결하기 위한 자바 표준 명세이며, Hibernate 같은 ORM(Object-Relational Mapping) 프레임워크가 이 명세를 구현합니다.
그럼 Spring Data JPA는 무엇일까요? Spring Data JPA는 JPA를 더욱 쉽게 사용할 수 있도록 스프링 프레임워크가 제공하는 모듈입니다. 단순히 JPA를 감싸는 것을 넘어, 개발자가 직접 리포지토리 인터페이스를 구현하지 않아도 메소드 이름만으로 쿼리를 자동으로 생성해주는 강력한 기능을 제공하여 개발 생산성을 극대화합니다. 예를 들어, findByEmailAndName(String email, String name)과 같은 메소드를 선언하는 것만으로도 필요한 쿼리가 자동으로 만들어지는 것이죠. 이 덕분에 우리는 반복적인 CRUD(Create, Read, Update, Delete) 코드 작성에서 벗어나 핵심 비즈니스 로직 구현에 더 많은 시간을 할애할 수 있게 됩니다.
2026년 현재, 마이크로서비스 아키텍처와 클라우드 네이티브 환경이 보편화되면서 백엔드 개발의 복잡성은 더욱 증가하고 있습니다. 이런 환경에서 Spring Data JPA는 빠른 개발 속도와 높은 유지보수성을 제공하여 개발팀의 생산성을 비약적으로 끌어올리는 데 필수적인 도구로 자리 잡았습니다. 이제부터 Spring Data JPA의 세계로 함께 떠나볼까요?
핵심 포인트
Spring Data JPA는 JPA를 스프링 생태계에 통합하여, 반복적인 CRUD 코드 작성을 줄이고 개발 생산성을 극대화하는 강력한 ORM 도구입니다.
핵심 내용
Spring Data JPA 기본기: 엔티티 설계부터 리포지토리까지
JPA는 자바 애플리케이션에서 관계형 데이터베이스를 사용하는 방식을 정의한 인터페이스, 즉 ‘명세’입니다. 데이터베이스와 객체 간의 매핑을 위한 표준을 제공하죠. Hibernate는 이 JPA 명세를 구현한 대표적인 ORM 프레임워크입니다. 그리고 Spring Data JPA는 이 Hibernate(JPA 구현체)를 스프링 프레임워크에서 더 편리하게 사용할 수 있도록 추상화 계층을 제공하는 모듈입니다. 복잡한 설정 없이 간단한 인터페이스 선언만으로 데이터베이스 연동이 가능해지는 마법 같은 일이 벌어집니다.
1. JPA와 Spring Data JPA의 관계
엔티티는 데이터베이스 테이블과 매핑될 객체를 의미합니다. Spring Data JPA의 핵심은 이 엔티티를 얼마나 객체지향적으로 잘 설계하느냐에 달려있습니다. 다음은 엔티티 설계 시 고려해야 할 주요 원칙과 어노테이션입니다.
☑ @Entity와 @Table: 클래스가 엔티티임을 명시하고, 매핑될 테이블 이름을 지정합니다.
☑ @Id와 @GeneratedValue: 기본 키(Primary Key)를 지정하고, 키 생성 전략을 설정합니다. 대표적인 전략으로는 데이터베이스가 자동으로 ID를 생성하는 IDENTITY (MySQL, PostgreSQL)와 시퀀스 객체를 활용하는 SEQUENCE (Oracle)가 있습니다. 2026년 현재 클라우드 환경에서는 IDENTITY 전략이 많이 사용됩니다.
☑ @Column: 컬럼의 속성(길이, null 허용 여부 등)을 정의합니다. 예를 들어, length = 255, nullable = false 등으로 설정할 수 있습니다.
☑ 값 타입 (Embeddable Type): 주소나 기간처럼 여러 속성으로 구성되지만 독립적인 생명주기를 가지지 않고 엔티티에 속하는 값들은 @Embeddable과 @Embedded를 사용하여 값 타입으로 설계할 수 있습니다. 이는 재사용성과 응집도를 높여줍니다.
2. 엔티티 설계 원칙과 연관관계 매핑
객체는 참조를 통해 관계를 맺지만, 관계형 데이터베이스는 외래 키(Foreign Key)를 통해 관계를 맺습니다. 이 간극을 메우는 것이 연관관계 매핑입니다. 단방향/양방향, 다대일/일대다/일대일/다대다 등 다양한 관계가 있습니다.
☑ @ManyToOne, @OneToMany: 가장 흔하게 사용되는 관계입니다. 예를 들어, 여러 명의 회원이 하나의 팀에 속하는 경우 Member 엔티티는 Team 엔티티에 @ManyToOne으로, Team 엔티티는 Member 엔티티에 @OneToMany로 매핑할 수 있습니다.
☑ 양방향 연관관계 주의점: 양방향 연관관계는 객체 그래프 탐색에 용이하지만, 연관관계의 주인을 명확히 설정해야 합니다. 외래 키를 관리하는 쪽이 ‘주인’이 되며, 다른 쪽은 mappedBy 속성을 사용하여 주인이 아님을 명시해야 합니다. 주인만이 외래 키를 등록, 수정할 수 있습니다. 그렇지 않으면 데이터 불일치 문제가 발생할 수 있습니다.
코드 설명
간단한 회원(Member)과 팀(Team) 엔티티를 설계하여 Spring Data JPA의 기본 구조를 보여줍니다. 양방향 연관관계에서 연관관계의 주인을 명확히 설정하는 방법을 포함합니다.
// Team.java
package com.kwonputer.domain;
import jakarta.persistence.*;
import java.util.ArrayList;
import java.util.List;
@Entity
@Table(name = "teams")
public class Team {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, length = 100)
private String name;
// 양방향 연관관계의 주인이 아님 (읽기 전용)
// mappedBy: Member 엔티티의 team 필드에 의해 매핑됨을 의미
// CascadeType.ALL: Team이 영속화될 때 Member도 함께 영속화
// orphanRemoval = true: 부모 엔티티에서 자식 엔티티가 제거되면 자식 엔티티도 DB에서 삭제
@OneToMany(mappedBy = "team", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Member> members = new ArrayList<>();
protected Team() {}
public Team(String name) {
this.name = name;
}
// 연관관계 편의 메소드
public void addMember(Member member) {
this.members.add(member);
member.setTeam(this); // Member의 team 필드도 설정
}
// Getter
public Long getId() { return id; }
public String getName() { return name; }
public List<Member> getMembers() { return members; }
// Setter (필요시 사용, 일반적으로 엔티티는 불변성을 지향)
public void setName(String name) { this.name = name; }
}
// Member.java
package com.kwonputer.domain;
import jakarta.persistence.*;
@Entity
@Table(name = "members")
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, length = 50)
private String name;
@Column(nullable = false, unique = true, length = 100)
private String email;
// 연관관계의 주인 (외래 키를 관리)
// fetch = FetchType.LAZY: 지연 로딩 (기본값은 EAGER)
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id") // 외래 키 컬럼명 지정
private Team team;
protected Member() {}
public Member(String name, String email) {
this.name = name;
this.email = email;
}
// Getter
public Long getId() { return id; }
public String getName() { return name; }
public String getEmail() { return email; }
public Team getTeam() { return team; }
// Setter (연관관계 편의 메소드에서 사용)
public void setTeam(Team team) {
this.team = team;
}
}
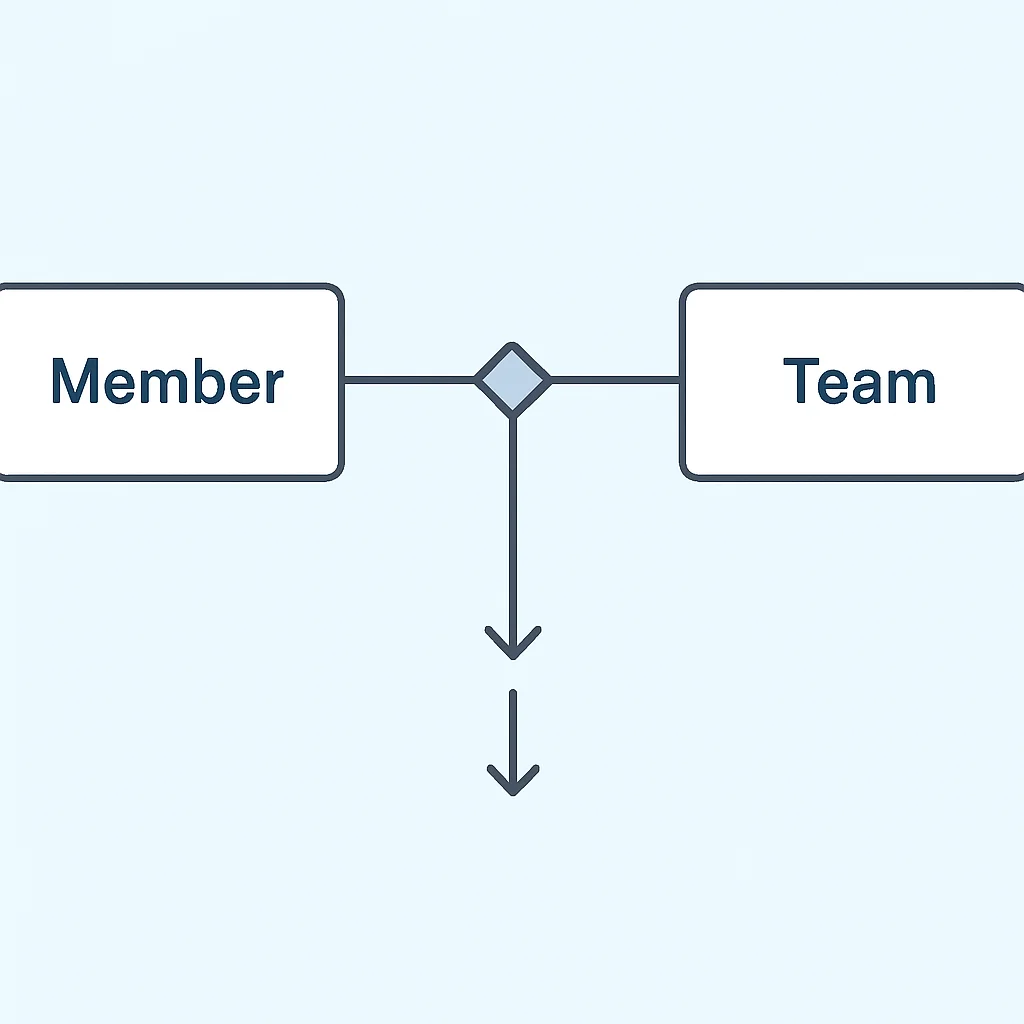
위 예시에서 Member 엔티티의 team 필드가 @ManyToOne으로 연관관계의 주인이며, 실제 데이터베이스의 team_id 외래 키를 관리합니다. 반면 Team 엔티티의 members 필드는 mappedBy="team"을 통해 연관관계의 주인이 아님을 명시하고 있습니다. 이렇게 함으로써 데이터의 일관성을 유지하고 불필요한 업데이트를 방지할 수 있습니다.
4. 리포지토리 인터페이스
Spring Data JPA는 JpaRepository 인터페이스를 상속받아 간단하게 리포지토리를 정의할 수 있습니다. 이 인터페이스는 기본적인 CRUD 기능(저장, 조회, 수정, 삭제)은 물론, 페이징 및 정렬 기능까지 제공합니다.
코드 설명
Member와 Team 엔티티를 위한 간단한 JpaRepository 인터페이스 정의입니다. Spring Data JPA가 제공하는 기본 기능을 활용할 수 있습니다.
// MemberRepository.java
package com.kwonputer.repository;
import com.kwonputer.domain.Member;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface MemberRepository extends JpaRepository<Member, Long> {
// Spring Data JPA가 자동으로 쿼리 메소드를 생성
Member findByEmail(String email);
List<Member> findByNameContaining(String name);
List<Member> findByTeamName(String teamName); // Team 엔티티의 name 필드를 통해 조회
}
// TeamRepository.java
package com.kwonputer.repository;
import com.kwonputer.domain.Team;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface TeamRepository extends JpaRepository<Team, Long> {
Team findByName(String name);
}
핵심 포인트
엔티티 설계 시 객체지향 패러다임을 최대한 살리고, 연관관계의 주인 개념을 명확히 이해하여 데이터 무결성을 확보하는 것이 중요합니다.
핵심 내용
쿼리 메소드와 JPQL: 데이터 조회 정복하기
데이터를 조회하는 것은 백엔드 애플리케이션의 핵심 기능 중 하나입니다. Spring Data JPA는 이 조회 기능을 매우 편리하게 사용할 수 있도록 두 가지 강력한 방법을 제공합니다. 바로 ‘쿼리 메소드’와 ‘JPQL’입니다.
1. 쿼리 메소드: 직관적인 메소드 이름으로 쿼리 생성
쿼리 메소드는 Spring Data JPA의 가장 큰 장점 중 하나로, 메소드 이름만으로도 SQL 쿼리를 자동으로 생성해줍니다. 정해진 규칙에 따라 메소드 이름을 작성하면, Spring Data JPA가 이를 파싱하여 적절한 JPQL(Java Persistence Query Language)을 생성하고 실행합니다. 이는 반복적인 쿼리 작성을 줄여 개발 생산성을 크게 높여줍니다.
주요 규칙:
☑ findBy[컬럼명]: 특정 컬럼으로 조회 (예: findByEmail(String email))
☑ findBy[컬럼명]And[다른컬럼명]: 여러 컬럼을 AND 조건으로 조회 (예: findByNameAndEmail(String name, String email))
☑ Containing, StartingWith, EndingWith: Like 연산자 (예: findByNameContaining(String keyword))
☑ OrderBy[컬럼명]Asc/Desc: 정렬 (예: findAllByOrderByNameDesc())
☑ 연관관계 필드 조회: findByTeamName(String teamName)처럼 연관된 엔티티의 필드로도 조회가 가능합니다.
2. @Query 어노테이션과 JPQL: 복잡한 쿼리에 대한 유연성
쿼리 메소드만으로는 모든 복잡한 조회 조건을 처리하기 어렵습니다. 이럴 때 @Query 어노테이션과 JPQL(Java Persistence Query Language)을 활용할 수 있습니다. JPQL은 SQL과 유사하지만, 데이터베이스 테이블이 아닌 ‘엔티티 객체’를 대상으로 쿼리한다는 점에서 차이가 있습니다. 이를 통해 객체지향적인 방식으로 쿼리를 작성할 수 있습니다.
코드 설명
Spring Data JPA에서 쿼리 메소드와 @Query 어노테이션을 활용하여 데이터를 조회하는 다양한 방법을 보여줍니다. 특히 DTO Projection을 통해 필요한 데이터만 조회하는 방법을 포함합니다.
// MemberRepository.java (추가)
package com.kwonputer.repository;
import com.kwonputer.domain.Member;
import com.kwonputer.dto.MemberInfoDto;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import org.springframework.stereotype.Repository;
import java.util.List;
import java.util.Optional;
@Repository
public interface MemberRepository extends JpaRepository<Member, Long> {
// 1. 쿼리 메소드 예시
Optional<Member> findByEmail(String email);
List<Member> findByNameStartingWith(String prefix);
List<Member> findByTeamNameAndNameContaining(String teamName, String memberName);
// 2. @Query 어노테이션과 JPQL 예시
// :name, :email과 같이 파라미터를 명시적으로 바인딩
@Query("SELECT m FROM Member m WHERE m.name = :name AND m.email = :email")
List<Member> findMembersByNameAndEmail(@Param("name") String name, @Param("email") String email);
// 네이티브 SQL 쿼리 사용 예시 (nativeQuery = true)
@Query(value = "SELECT * FROM members WHERE team_id = :teamId", nativeQuery = true)
List<Member> findMembersByTeamIdNative(@Param("teamId") Long teamId);
// 3. DTO Projection: 인터페이스 기반
// 인터페이스에 getter 메소드를 정의하여 필요한 필드만 조회
@Query("SELECT m.name as memberName, m.email as memberEmail, t.name as teamName FROM Member m JOIN m.team t WHERE t.id = :teamId")
List<MemberInfoProjection> findMemberInfoByTeamId(@Param("teamId") Long teamId);
// 4. DTO Projection: 클래스 기반 (생성자 사용)
@Query("SELECT new com.kwonputer.dto.MemberInfoDto(m.name, m.email, t.name) FROM Member m JOIN m.team t WHERE t.id = :teamId")
List<MemberInfoDto> findMemberInfoDtoByTeamId(@Param("teamId") Long teamId);
}
코드 설명
DTO Projection을 위한 인터페이스와 클래스 정의입니다. 실제 엔티티 대신 필요한 데이터만 담아 전송함으로써 네트워크 대역폭과 메모리를 절약할 수 있습니다.
// MemberInfoProjection.java (인터페이스 기반 DTO Projection)
package com.kwonputer.dto;
public interface MemberInfoProjection {
String getMemberName();
String getMemberEmail();
String getTeamName();
}
// MemberInfoDto.java (클래스 기반 DTO Projection)
package com.kwonputer.dto;
public class MemberInfoDto {
private String memberName;
private String memberEmail;
private String teamName;
public MemberInfoDto(String memberName, String memberEmail, String teamName) {
this.memberName = memberName;
this.memberEmail = memberEmail;
this.teamName = teamName;
}
// Getter
public String getMemberName() { return memberName; }
public String getMemberEmail() { return memberEmail; }
public String getTeamName() { return teamName; }
// Setter (필요시 추가)
public void setMemberName(String memberName) { this.memberName = memberName; }
public void setMemberEmail(String memberEmail) { this.memberEmail = memberEmail; }
public void setTeamName(String teamName) { this.teamName = teamName; }
}
3. Projection: 필요한 데이터만 조회하기
엔티티 전체를 조회하는 것은 때때로 불필요한 데이터를 로딩하여 성능 저하를 야기할 수 있습니다. Projection은 필요한 특정 필드만 선택적으로 조회하는 기능입니다. 위 코드 예시처럼 인터페이스나 DTO 클래스를 활용하여 Projection을 구현할 수 있습니다. 이는 특히 대량의 데이터를 조회할 때 네트워크 전송량과 메모리 사용량을 줄여주는 효과적인 방법입니다.
인터페이스 기반 Projection은 런타임에 동적으로 구현체를 생성하여 데이터를 매핑합니다. 클래스 기반 Projection은 생성자를 통해 데이터를 주입받는 방식으로 동작하며, JPQL의 NEW 키워드를 사용하여 직접 DTO 객체를 생성합니다. 어떤 방식을 사용하든, 목적은 동일합니다: 불필요한 데이터 로딩을 최소화하고 애플리케이션의 효율성을 높이는 것입니다.
핵심 포인트
간단한 조회는 쿼리 메소드를, 복잡한 조회는 @Query와 JPQL을 사용하며, 성능 최적화를 위해 Projection을 적극적으로 활용하세요.
문제 해결
성능 저하의 주범 N+1 문제, 완벽 해결 전략
Spring Data JPA를 사용하면서 가장 흔하게 마주치고, 동시에 가장 큰 성능 문제를 일으키는 것이 바로 ‘N+1 문제’입니다. 이름만 들어도 벌써 머리가 아파오는 분들도 계실 텐데요, 권퓨터가 쉽게 설명하고 완벽한 해결 전략을 제시해 드릴게요!
1. N+1 문제란 무엇인가?
N+1 문제는 주로 ‘지연 로딩(Lazy Loading)’을 사용하는 연관관계에서 발생합니다. 예를 들어, 우리가 10개의 팀(Team)을 조회하면서 각 팀에 속한 회원(Member) 정보도 함께 조회하고 싶다고 가정해 봅시다. JPA는 기본적으로 @OneToMany 관계를 지연 로딩으로 설정합니다. 즉, 팀을 조회할 때는 회원 정보를 즉시 가져오지 않고, 실제로 회원 정보에 접근할 때(예: team.getMembers() 호출 시) 그때서야 추가 쿼리를 날려 가져옵니다.
여기서 문제가 발생합니다. 10개의 팀을 조회하는 데 1번의 쿼리(N=10에서 1)가 실행되고, 각 팀의 회원을 조회하기 위해 다시 10번의 쿼리가 추가로 실행됩니다. 총 1(팀 조회) + N(각 팀의 회원 조회) = 1 + 10 = 11번의 쿼리가 나가는 것이죠. 만약 팀의 개수가 100개라면 101번의 쿼리가 발생하게 되고, 이는 심각한 성능 저하로 이어집니다. 이것이 바로 N+1 문제입니다.
2. N+1 문제 해결 전략
다행히 N+1 문제를 해결할 수 있는 다양한 방법들이 있습니다. 상황에 따라 적절한 방법을 선택하는 것이 중요합니다.
Fetch Join
✓ JPQL에서 FETCH JOIN을 사용하여 연관된 엔티티를 한 번의 쿼리로 함께 로딩합니다. 가장 강력하고 일반적으로 추천되는 방법입니다.
✓ 다대일(@ManyToOne), 일대일(@OneToOne) 관계에서는 중복 없이 데이터를 가져오지만, 일대다(@OneToMany) 관계에서는 데이터베이스 row 수가 늘어나 중복이 발생할 수 있으므로 DISTINCT 키워드를 함께 사용하는 것이 좋습니다.
@EntityGraph
✓ @Query에 @EntityGraph를 사용하여 선언적으로 Fetch 전략을 지정합니다. JPQL을 직접 작성하지 않고도 Fetch Join과 유사한 효과를 낼 수 있습니다. attributePaths에 함께 가져올 연관관계 필드를 지정합니다.
Batch Size 설정
✓ application.yml에 hibernate.default_batch_fetch_size를 설정하면, N+1 문제가 발생했을 때 개별 쿼리 대신 설정된 크기만큼 IN 쿼리로 한 번에 가져옵니다. 예를 들어 100개의 팀을 조회할 때, Batch Size가 10이라면 10번의 쿼리(100/10)만 추가로 발생합니다. 이는 Fetch Join이 불가능하거나 복잡한 상황에서 유용합니다.
Dto Projections
✓ 엔티티가 아닌 DTO로 직접 필요한 데이터만 조회합니다. 이는 애초에 연관된 엔티티를 로딩할 필요가 없으므로 N+1 문제의 근원을 차단합니다. 다만, 엔티티의 변경 감지(Dirty Checking)와 같은 JPA의 영속성 컨텍스트 기능은 활용할 수 없습니다.
Read-Only 트랜잭션
✓ 조회 전용 로직에서는 @Transactional(readOnly = true)를 적용하여 JPA가 엔티티의 스냅샷을 생성하지 않도록 하여 메모리 사용량과 성능을 미세하게 개선할 수 있습니다. 이는 N+1 직접 해결책이라기보다는 전반적인 조회 성능 최적화에 기여합니다.
가장 일반적으로는 Fetch Join이나 @EntityGraph를 사용하여 N+1 문제를 해결합니다. 대량의 데이터를 DTO로 바로 조회할 필요가 있다면 DTO Projection이 효과적입니다. 프로젝트의 특성과 요구사항에 맞춰 최적의 전략을 선택하는 것이 중요합니다.
코드 설명
N+1 문제가 발생하는 상황과 Fetch Join, @EntityGraph를 사용하여 이를 해결하는 예시를 보여줍니다. 실제 서비스 계층에서 어떻게 활용되는지 간접적으로 확인할 수 있습니다.
// MemberRepository.java (N+1 해결 쿼리 추가)
package com.kwonputer.repository;
import com.kwonputer.domain.Member;
import org.springframework.data.jpa.repository.EntityGraph;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository
public interface MemberRepository extends JpaRepository<Member, Long> {
// N+1 문제 발생 예시 (Team을 조회 후 각 Team의 Member에 접근 시 N번의 쿼리 발생)
// List<Team> findAll();
// 1. Fetch Join을 이용한 N+1 문제 해결 (Team과 Member를 한 번에 조회)
// DISTINCT 키워드를 사용하여 중복된 Team 엔티티를 제거
@Query("SELECT DISTINCT t FROM Team t JOIN FETCH t.members")
List<Team> findAllTeamsWithMembersFetchJoin();
// 2. @EntityGraph를 이용한 N+1 문제 해결
// attributePaths = "members": Team을 조회할 때 members 컬렉션도 함께 Fetch 함
@EntityGraph(attributePaths = "members")
@Query("SELECT t FROM Team t") // JPQL 쿼리는 간단하게 작성
List<Team> findAllTeamsWithMembersEntityGraph();
// 특정 팀 이름으로 팀과 멤버를 함께 조회 (Fetch Join)
@Query("SELECT DISTINCT t FROM Team t JOIN FETCH t.members WHERE t.name = :teamName")
List<Team> findTeamsWithMembersByTeamNameFetchJoin(String teamName);
}
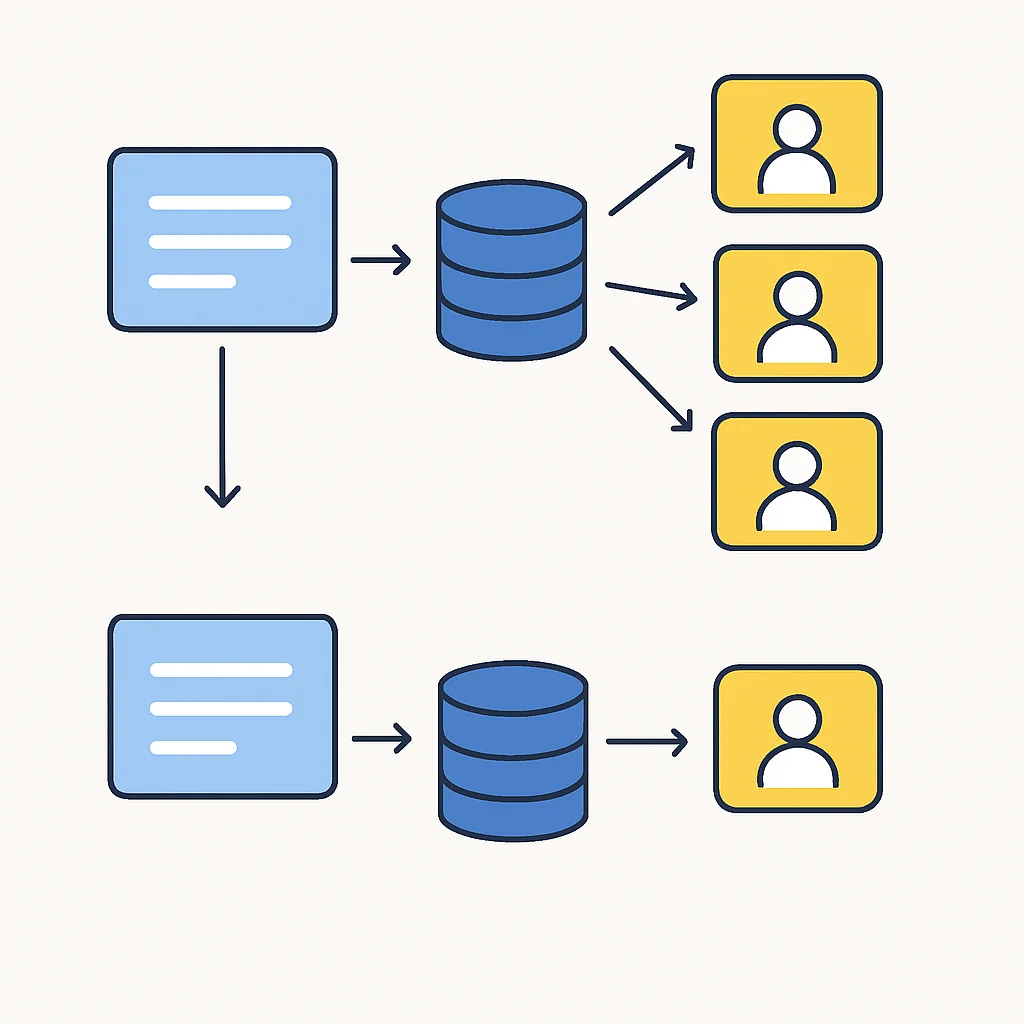
위 예시에서 findAllTeamsWithMembersFetchJoin() 메소드는 FETCH JOIN을 사용하여 팀과 회원 정보를 단 한 번의 쿼리로 가져옵니다. findAllTeamsWithMembersEntityGraph()는 @EntityGraph를 사용하여 동일한 효과를 냅니다. 이 두 가지 방법은 N+1 문제 해결에 있어 가장 강력한 도구이며, 실제 프로젝트에서 적극적으로 활용해야 합니다.
핵심 포인트
N+1 문제는 지연 로딩 시 발생하며, Fetch Join, @EntityGraph, Batch Size 설정, DTO Projection 등으로 해결할 수 있습니다. 가장 적절한 방법을 선택하여 쿼리 수를 최소화하는 것이 중요합니다.
실전 적용
복잡한 쿼리 처리와 고급 기능 활용
Spring Data JPA는 단순 CRUD를 넘어 복잡한 비즈니스 요구사항을 충족시키기 위한 다양한 고급 기능을 제공합니다. 동적 쿼리 처리부터 데이터의 생성/수정 시간 자동화, 그리고 논리적 삭제까지, 실제 프로젝트에서 유용하게 활용할 수 있는 기능들을 알아볼까요?
1. Querydsl: 타입 세이프한 동적 쿼리
JPQL은 문자열 기반이기 때문에 컴파일 시점에 오류를 잡아내기 어렵고, 복잡한 동적 쿼리를 작성하기 번거롭다는 단점이 있습니다. Querydsl은 이러한 문제를 해결하기 위해 등장한 프레임워크입니다. Querydsl은 자바 코드로 쿼리를 작성할 수 있게 해주며, 정적 타입을 지원하여 컴파일 시점에 오류를 감지할 수 있게 합니다. 이는 런타임 오류를 줄이고 개발 생산성을 크게 향상시킵니다.
Querydsl을 사용하려면 엔티티를 기반으로 Q-Class(QMember, QTeam 등)를 생성해야 합니다. 이 Q-Class를 통해 타입 안전하게 엔티티 필드를 참조하여 쿼리를 구성할 수 있습니다. 예를 들어, 특정 조건에 따라 WHERE 절이 동적으로 추가되거나, 정렬 기준이 달라지는 쿼리 등을 매우 유연하게 작성할 수 있습니다.
2. Auditing: 생성/수정 시간 자동화
대부분의 엔티티는 언제 생성되었고, 누가 언제 마지막으로 수정했는지와 같은 감사(Auditing) 정보가 필요합니다. Spring Data JPA는 이 정보를 자동으로 관리해주는 강력한 기능을 제공합니다. @EnableJpaAuditing 어노테이션을 활성화하고 엔티티에 @CreatedDate, @LastModifiedDate, @CreatedBy, @LastModifiedBy 어노테이션을 붙이면 됩니다.
이 기능은 보통 @MappedSuperclass를 사용하여 모든 엔티티가 상속받는 베이스 엔티티에 구현함으로써 중복 코드를 제거하고 일관성을 유지합니다.
코드 설명
모든 엔티티가 상속받을 수 있는 Auditing 기능을 포함한 베이스 엔티티 클래스입니다. 생성 시간, 수정 시간, 생성자, 수정자를 자동으로 관리합니다.
// BaseEntity.java
package com.kwonputer.domain;
import jakarta.persistence.Column;
import jakarta.persistence.EntityListeners;
import jakarta.persistence.MappedSuperclass;
import org.springframework.data.annotation.CreatedBy;
import org.springframework.data.annotation.CreatedDate;
import org.springframework.data.annotation.LastModifiedBy;
import org.springframework.data.annotation.LastModifiedDate;
import org.springframework.data.jpa.domain.support.AuditingEntityListener;
import java.time.LocalDateTime;
@MappedSuperclass // 엔티티가 아니며, 자식 엔티티에게 매핑 정보만 제공
@EntityListeners(AuditingEntityListener.class) // JPA Auditing 기능 활성화
public abstract class BaseEntity {
@CreatedDate
@Column(updatable = false) // 생성 시간은 업데이트되지 않음
private LocalDateTime createdAt;
@LastModifiedDate
private LocalDateTime lastModifiedAt;
@CreatedBy
@Column(updatable = false)
private String createdBy;
@LastModifiedBy
private String lastModifiedBy;
// Getter
public LocalDateTime getCreatedAt() { return createdAt; }
public LocalDateTime getLastModifiedAt() { return lastModifiedAt; }
public String getCreatedBy() { return createdBy; }
public String getLastModifiedBy() { return lastModifiedBy; }
}
// Member.java (BaseEntity 상속 예시)
package com.kwonputer.domain;
import jakarta.persistence.*;
@Entity
@Table(name = "members")
public class Member extends BaseEntity { // BaseEntity 상속
// ... 기존 필드 ...
}
실제 사용 시 @CreatedBy, @LastModifiedBy 필드에 값을 주입하려면 AuditorAware 인터페이스를 구현하여 현재 인증된 사용자 정보를 제공해야 합니다.
3. Soft Delete (논리적 삭제) 구현
데이터를 실제로 데이터베이스에서 삭제하는 대신, ‘삭제 여부’를 나타내는 플래그(예: deleted = true)를 설정하여 논리적으로 삭제 처리하는 방식을 Soft Delete라고 합니다. 이는 데이터 복구 용이성, 감사 로그 유지, 데이터 무결성 유지 등의 장점이 있습니다. Spring Data JPA에서는 @Where 어노테이션을 사용하여 Soft Delete를 쉽게 구현할 수 있습니다.
코드 설명
Soft Delete를 적용한 Member 엔티티입니다. @Where 어노테이션을 통해 ‘삭제되지 않은’ 데이터만 조회되도록 설정합니다.
// Member.java (Soft Delete 적용 예시)
package com.kwonputer.domain;
import jakarta.persistence.*;
import org.hibernate.annotations.Where;
@Entity
@Table(name = "members")
@Where(clause = "deleted = false") // deleted=false인 엔티티만 조회
public class Member extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, length = 50)
private String name;
@Column(nullable = false, unique = true, length = 100)
private String email;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id")
private Team team;
private boolean deleted = false; // 삭제 여부 플래그
protected Member() {}
public Member(String name, String email) {
this.name = name;
this.email = email;
}
// Getter
public Long getId() { return id; }
public String getName() { return name; }
public String getEmail() { return email; }
public Team getTeam() { return team; }
public boolean isDeleted() { return deleted; }
// Setter (연관관계 편의 메소드에서 사용)
public void setTeam(Team team) {
this.team = team;
}
// 논리적 삭제 메소드
public void delete() {
this.deleted = true;
}
// 논리적 복구 메소드
public void restore() {
this.deleted = false;
}
}
@Where(clause = "deleted = false")를 엔티티에 적용하면, 해당 엔티티를 조회하는 모든 JPQL 쿼리에 자동으로 WHERE deleted = false 조건이 추가됩니다. 실제 삭제는 member.delete() 메소드를 호출하여 deleted 필드를 true로 변경하는 방식으로 이루어집니다.