

요약
Prometheus & Grafana로 2026년 서버 모니터링 뚝딱!
내 서버의 상태를 한눈에! Prometheus와 Grafana를 활용하여 실시간 서버 모니터링 시스템을 구축하는 2026년 실전 가이드를 제공합니다.
핵심 키워드: Prometheus, Grafana, 서버 모니터링, 시각화, 인프라
이 글의 순서
1. 왜 지금, 서버 모니터링이 중요할까요?
2. Prometheus: 강력한 시계열 데이터베이스와 쿼리 언어
3. Grafana: 아름다운 대시보드와 유연한 알림
4. Docker Compose로 Prometheus & Grafana 연동 실전 가이드
5. 모니터링 시스템 구축 시 흔한 문제와 해결책
6. Prometheus & Grafana 활용 사례와 장단점
7. 자주 묻는 질문 (FAQ)
배경/도입
왜 지금, 서버 모니터링이 중요할까요?
2026년 현재, 우리가 사용하는 대부분의 서비스는 클라우드 환경 위에 복잡하게 얽힌 마이크로서비스 아키텍처로 구성되어 있습니다. 단 하나의 서버나 서비스에 문제가 발생해도 전체 시스템에 연쇄적인 장애를 일으킬 수 있죠. 이런 환경에서 실시간 서버 모니터링은 단순히 ‘문제가 생겼을 때 알려주는’ 것을 넘어, 문제를 사전에 감지하고 예방하는 핵심적인 역할을 수행합니다.
모니터링이 제대로 이루어지지 않는다면, 사용자들은 서비스 중단이나 성능 저하로 불편을 겪게 되고, 이는 곧 비즈니스 손실로 이어집니다. 또한, 개발팀은 문제의 원인을 찾기 위해 귀중한 시간을 허비하게 되죠. 따라서 효율적인 모니터링 시스템은 안정적인 서비스 운영을 위한 필수적인 요소이자, 개발 및 운영 효율성을 높이는 중요한 기반이 됩니다.
그중에서도 오픈소스 모니터링 솔루션인 Prometheus와 Grafana는 강력한 기능, 뛰어난 확장성, 활발한 커뮤니티 지원을 바탕으로 수많은 기업과 개발자들에게 사랑받고 있습니다. 이 두 도구는 각각 데이터 수집 및 저장, 그리고 데이터 시각화 및 알림이라는 역할을 분담하여 완벽한 모니터링 스택을 제공합니다.
핵심 포인트
2026년의 복잡한 IT 환경에서 실시간 서버 모니터링은 서비스 안정성, 성능 최적화, 그리고 비즈니스 연속성을 위한 필수 요소입니다. Prometheus와 Grafana는 이 요구사항을 충족시키는 가장 강력하고 유연한 오픈소스 조합입니다.
핵심 내용
Prometheus: 강력한 시계열 데이터베이스와 쿼리 언어
Prometheus는 SoundCloud에서 개발된 오픈소스 모니터링 시스템으로, 시계열 데이터베이스(Time Series Database, TSDB)를 기반으로 합니다. 간단히 말해, 시간의 흐름에 따라 변화하는 지표(메트릭)들을 효율적으로 저장하고, 강력한 쿼리 언어인 PromQL을 통해 이 데이터를 분석할 수 있도록 돕는 도구입니다.
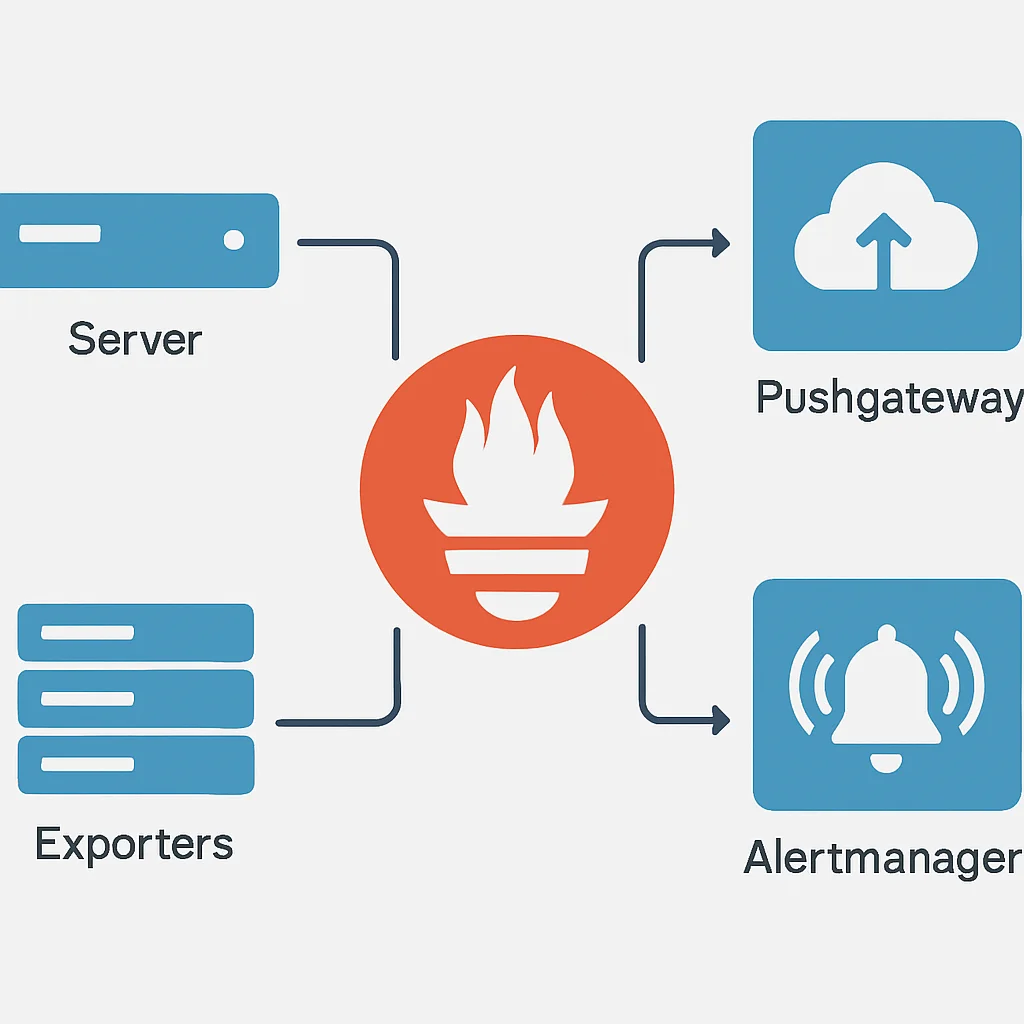
Prometheus의 아키텍처 및 동작 원리
Prometheus는 다른 모니터링 시스템과 차별화되는 ‘Pull’ 모델을 사용합니다. 이는 Prometheus 서버가 모니터링 대상(Target)에 직접 접속하여 메트릭을 가져오는 방식입니다. 각 모니터링 대상은 /metrics 엔드포인트를 통해 메트릭을 노출하며, Prometheus는 주기적으로 이 엔드포인트를 스크랩(Scrape)하여 데이터를 수집합니다.
주요 구성 요소는 다음과 같습니다:
Prometheus 핵심 구성 요소
Prometheus Server — 메트릭을 스크랩하고 저장하며, PromQL 쿼리를 처리합니다.
Exporters — 모니터링 대상으로부터 메트릭을 수집하여 Prometheus가 스크랩할 수 있는 형식으로 노출합니다. (예: Node Exporter, cAdvisor)
Pushgateway — 단기성 잡(Job)이나 배치 작업처럼 Prometheus가 직접 스크랩하기 어려운 메트릭을 푸시(Push) 방식으로 수집합니다.
Alertmanager — Prometheus 서버가 생성한 알림(Alert)을 받아 중복 제거, 그룹화, 라우팅하여 Slack, 이메일 등으로 전송합니다.
Service Discovery — 클라우드 환경에서 동적으로 생성/삭제되는 대상들을 자동으로 찾아내어 모니터링 대상에 추가합니다.
메트릭 유형과 Node Exporter 활용
Prometheus는 다양한 유형의 메트릭을 지원하여 시스템의 다양한 측면을 측정할 수 있도록 합니다. 대표적인 메트릭 유형은 다음과 같습니다:
- Counter (카운터): 단조 증가하는 값으로, 재시작 시 0으로 초기화됩니다. (예: HTTP 요청 수, 에러 발생 수)
- Gauge (게이지): 임의의 값으로 오르내릴 수 있습니다. (예: 현재 CPU 사용률, 메모리 사용량, 디스크 여유 공간)
- Histogram (히스토그램): 샘플을 버킷으로 나누어 분포를 관찰합니다. (예: 요청 처리 시간 분포)
- Summary (요약): 히스토그램과 유사하지만, 클라이언트 측에서 분위수(Quantile)를 계산합니다.
Node Exporter는 가장 흔하게 사용되는 Exporter 중 하나로, Linux/Unix 시스템의 하드웨어 및 OS 메트릭을 수집합니다. CPU 사용률, 메모리 사용량, 디스크 I/O, 네트워크 트래픽 등 서버의 기본적인 건강 상태를 파악하는 데 필수적인 정보를 제공합니다.
코드 설명
Node Exporter를 설치하고 실행하는 명령어입니다. 이 Exporter가 9100번 포트로 서버 메트릭을 노출하면 Prometheus가 이를 스크랩할 수 있습니다.
# Node Exporter 다운로드 및 압축 해제
wget https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-amd64.tar.gz
tar xvfz node_exporter-1.7.0.linux-amd64.tar.gz
# Node Exporter 실행 (백그라운드)
cd node_exporter-1.7.0.linux-amd64
nohup ./node_exporter &
# 9100번 포트로 메트릭 노출 확인
curl http://localhost:9100/metrics | head -n 10위 명령어를 실행하면 Node Exporter가 9100번 포트에서 메트릭을 노출하기 시작합니다. 이제 Prometheus 서버가 이 엔드포인트를 스크랩하도록 설정할 수 있습니다.
PromQL: 데이터 분석의 마법사
PromQL (Prometheus Query Language)은 Prometheus의 핵심 기능 중 하나로, 수집된 시계열 데이터를 실시간으로 쿼리하고 집계할 수 있는 강력한 언어입니다. PromQL을 사용하면 특정 시점의 값, 일정 기간 동안의 평균, 증가율, 비율 등을 계산하여 원하는 정보를 얻을 수 있습니다.
몇 가지 PromQL 예시를 살펴볼까요?
코드 설명
서버의 CPU 유휴(idle) 시간의 증가율을 계산하여 현재 CPU 사용률을 파악하는 PromQL 쿼리입니다. 1분(1m) 동안의 변화율을 측정합니다.
100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[1m])) * 100)이 쿼리는 node_cpu_seconds_total 메트릭에서 idle 모드의 CPU 초당 증가율을 계산한 후, 이를 백분율로 변환하여 CPU 사용률을 보여줍니다.
코드 설명
서버의 사용 가능한 메모리 비율을 계산하는 쿼리입니다. 전체 메모리에서 사용 가능한 메모리를 나누어 백분율로 표시합니다.
(node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100PromQL은 다양한 함수와 연산자를 제공하여 복잡한 데이터 분석을 가능하게 합니다. Grafana 대시보드에서 이러한 쿼리를 활용하여 시각화할 때 진정한 가치를 발휘합니다.
핵심 포인트
Prometheus는 ‘Pull’ 방식의 메트릭 수집과 강력한 PromQL을 통해 시계열 데이터를 효율적으로 관리합니다. Node Exporter를 활용하여 서버의 핵심 지표를 수집하고, PromQL로 원하는 데이터를 자유롭게 분석할 수 있습니다.
핵심 내용
Grafana: 아름다운 대시보드와 유연한 알림
Prometheus가 데이터를 수집하고 저장하는 ‘백엔드’ 역할을 한다면, Grafana는 이 데이터를 아름답고 직관적인 형태로 시각화하고, 필요한 경우 알림을 보내는 ‘프런트엔드’ 역할을 합니다. Grafana는 다양한 데이터 소스를 지원하지만, Prometheus와 함께 사용할 때 그 시너지가 극대화됩니다.
Grafana 대시보드 구축 및 시각화
Grafana의 가장 큰 장점은 사용자 친화적인 인터페이스를 통해 복잡한 데이터를 쉽게 시각화할 수 있다는 점입니다. 다양한 패널(Panel) 유형을 제공하여 그래프, 수치, 테이블, 게이지 등 원하는 형태로 데이터를 표현할 수 있습니다.
주요 패널 유형:
- Graph (그래프): 시계열 데이터를 시간에 따라 보여주는 가장 기본적인 패널입니다. CPU 사용률, 네트워크 트래픽 변화 등을 시각화하는 데 적합합니다.
- Stat (수치): 현재 값이나 특정 시점의 값을 크게 표시하여 한눈에 중요 지표를 파악할 수 있게 합니다.
- Table (테이블): 여러 메트릭의 데이터를 표 형태로 정리하여 보여줍니다.
- Gauge (게이지): 특정 지표의 현재 값을 게이지 형태로 표시하여 임계값 대비 상태를 직관적으로 보여줍니다. (예: 디스크 사용률)
Grafana는 또한 대시보드 템플릿 기능을 제공하여, 이미 잘 만들어진 대시보드를 쉽게 가져와 사용할 수 있습니다. 특히 Node Exporter를 위한 공식 대시보드(ID 1860)는 서버 모니터링의 시작점으로 매우 유용합니다.
Grafana Alerting: 문제 발생 시 즉시 알림
모니터링의 궁극적인 목표 중 하나는 문제가 발생했을 때 빠르게 인지하고 대응하는 것입니다. Grafana는 강력한 통합 알림(Unified Alerting) 시스템을 제공하여, Prometheus에서 수집된 데이터를 기반으로 특정 조건이 충족될 때 알림을 발생시킬 수 있습니다.
Grafana Alerting의 주요 특징은 다음과 같습니다:
- 데이터 소스 통합: Prometheus 뿐만 아니라 다양한 데이터 소스의 쿼리 결과를 기반으로 알림을 생성할 수 있습니다.
- 다양한 알림 채널: Slack, Email, PagerDuty, Webhook 등 다양한 알림 채널을 지원하여 팀이 선호하는 방식으로 알림을 받을 수 있습니다.
- 유연한 조건 설정: 임계값 초과, 특정 기간 동안의 평균 변화 등 복잡한 조건도 PromQL을 활용하여 설정할 수 있습니다.
예를 들어, 서버의 CPU 사용률이 5분 동안 90%를 초과하면 Slack으로 알림을 보내도록 설정할 수 있습니다. 이는 장애가 발생하기 전에 미리 경고를 받아 선제적으로 대응할 수 있게 해줍니다.
템플릿 변수를 활용한 다이내믹 대시보드
여러 대의 서버를 모니터링할 때, 각 서버마다 별도의 대시보드를 만드는 것은 비효율적입니다. Grafana의 템플릿 변수(Templating Variables) 기능은 이러한 문제를 해결해줍니다. 템플릿 변수를 사용하면 드롭다운 메뉴를 통해 서버 인스턴스나 서비스 등을 선택하여, 하나의 대시보드로 여러 대의 서버 데이터를 유연하게 조회할 수 있습니다.
예를 들어, Prometheus에서 수집된 instance 레이블을 기반으로 $instance 변수를 생성하면, 대시보드 상단에 서버 목록이 표시되고 사용자가 선택하는 서버의 데이터만 대시보드에 반영됩니다. 이는 대규모 인프라를 모니터링할 때 관리 효율성을 극대화하는 중요한 기능입니다.
핵심 포인트
Grafana는 직관적인 대시보드 구축을 통해 Prometheus 데이터를 시각화하고, 강력한 알림 시스템으로 문제 발생 시 즉각적인 대응을 가능하게 합니다. 템플릿 변수는 대규모 인프라 모니터링의 효율성을 크게 높여줍니다.
실전 적용
Docker Compose로 Prometheus & Grafana 연동 실전 가이드
이제 Prometheus와 Grafana를 직접 설치하고 연동하여 서버 모니터링 시스템을 구축해봅시다. 가장 빠르고 간편한 방법은 Docker Compose를 사용하는 것입니다. 이 가이드에서는 Prometheus 서버, Node Exporter, 그리고 Grafana를 Docker 컨테이너로 실행하고 연동하는 방법을 설명합니다.
단계 1: 디렉터리 구조 설정 및 설정 파일 생성
먼저 프로젝트 디렉터리를 만들고, Prometheus와 Grafana의 설정 파일들을 저장할 디렉터리를 구성합니다.
코드 설명
Prometheus와 Grafana 설정을 위한 디렉터리를 생성하고, Prometheus의 기본 설정 파일인 prometheus.yml을 작성합니다. 이 파일은 Prometheus가 어떤 대상을 모니터링할지 정의합니다.
# 디렉터리 생성
mkdir monitoring
cd monitoring
mkdir prometheus
mkdir grafana
# prometheus/prometheus.yml 파일 생성 및 내용 추가
cat <<EOF > prometheus/prometheus.yml
global:
scrape_interval: 15s # 15초마다 메트릭 스크랩
scrape_configs:
- job_name: 'prometheus' # Prometheus 자체 모니터링
static_configs:
- targets: ['localhost:9090']
- job_name: 'node_exporter' # Node Exporter 모니터링
static_configs:
- targets: ['node_exporter:9100'] # Docker Compose 서비스 이름으로 접근
EOF위 설정에서 targets: [‘node_exporter:9100’]는 Docker Compose 네트워크 내에서 node_exporter라는 서비스 이름으로 Node Exporter 컨테이너에 접근하겠다는 의미입니다.
단계 2: Docker Compose 파일 작성
Prometheus, Grafana, Node Exporter 세 가지 서비스를 한 번에 실행하기 위한 docker-compose.yml 파일을 작성합니다.
코드 설명
Prometheus, Grafana, Node Exporter 컨테이너를 정의하는 docker-compose.yml 파일입니다. 각 서비스의 이미지, 포트 매핑, 볼륨 마운트 등을 설정합니다.
# docker-compose.yml 파일 생성 및 내용 추가
cat <<EOF > docker-compose.yml
version: '3.8'
services:
prometheus:
image: prom/prometheus:v2.49.1
container_name: prometheus
ports:
- "9090:9090"
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus # 데이터 영속성 확보
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
restart: unless-stopped
node_exporter:
image: prom/node-exporter:v1.7.0
container_name: node_exporter
ports:
- "9100:9100"
command:
- '--path.rootfs=/host/rootfs' # 호스트 루트 파일 시스템 모니터링
volumes:
- /:/host/rootfs:ro,rslave # 호스트의 파일 시스템을 읽기 전용으로 마운트
restart: unless-stopped
grafana:
image: grafana/grafana:10.3.3
container_name: grafana
ports:
- "3000:3000"
volumes:
- grafana_data:/var/lib/grafana # 데이터 영속성 확보
environment:
- GF_SECURITY_ADMIN_USER=admin
- GF_SECURITY_ADMIN_PASSWORD=admin # 초기 관리자 계정 설정 (실제 사용 시 변경 권장)
restart: unless-stopped
volumes:
prometheus_data:
grafana_data:
EOF이 docker-compose.yml 파일은 다음을 설정합니다:
- prometheus: Prometheus 서버 컨테이너. prometheus.yml 파일을 마운트하고, 9090 포트를 외부에 노출합니다.
- node_exporter: Node Exporter 컨테이너. 호스트의 루트 파일 시스템을 마운트하여 호스트 서버의 지표를 수집하고, 9100 포트를 외부에 노출합니다.
- grafana: Grafana 컨테이너. 3000 포트를 외부에 노출하고, 초기 관리자 계정을 설정합니다 (admin/admin).
단계 3: 서비스 실행 및 확인
이제 docker-compose up 명령어를 사용하여 모든 서비스를 한 번에 실행합니다.
코드 설명
작성된 docker-compose.yml 파일을 기반으로 모든 서비스를 백그라운드에서 실행하는 명령어입니다.
docker-compose up -d서비스가 성공적으로 실행되면 다음 주소로 접속하여 각 웹 UI를 확인할 수 있습니다:
- Prometheus UI: http://localhost:9090
- Grafana UI: http://localhost:3000 (초기 계정: admin/admin)
- Node Exporter Metrics: http://localhost:9100/metrics
단계 4: Grafana에서 Prometheus 데이터 소스 추가
Grafana 대시보드를 만들기 전에 Prometheus를 데이터 소스로 추가해야 합니다.
2
데이터 소스 추가
좌측 메뉴에서 톱니바퀴 아이콘 > Data sources > Add data source를 클릭합니다. 유형으로 Prometheus를 선택합니다.
3
Prometheus 설정
URL 필드에 http://prometheus:9090을 입력합니다. Grafana 컨테이너가 Docker Compose 네트워크 내에서 Prometheus 컨테이너에 접근하므로 서비스 이름으로 지정합니다. Save & Test 버튼을 클릭하여 연결을 확인합니다.

단계 5: Node Exporter 대시보드 가져오기
Grafana Labs에서 제공하는 Node Exporter Full 대시보드를 가져와 서버 상태를 한눈에 확인해봅시다.
1
대시보드 가져오기
좌측 메뉴에서 대시보드 아이콘 > Import를 클릭합니다.
2
대시보드 ID 입력
Grafana.com Dashboard에 1860을 입력하고 Load를 클릭합니다. 이는 Node Exporter Full 대시보드의 ID입니다.
3
설정 및 저장
Prometheus 데이터 소스를 선택하고 Import를 클릭합니다. 이제 Node Exporter Full 대시보드를 통해 호스트 서버의 CPU, 메모리, 디스크, 네트워크 사용량 등을 실시간으로 확인할 수 있습니다.
핵심 포인트
Docker Compose를 활용하면 Prometheus, Node Exporter, Grafana를 빠르고 쉽게 구축할 수 있습니다. Grafana에 Prometheus 데이터 소스를 연결하고, 공식 Node Exporter 대시보드를 가져오는 것만으로도 강력한 서버 모니터링 시스템을 즉시 가동할 수 있습니다.
문제 해결
모니터링 시스템 구축 시 흔한 문제와 해결책
Prometheus와 Grafana를 이용한 모니터링 시스템 구축은 비교적 쉽지만, 실제 운영 환경에서는 몇 가지 흔한 문제에 직면할 수 있습니다. 이러한 문제들을 미리 파악하고 해결책을 알아두면 더욱 안정적인 시스템을 운영할 수 있습니다.
문제 01
데이터 유실 또는 수집 실패
Prometheus 대시보드나 Grafana에서 일부 메트릭이 누락되거나 데이터가 제대로 업데이트되지 않는 문제가 발생할 수 있습니다.
해결 — 원인 파악 및 설정 검토
1. 방화벽 확인: Prometheus 서버에서 Exporter가 실행되는 서버의 9100번 포트(또는 다른 포트)로의 접근이 방화벽에 의해 차단되지 않았는지 확인합니다. ufw나 firewalld 설정을 검토하세요.
2. Exporter 상태 확인: Node Exporter와 같은 Exporter가 정상적으로 실행 중인지 확인합니다. systemctl status node_exporter 또는 docker logs node_exporter 명령어를 사용합니다.
3. Prometheus 설정 확인: prometheus.yml 파일의 scrape_configs에 올바른 IP 주소 또는 서비스 이름, 포트가 지정되었는지 확인합니다. Prometheus UI (/targets)에서 스크랩 상태를 확인할 수 있습니다.
문제 02
PromQL 쿼리 성능 저하 및 높은 카디널리티
복잡한 PromQL 쿼리가 느리게 실행되거나, Prometheus 서버의 리소스 사용량이 과도하게 높아지는 현상이 발생할 수 있습니다. 이는 주로 높은 카디널리티(Cardinality) 문제와 관련이 있습니다.
해결 — 쿼리 최적화 및 메트릭 관리
1. 불필요한 레이블 제거: 카디널리티는 메트릭과 레이블 조합의 수에 비례합니다. 고유한 값을 많이 가지는 레이블(예: 사용자 ID, 세션 ID)은 가급적 피하거나, relabel_configs를 사용하여 제거하거나 일반화합니다.
2. 쿼리 범위 축소: sum by(), avg by() 등의 집계 함수를 사용하여 쿼리 대상을 줄입니다. 특정 인스턴스나 잡(job)으로 필터링하여 쿼리 범위를 좁히는 것도 도움이 됩니다.
3. Recording Rules 활용: 자주 사용하는 복잡한 쿼리 결과를 미리 계산하여 새로운 메트릭으로 저장(Recording Rule)해두면, 대시보드 로딩 시간을 단축하고 쿼리 성능을 향상시킬 수 있습니다.
4. 장기 저장 솔루션 고려: 장기간의 데이터를 저장해야 한다면 Thanos, Mimir, VictoriaMetrics와 같은 확장 가능한 시계열 데이터베이스 솔루션을 Prometheus와 함께 사용하는 것을 고려할 수 있습니다.
문제 03
알림 과부하 (Alert Fatigue)
너무 많은 알림이 발생하거나 중요하지 않은 알림이 자주 울리면, 팀원들이 알림에 대한 경각심을 잃고 실제 중요한 알림을 놓칠 수 있습니다. 이를 ‘알림 과부하’라고 합니다.
해결 — Alertmanager 설정 및 알림 정책 개선
1. Alertmanager 그룹화 및 중복 제거: Alertmanager의 group_by, repeat_interval 설정을 통해 유사한 알림을 그룹화하고, 일정 시간 동안은 중복 알림을 보내지 않도록 설정합니다.
2. 알림 임계값 조정: 너무 민감하게 설정된 알림 임계값을 현실적으로 조정합니다. 짧은 시간 동안 발생하는 일시적인 스파이크는 알림으로 보내지 않도록 FOR 절을 사용하여 일정 시간 동안 지속될 때만 알림이 발생하도록 설정합니다.
3. Silence (알림 무음): 계획된 유지보수 작업이나 일시적인 문제로 인해 알림이 쏟아질 것으로 예상될 때, Alertmanager에서 해당 알림을 일시적으로 무음 처리(Silence)할 수 있습니다.
4. 라우팅 정책: 중요도에 따라 알림 채널을 다르게 설정합니다. 치명적인 알림은 PagerDuty 같은 즉각적인 응답이 필요한 채널로, 경고성 알림은 Slack 채널로 보내는 식입니다.
핵심 포인트
모니터링 시스템 운영 시 데이터 유실, 쿼리 성능 저하, 알림 과부하는 흔히 발생하는 문제입니다. 방화벽, Exporter 상태, Prometheus 설정 확인을 통해 데이터 수집 문제를 해결하고, 레이블 최적화와 Recording Rules로 쿼리 성능을 개선하며, Alertmanager의 그룹화 및 라우팅 기능을 활용하여 알림 과부하를 줄일 수 있습니다.
실전 적용
Prometheus & Grafana 활용 사례와 장단점
Prometheus와 Grafana는 다양한 IT 환경에서 강력한 모니터링 솔루션으로 활용될 수 있습니다. 실제 서비스에서 어떻게 활용되는지, 그리고 이 조합이 가지는 장단점은 무엇인지 살펴보겠습니다.
주요 활용 사례
Prometheus와 Grafana는 단순히 서버 CPU/메모리 모니터링을 넘어, 애플리케이션, 데이터베이스, 네트워크 등 IT 인프라 전반에 걸쳐 폭넓게 활용됩니다.
클라우드 및 컨테이너 환경 모니터링
Kubernetes, Docker Swarm과 같은 컨테이너 오케스트레이션 환경에서 cAdvisor, Kube-state-metrics 등의 Exporter를 통해 컨테이너 및 클러스터 상태를 모니터링합니다. Grafana 대시보드를 통해 노드별, 파드별 리소스 사용량, 네트워크 트래픽 등을 시각화하여 컨테이너 환경의 복잡성을 관리합니다.
애플리케이션 성능 모니터링 (APM)
Java, Python, Go 등 다양한 언어의 클라이언트 라이브러리를 사용하여 애플리케이션 내부의 메트릭(요청 처리 시간, 에러율, 동시 사용자 수 등)을 노출하고 Prometheus로 수집합니다. Grafana 대시보드에서 서비스의 건강 상태와 성능 병목 지점을 실시간으로 파악하여 사용자 경험을 최적화합니다.
데이터베이스 및 미들웨어 모니터링
MySQL Exporter, Redis Exporter, Kafka Exporter 등을 활용하여 데이터베이스의 쿼리 지연 시간, 연결 수, 미들웨어의 메시지 처리량 등을 모니터링합니다. 이를 통해 데이터베이스 성능 문제를 사전에 감지하고, 미들웨어의 안정성을 확보합니다.

장점과 단점
Prometheus와 Grafana 조합은 많은 장점을 가지고 있지만, 몇 가지 고려해야 할 단점도 존재합니다.
장점
✓ 오픈소스 및 활발한 커뮤니티: 무료로 사용 가능하며, 방대한 문서와 커뮤니티 지원을 받을 수 있습니다.
✓ 강력한 쿼리 언어 (PromQL): 복잡한 데이터 분석과 집계를 통해 심층적인 인사이트를 얻을 수 있습니다.
✓ 뛰어난 시각화 (Grafana): 직관적이고 커스터마이징 가능한 대시보드를 통해 데이터를 효과적으로 전달합니다.
✓ 다양한 Exporter 및 통합: 수많은 Exporter가 존재하여 거의 모든 종류의 시스템과 애플리케이션을 모니터링할 수 있습니다.
✓ 확장성: Alertmanager를 통한 유연한 알림 관리와 장기 저장 솔루션(Thanos, Mimir)과의 연동으로 확장 가능합니다.
단점
✗ 초기 설정 및 학습 곡선: 처음 접하는 사용자에게는 PromQL 학습과 설정 파일 작성 등 초기 설정이 다소 복잡하게 느껴질 수 있습니다.
✗ 장기 데이터 저장의 복잡성: Prometheus 자체는 단일 노드에서 단기 데이터를 효율적으로 저장하지만, 수많은 메트릭의 장기 저장을 위해서는 Thanos나 Mimir와 같은 추가 솔루션이 필요합니다.
✗ Pull 모델의 한계: 방화벽 뒤에 있는 서버나 임시로 생성되는 작업(Short-lived job)의 경우, Pushgateway를 사용해야 하는 등 Pull 모델의 제약이 있습니다.
핵심 포인트
Prometheus와 Grafana는 클라우드, 컨테이너, 애플리케이션, 데이터베이스 등 다양한 환경에서 효과적인 모니터링을 제공합니다. 오픈소스의 장점과 강력한 기능을 갖추고 있지만, 초기 학습과 장기 저장, Pull 모델의 한계를 고려하여 솔루션을 선택해야 합니다.
자주 묻는 질문 (FAQ)
Q. Prometheus와 Grafana를 사용하는 가장 큰 장점은 무엇인가요?
A. 가장 큰 장점은 오픈소스이면서도 강력한 기능과 확장성을 제공한다는 점입니다. Prometheus의 강력한 PromQL과 Grafana의 유연한 시각화, 그리고 활발한 커뮤니티 지원을 통해 비용 효율적으로 고성능 모니터링 시스템을 구축할 수 있습니다.